Build a protein research copilot with Amazon Bedrock AgentCore
AWS Machine Learning Blog3088 字 (约 13 分钟)
85
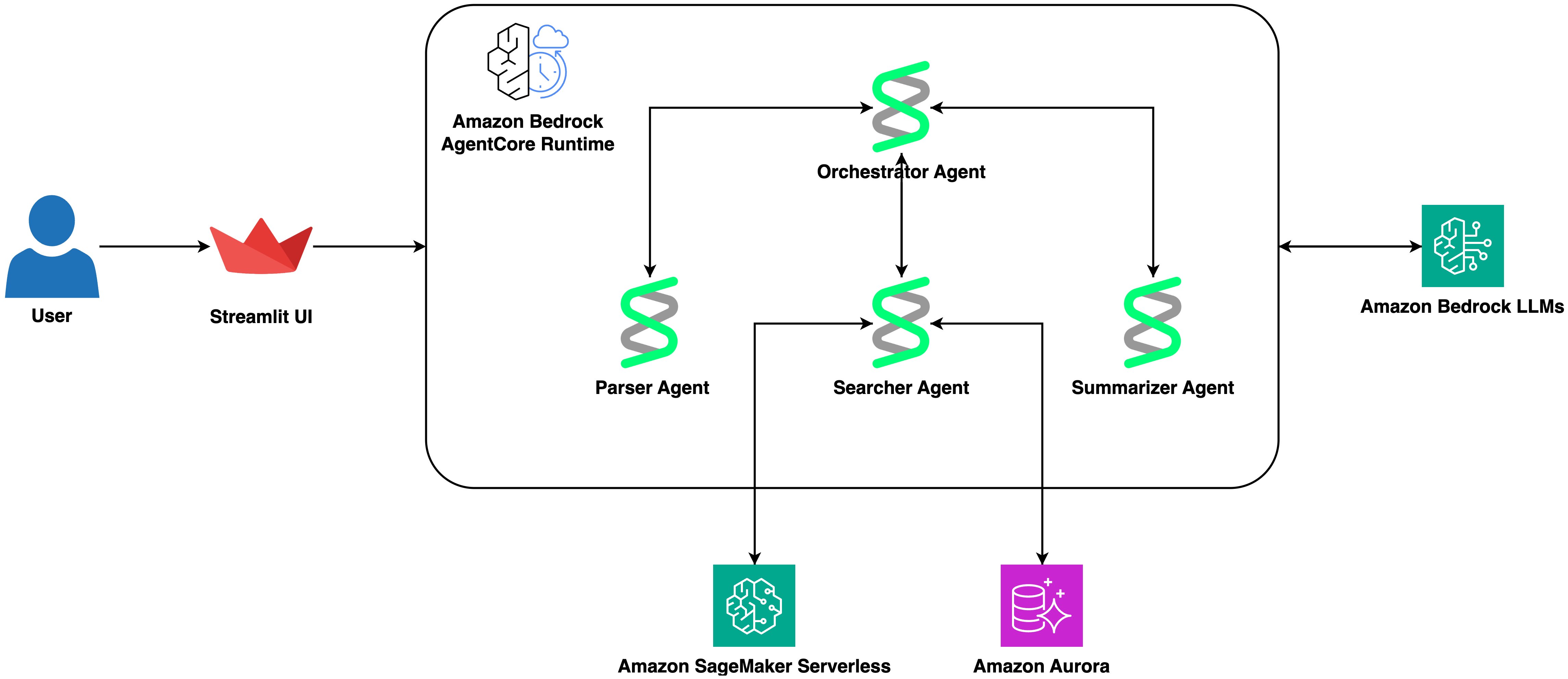
本文展示如何使用 Amazon Bedrock AgentCore 构建蛋白质研究助手,实现自然语言查询、向量相似性搜索和 AI 结果总结。
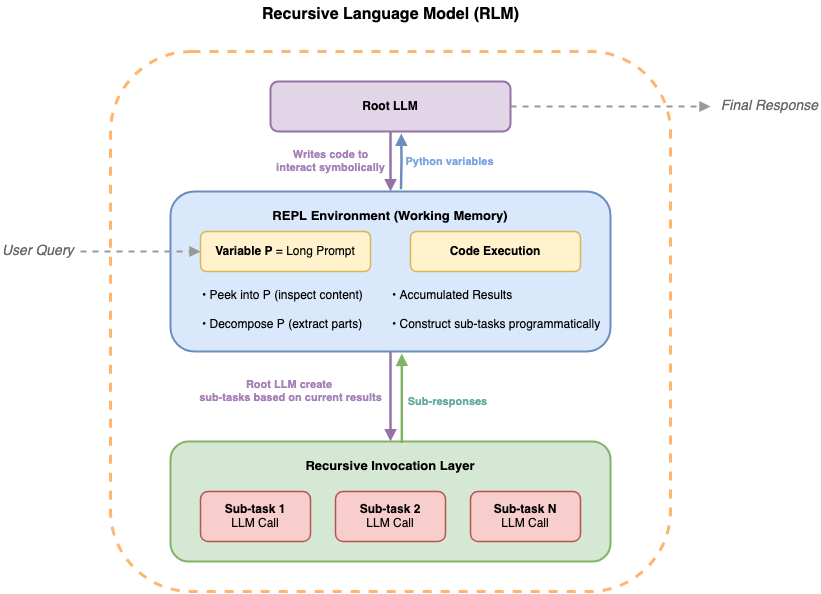
入选理由:使用 Strands Agents SDK 解析自然语言查询为结构化参数。
FeaturedArticle#Amazon Bedrock#AI#蛋白质研究#机器学习英文