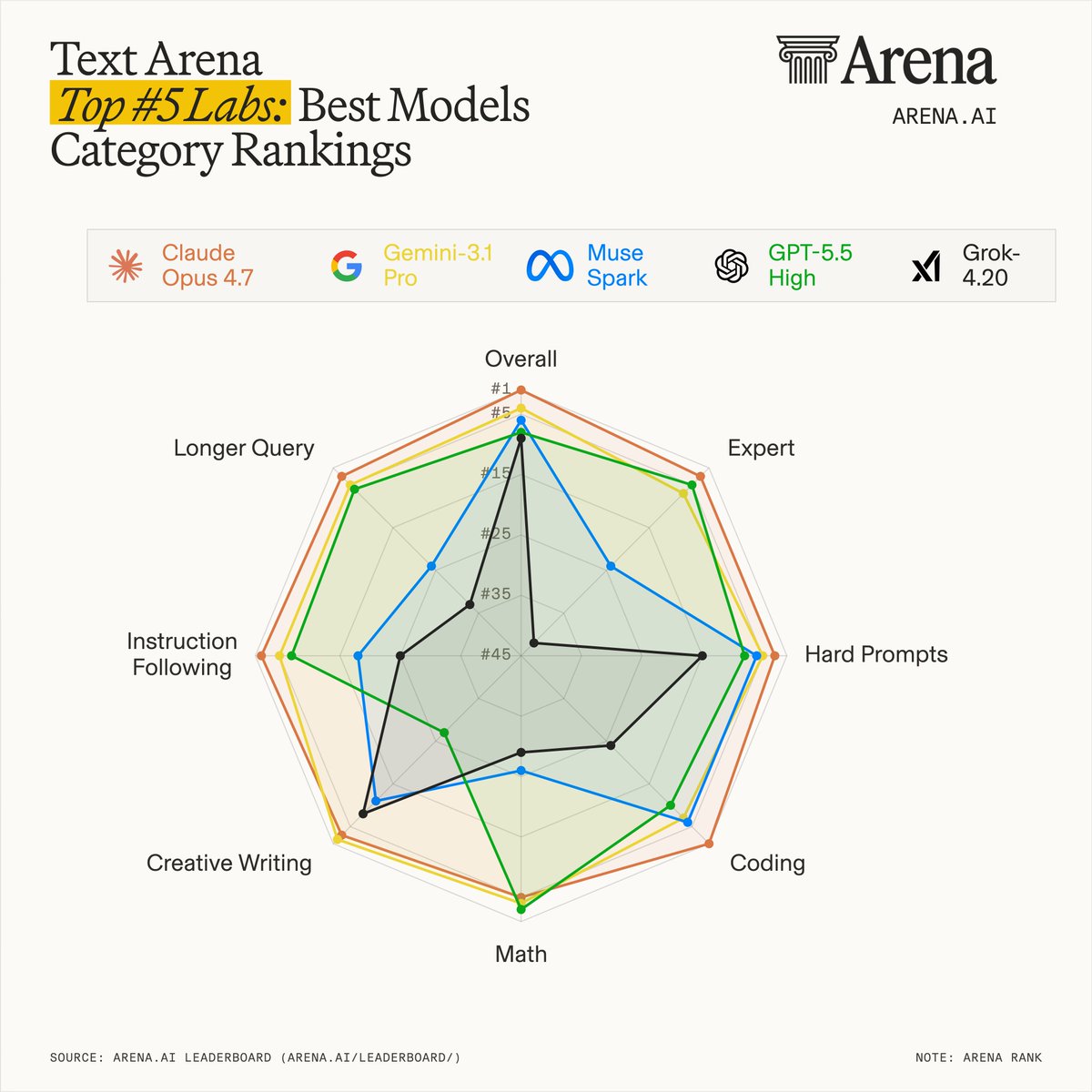
Claude Opus 4.8 debuts on Agent Arena tied #1 with GPT 5.5 (High) for Thinking & ranked #8 for Non-T...
lmarena.ai(@lmarena_ai)267 字 (约 2 分钟)
85
Claude Opus 4.8 在 Agent Arena 上与 GPT 5.5 并列第一,但在非思考任务中排名第八。
入选理由:Claude Opus 4.8 在开启思考模式时表现优于 4.7 版本。
精选推文#Claude#GPT#Agent Arena#模型评估英文