When AI Builds Itself: Our Progress Toward Recursive Self-Improvement
Hacker News Best5602 字 (约 23 分钟)
92
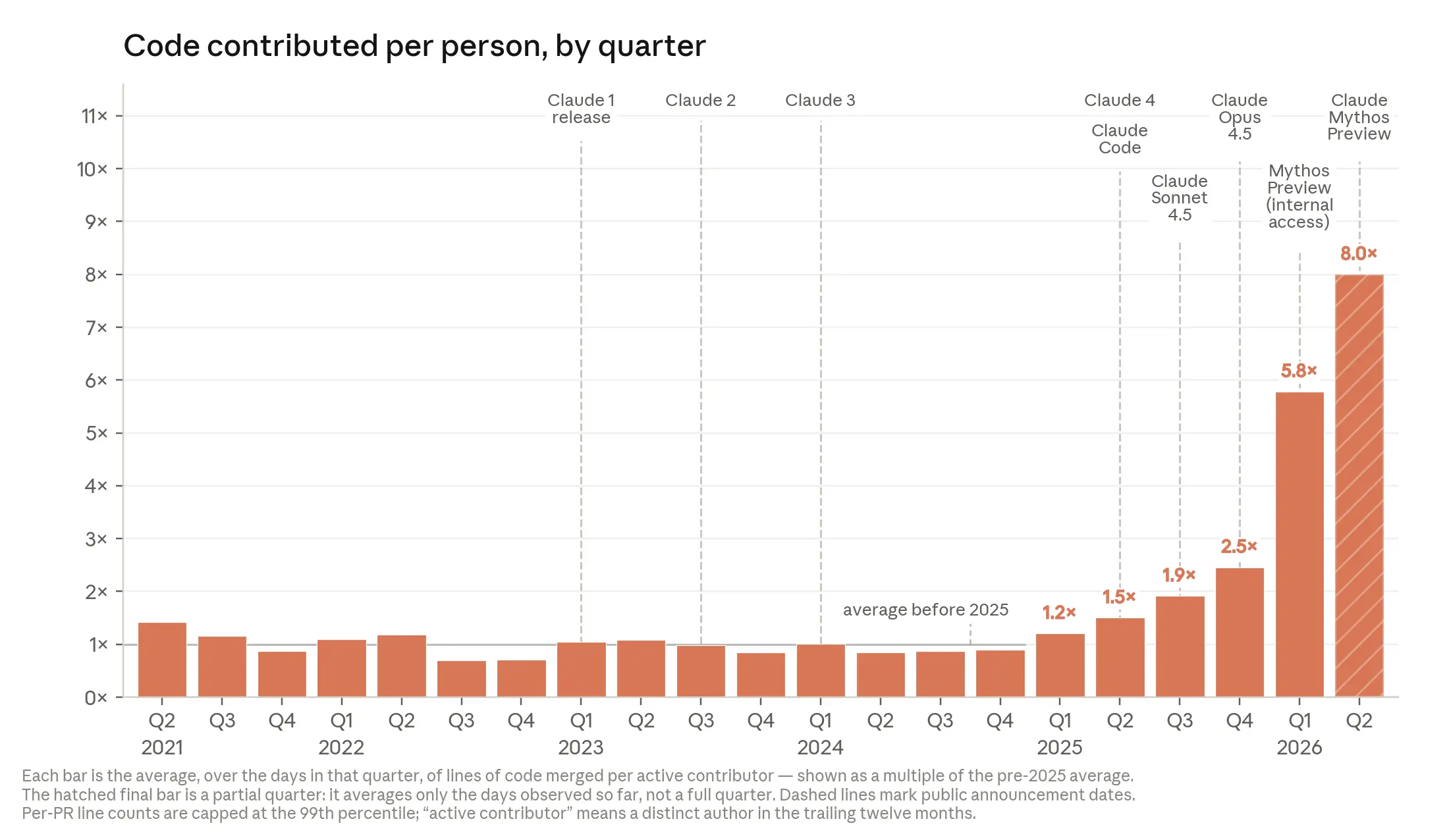
Recursive self-improvement is accelerating; Anthropic data shows an 8x increase in engineer code output and AI reliable task duration doubling every 4 months, projecting week-long task capability by 2027.
入选理由:Anthropic工程师季度代码产出较2021-2025年均值提升8倍,AI已实质性加速研发。
FeaturedArticle#Recursive Self-Improvement#Anthropic#AI Agents#SWE-bench#METR英文

