Perplexity runs on NVIDIA.
NVIDIA AI(@NVIDIAAI)118 字 (约 1 分钟)
72
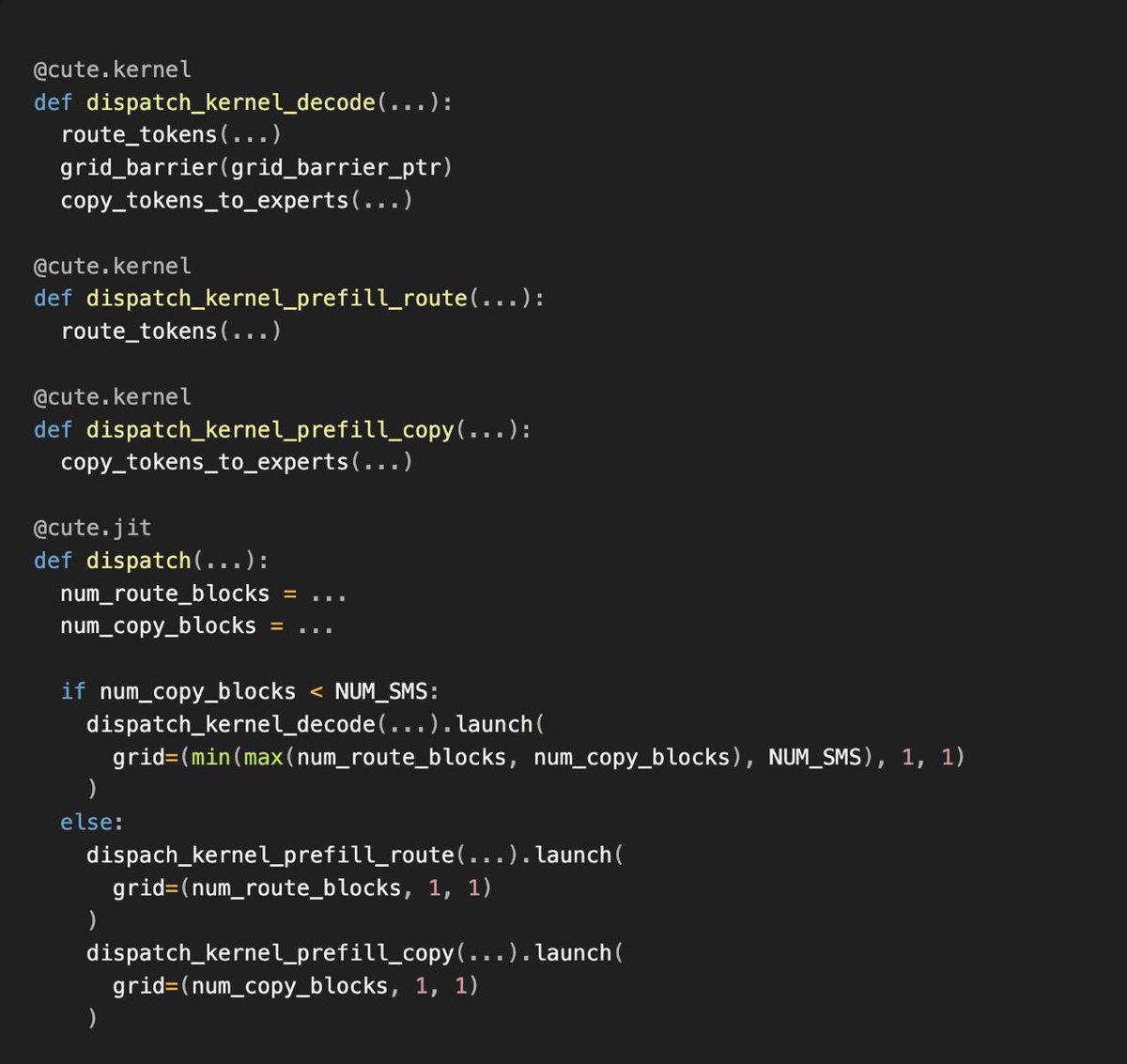
Perplexity leverages NVIDIA's CUTLASS Python stack to optimize its inference models, significantly enhancing the performance of large-scale language models.
入选理由:Perplexity开发了ROSE推理引擎,支持从嵌入到万亿参数LLM的模型服务。
FeaturedTweet#NVIDIA#AI#CUTLASS#Inference Engine英文