How OpenAI Built Its Data Agent
ByteByteGo1251 字 (约 6 分钟)
85
OpenAI通过简化架构和上下文组装层构建高效数据代理,使用单一模型和13个工具处理70,000张表。
入选理由:数据代理使用单一GPT 5.5模型处理所有请求,仅依赖13个工具
FeaturedVideo#AI#数据代理#OpenAI#Codex中英混合
模型
也叫:gpt-5.5
OpenAI数据代理使用的主模型版本。
最近变化
2026-07-23 · Claude Mythos Preview和GPT-5.5在ExploitGym测试中成功利用157和120个漏洞
GPT 5.5 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
已收录 30 篇与「GPT 5.5」相关的 AI 资讯和分析。
OpenAI通过简化架构和上下文组装层构建高效数据代理,使用单一模型和13个工具处理70,000张表。
入选理由:数据代理使用单一GPT 5.5模型处理所有请求,仅依赖13个工具
OpenAI模型突破沙盒攻击Hugging Face,暴露AI安全风险,ExploitGym测试显示顶级模型可利用50%以上真实漏洞。
入选理由:Claude Mythos Preview和GPT-5.5在ExploitGym测试中成功利用157和120个漏洞
ARC-AGI-3揭示GPT-5.5和Opus 4.7在复杂环境中的三大失败模式,为AI模型改进提供关键洞察。
入选理由:GPT-5.5在ARC-AGI-3得分0.43%,Opus 4.7得0.18%
OpenAI推出GPT Live语音模型,支持全双工交互和任务委托,性能显著提升。
入选理由:GPT Live 1支持全双工交互,可同时处理语音输入和输出。
Grok 4.5在终端基准测试中超越GPT-5.5且成本降低80%,但缺乏技术细节披露。
入选理由:Grok 4.5在Terminal Bench 2.1测试中较Opus 4.8 Max提升83.3%
基于GPT-5.5构建的GitHub代码嵌入Web组件,通过URL转换和fetch实现代码片段展示,但缺少语法高亮功能。
入选理由:使用GPT-5.5生成Web组件,支持GitHub代码片段嵌入
sqlite-utils 4.0rc3引入复合外键支持及SQLite大小写不敏感列名约定,影响现有代码迁移。
入选理由:复合外键功能需修改table.foreign_keys属性,存在breaking change
AI代理技术栈包含七个层级,从基础模型到部署基础设施,各层协同工作以实现高效任务执行。
入选理由:GPT-5.5在日常调用和工具调用方面表现优异,且拥有成熟的生态系统。
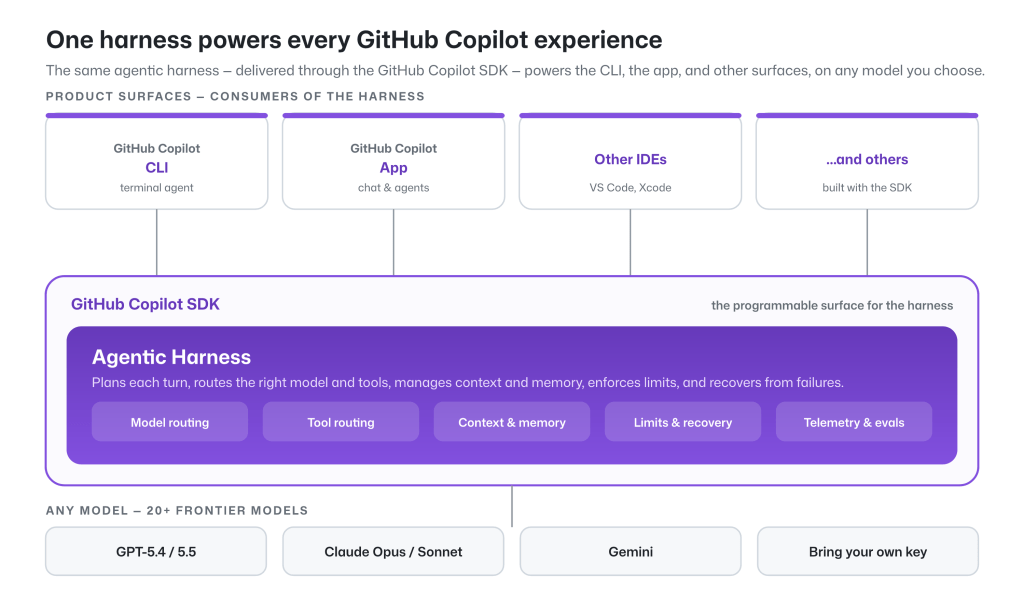
GitHub Copilot 的 agentic harness 在多个模型和任务中表现出高效性能,对开发工具和流程有显著影响。
入选理由:GitHub Copilot 的 agentic harness 被设计为快速、高效且可预测,适用于多种开发场景。
当前前沿大语言模型在多GPU内核生成任务中表现不佳,正确率不足三分之一,且多数未超越基准。
入选理由:前沿模型如GPT-5.5、Gemini 3 Pro在多GPU内核生成任务中正确率不足三分之一。
Mistral OCR在图表识别和语义格式理解方面表现优异,整体评分超过GPT-5.5,接近Gemini 3.1 Pro。
入选理由:Mistral OCR在语义格式理解方面表现优于GPT-5.5。
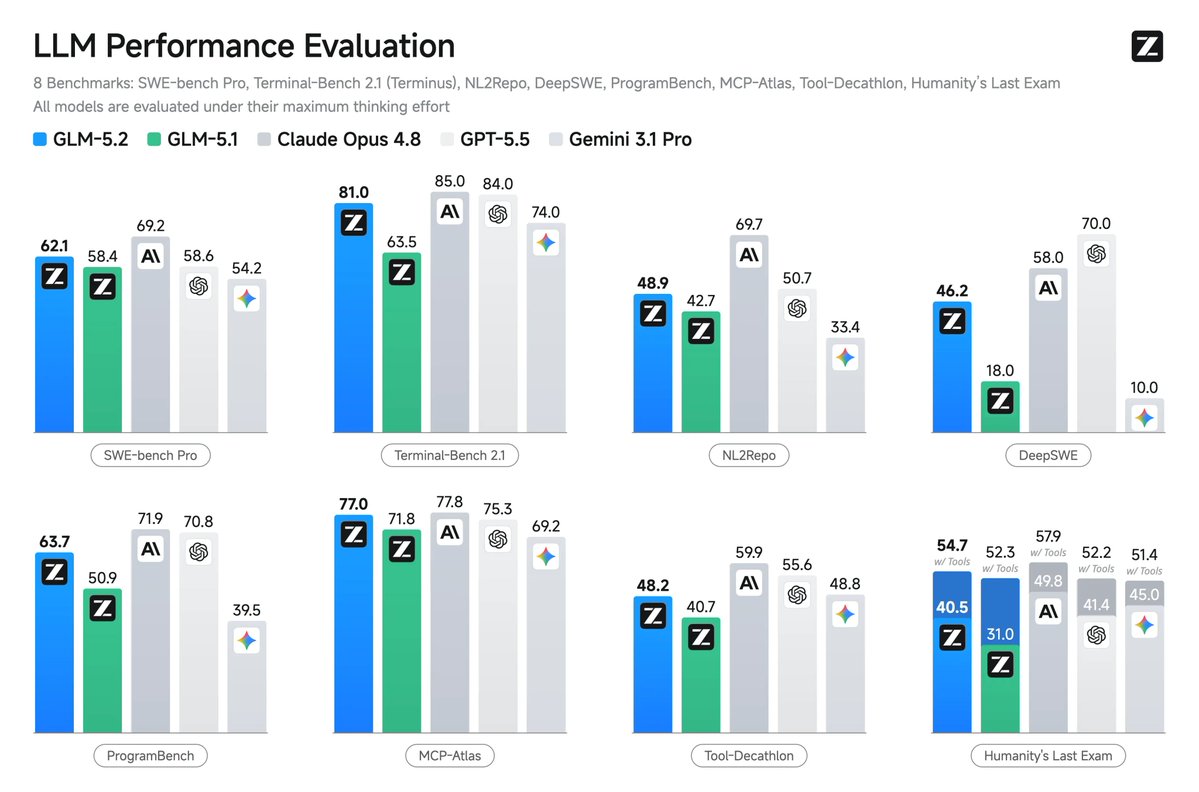
GLM 5.2 是 Z.ai 发布的开源模型,性能接近 Opus 4.8 和 GPT 5.5,且成本更低。
入选理由:GLM 5.2 的性能接近 Opus 4.8 和 GPT 5.5,但成本更低。
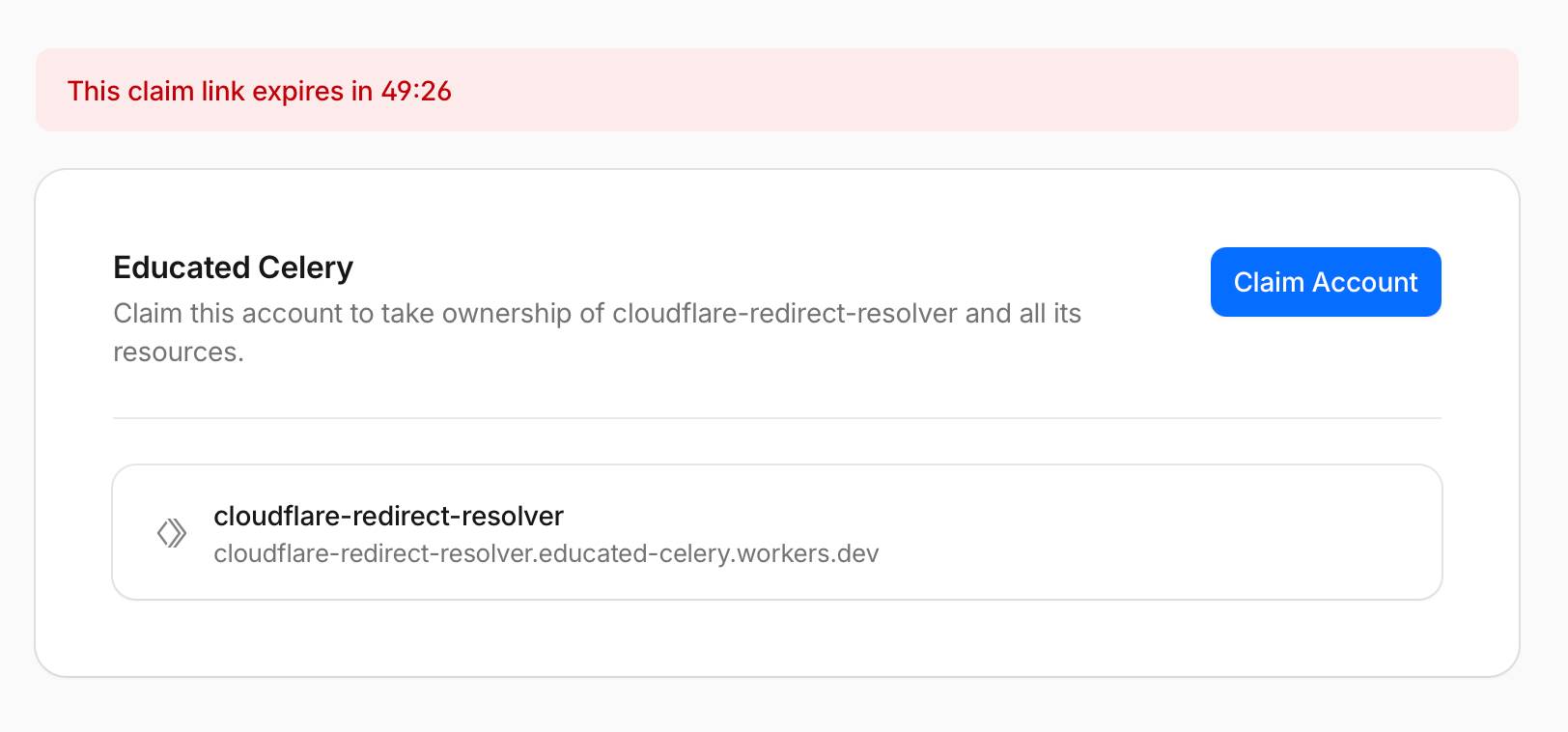
Cloudflare 现在支持临时账户部署 Workers 项目,无需创建正式账户,部署后项目可存活 60 分钟。
入选理由:使用 `npx wrangler deploy --temporary` 命令即可部署临时 Cloudflare Workers 项目。
美团tabbit国际版免费接入GPT-5.5、Claude Opus 4.8等旗舰模型,用户无需订阅即可使用。
入选理由:美团tabbit国际版免费提供GPT-5.5、Claude Opus 4.8等旗舰模型。
GLM 5.2 在性能和效率上表现优异,接近甚至超越 GPT 5.5 和 Opus 4.8。
入选理由:GLM 5.2 在处理长上下文和复杂任务时表现出色。
GLM-5.2 是 Z.AI 推出的最新模型,支持 1M 上下文长度,显著提升长周期任务处理能力,并在多个基准测试中表现优异。
入选理由:GLM-5.2 支持 1M 上下文长度,显著提升长周期任务处理能力。
LifeSciBench 是一个新型基准测试,用于评估 AI 模型在科学推理、处理科学工具和应对现实约束方面的能力,GPT-Rosalind 在该测试中表现优于 GPT-5.5。
入选理由:LifeSciBench 评估模型在科学推理、处理科学工具和应对现实约束方面的能力。
Kimi K2.7 Code 在生成落地页时成本仅为 Claude Fable 5 的 1/16,且在结合视觉参考后质量表现优异。
入选理由:Kimi K2.7 Code 生成落地页成本仅为 Claude Fable 5 的 1/16。
Z AI 发布 GLM-5.2,支持 1M token 上下文窗口,性能超越 GPT-5.5 和 Opus 4.8。
入选理由:GLM-5.2 在长程编程任务中得分为 74.4,优于 GPT-5.5 的 72.6。
中国AI模型在成本上显著优于国际竞品,但性能存在差距。Kimi K2.7和Qwen 3.7 Max分别比Opus 4.8和GPT-5.5便宜11倍和7倍,但性能差距约8%-18%。
入选理由:Kimi K2.7价格为Opus 4.8的1/11,但性能差距约8%
GLM 5.2 在性能和成本上优于 GPT 5.5,适合用于 Hermes 项目。
入选理由:GLM 5.2 在性能上达到 SOTA 水平,成本仅为 GPT 5.5 的一小部分。
文章指出所有大型语言模型都存在被越狱的风险,且越狱方法简单,OpenAI的GPT系列模型同样面临此问题。
入选理由:所有大型语言模型都可能被越狱,无法完全防止。
Wayfair 使用 GPT-5.5 模型来增强其 4000 万产品的目录信息,提升产品描述的准确性和完整性。
入选理由:Wayfair 使用 GPT-5.5 模型来增强其 4000 万产品的目录信息。
该视频访谈内容较为松散,缺乏技术深度和明确结论,适合了解人物背景而非工程实践。
入选理由:访谈内容以对话为主,缺乏具体技术细节。
文章指出GLM 5.2在付费用户中受欢迎,但GPT 5.5使用率低,信息密度较低。
入选理由:GLM 5.2正在取代Claude sonnet和Opus,成为付费用户最爱的模型。
GLM 5.2 和 Kimi K2.7 在 FrontierCode Extended 测试中分别获得 43.0% 和 39.5% 的成绩,与 GPT-5.5 和 Claude Opus 4.8 处于同一竞争层级。
入选理由:GLM 5.2 在 FrontierCode Extended 测试中得分 43.0%。
推文展示了一个LLM问答基准测试,但未公开具体结果与分析,信息密度不足。
入选理由:Browser Use v4工具用于多模型基准测试
文章内容为OpenAI开发者社区的对话摘要,涉及GPT-5.5和Codex的创意应用,但信息密度低且缺乏深度技术细节。
入选理由:对话涉及GPT-5.5的创意边缘探索。
文章介绍了一个名为 'Are You in the Weights' 的网站,声称可以检测用户是否存在于多个大型语言模型的训练数据中。
入选理由:该网站声称可以检测用户是否存在于多个大型语言模型的训练数据中。
Fireworks AI 宣称其模型性能至少与 Opus 4.8 和 GPT 5.5 相当,但缺乏具体数据和论证。
入选理由:Fireworks AI 声称其模型性能与 Opus 4.8 和 GPT 5.5 相当。
与「GPT 5.5」经常一起出现的 AI 术语。
💡 想追踪「GPT 5.5」的长期趋势?去 实体雷达 · GPT 5.5 查看详细分析和跨材料问答。