Grok 4.5 Just Shocked The AI Community - SpaceXAI Grok 4.5
TheAIGRID4858 字 (约 20 分钟)
85
Grok 4.5在终端基准测试中超越GPT-5.5且成本降低80%,但缺乏技术细节披露。
入选理由:Grok 4.5在Terminal Bench 2.1测试中较Opus 4.8 Max提升83.3%
FeaturedVideo#AI模型#基准测试#成本效益#SpaceXAI#Grok英文
概念
别名:Terminal Bench 2.1
评估终端代理能力的基准测试
已跟踪 7 条高相关材料
最近变化
2026-07-09 · Grok 4.5在Terminal Bench 2.1测试中较Opus 4.8 Max提升83.3%
为什么值得关注
Terminal Bench 2.1 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
Grok 4.5 Just Shocked The AI Community - SpaceXAI Grok 4.5
TheAIGRID · 8.5 分
Grok 4.5在终端基准测试中超越GPT-5.5且成本降低80%,但缺乏技术细节披露。
OpenAI GPT-5.6 系列模型预览发布 好消息是 Sol 很强!坏消息是目前只能小范围预览,要配合美国政府监管审查!A 厂求仁得仁,转身拖 O 厂下水,原来 A 厂的 AI 宪法,就是:都别...
meng shao(@shao__meng) · 8.5 分
OpenAI 发布 GPT-5.6 系列模型,包含 Sol、Terra 和 Luna 三款模型,强调性能与效率的平衡,并引入多 Agent 协作机制。
刚刚,豆包2.1发布!Agent自己跑18个小时搞定芯片设计代码
量子位 · 8.5 分
豆包2.1 Pro模型在芯片设计、代码生成等任务中表现优异,性能接近甚至超越国际头部模型,且价格仅为国外同类产品的四分之一。
已收录 7 条与 Terminal Bench 2.1 相关的内容,按评分排序。
Grok 4.5在终端基准测试中超越GPT-5.5且成本降低80%,但缺乏技术细节披露。
入选理由:Grok 4.5在Terminal Bench 2.1测试中较Opus 4.8 Max提升83.3%
OpenAI 发布 GPT-5.6 系列模型,包含 Sol、Terra 和 Luna 三款模型,强调性能与效率的平衡,并引入多 Agent 协作机制。
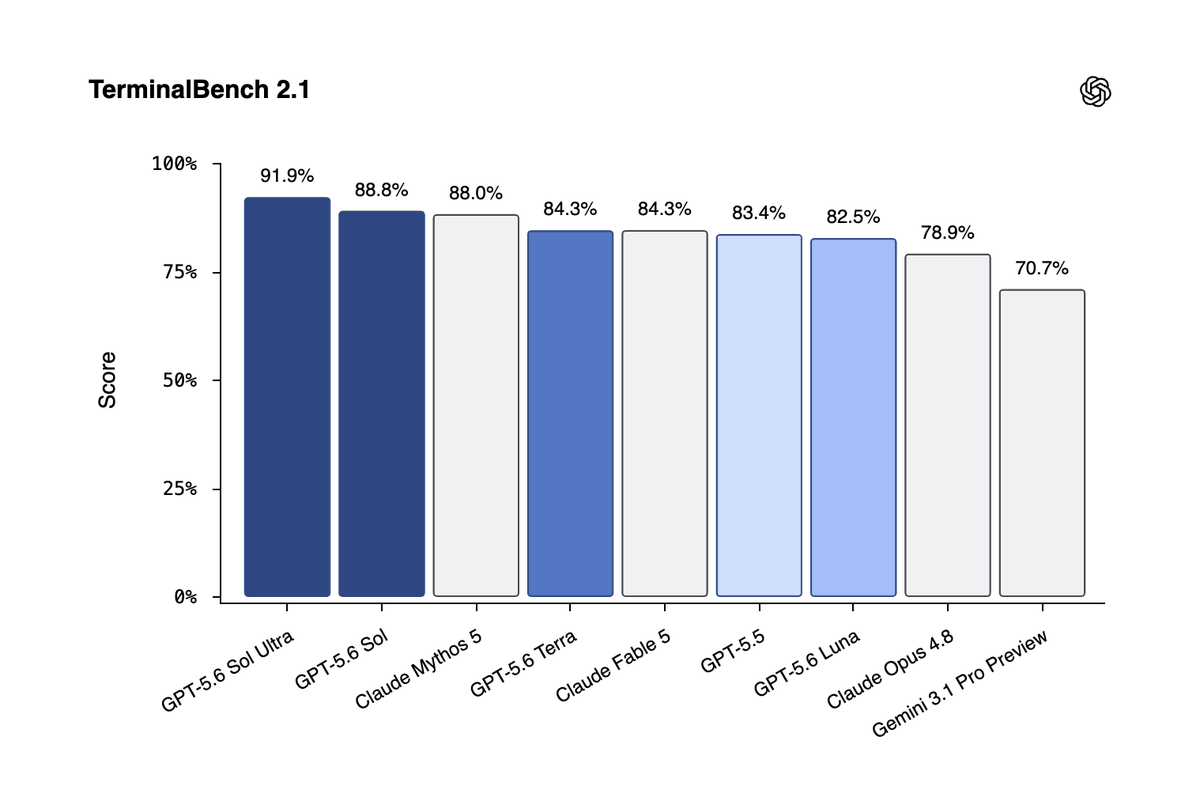
入选理由:GPT-5.6 Sol 在 Terminal-Bench 2.1 基准测试中达到 91.9% 的性能。
Sakana Fugu 是一种基于多模型协调的系统,宣称能媲美 Fable 和 Mythos,但实际性能略逊,且其本质是模型路由而非单一模型。
入选理由:Sakana Fugu 是一种多模型协调系统,而非单一模型。
豆包2.1 Pro模型在芯片设计、代码生成等任务中表现优异,性能接近甚至超越国际头部模型,且价格仅为国外同类产品的四分之一。
入选理由:豆包2.1 Pro在Terminal Bench 2.1测试中与Claude Opus 4.7持平,在SciCode测试中甚至超越Opus 4.7和GPT-5.5。
MiniMax introduces M3, the first open-weight model combining coding, agentic, and long-context capabilities, achieving 59%+ on benchmarks like SWE-Bench Pro with 1M context support, advancing open-source LLMs toward multi-capability frontiers.
入选理由:MiniMax M3 在 SWE-Bench Pro 基准测试中取得 59.0% 正确率,领先多数开源模型。
GPT-5.6 仅向 20 家政府审批合作伙伴开放,普通用户暂无法使用。
入选理由:GPT-5.6 仅向约 20 家政府审批合作伙伴开放,普通开发者和用户无法使用。
GPT-5.6 Sol在Terminal-Bench 2.1测试中表现优异,但信息量不足,缺乏技术细节。
入选理由:GPT-5.6 Sol在Terminal-Bench 2.1测试中达到新高度。