57场面试杀进OpenAI!华人博士开源「AI面经」,含泪推荐
量子位3673 字 (约 15 分钟)
85
华人博士Alisa开源AI求职经验,含57场面试细节与OpenAI入职攻略。
入选理由:Alisa共面试57场,最终入职OpenAI。
FeaturedArticle#OpenAI#求职#AI#面试#技术面试中文
产品
用于科学计算的Python库。
已跟踪 8 条高相关材料
最近变化
2026-06-23 · Alisa共面试57场,最终入职OpenAI。
为什么值得关注
NumPy 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
已收录 8 条与 NumPy 相关的内容,按评分排序。
华人博士Alisa开源AI求职经验,含57场面试细节与OpenAI入职攻略。
入选理由:Alisa共面试57场,最终入职OpenAI。
避免在 Pandas 中使用循环,采用 7 种更高效的数据处理方法,提升性能。
入选理由:使用向量化操作替代循环,提升计算效率。
使用 NumPy 的向量化、原地操作和内存视图可显著提升数值计算性能。
入选理由:使用 NumPy 的向量化和广播机制替代显式循环,可提升性能。
Pandas remains the go-to tool for data wrangling due to its powerful features and strong community support.
入选理由:Pandas 在数据清洗和转换方面具有显著优势。
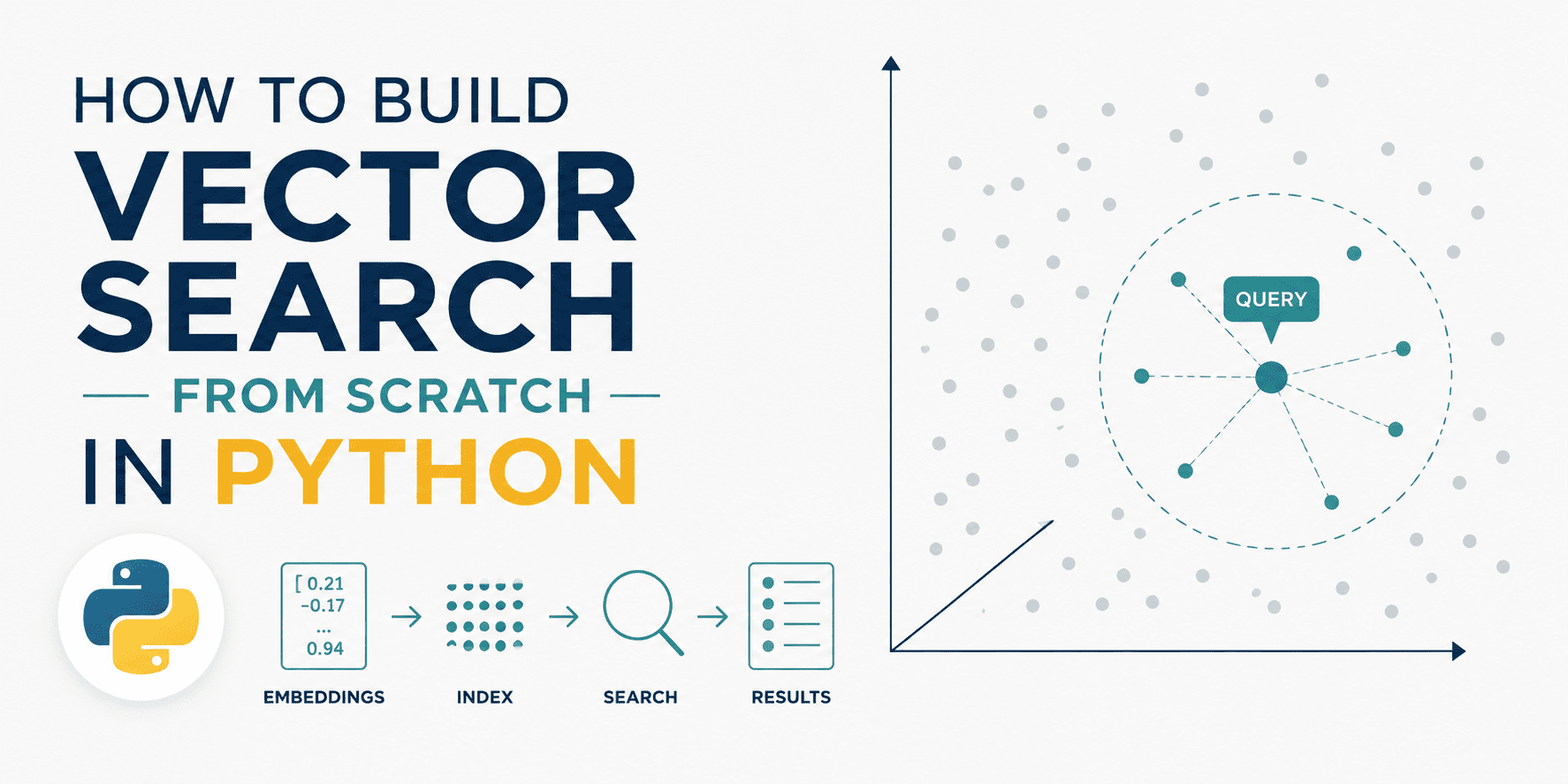
This article explains how to build a vector search system from scratch using Python and NumPy, demonstrating the storage, normalization, and cosine similarity calculation of embedding vectors.
入选理由:使用NumPy构建向量搜索系统
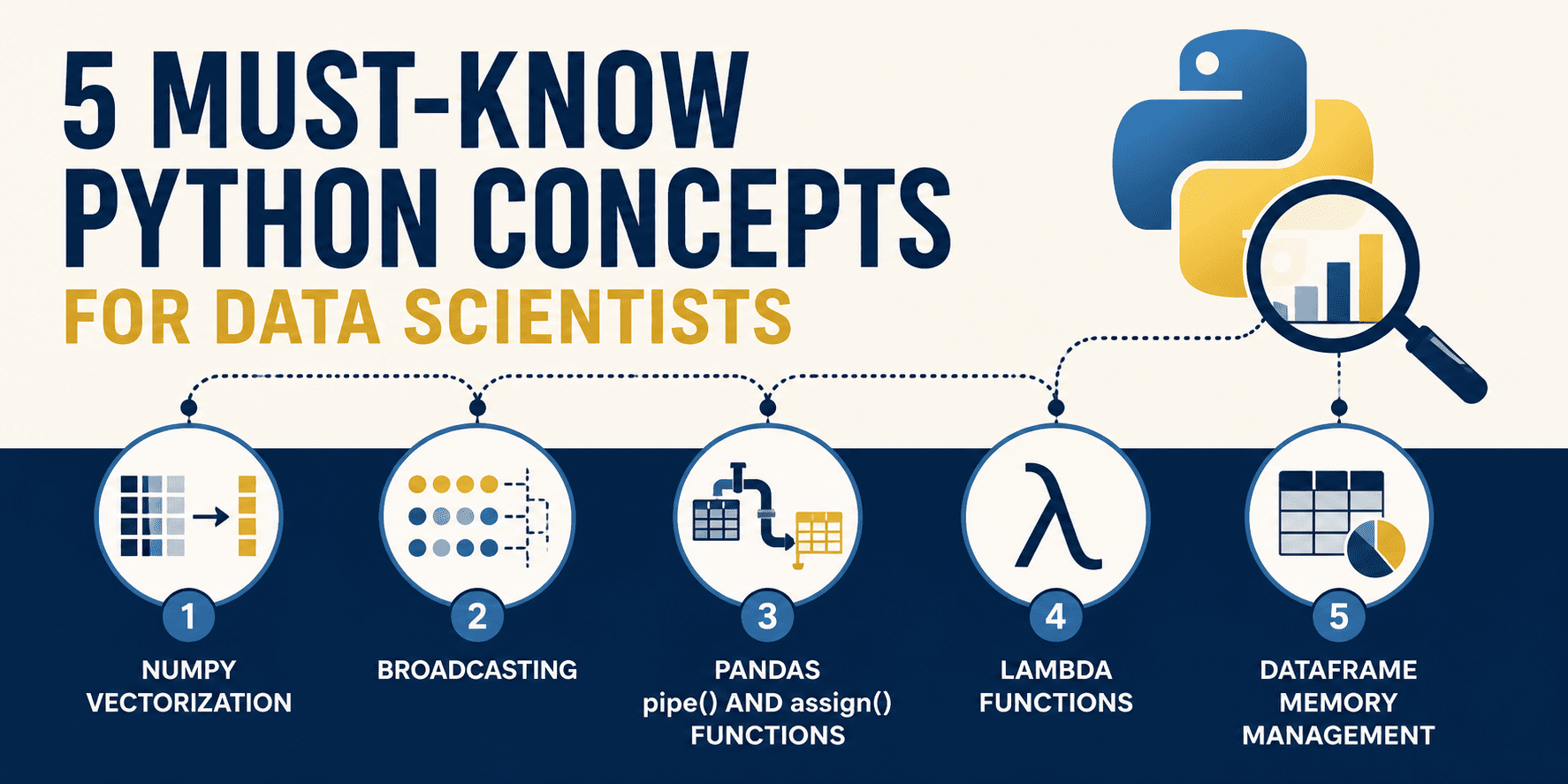
This article introduces five essential Python concepts for data scientists, emphasizing NumPy vectorization and broadcasting mechanisms that significantly improve data processing performance, showing up to 26x speedup compared to traditional loops.
入选理由:使用NumPy向量化可将数组运算速度提升至传统Python循环的26倍以上
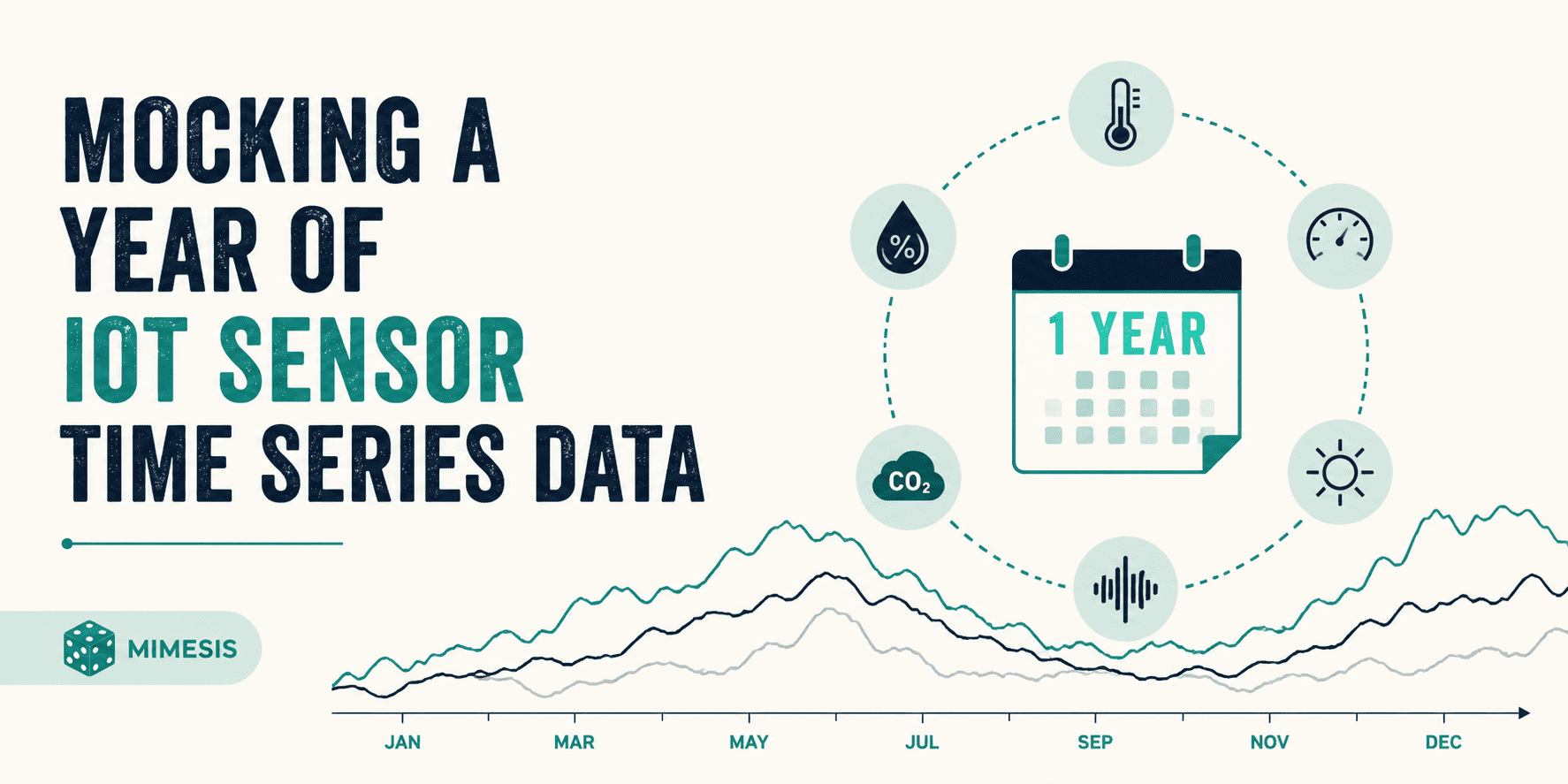
This article demonstrates how to generate a year's worth of IoT sensor time series data using the Mimesis tool combined with a mathematical model, focusing on simulating seasonal temperature fluctuations and including device metadata for machine learning and data analysis applications.
入选理由:使用 Mimesis 生成随机设备元数据,包括 device_id、location、firmware_version 和 ip_address。
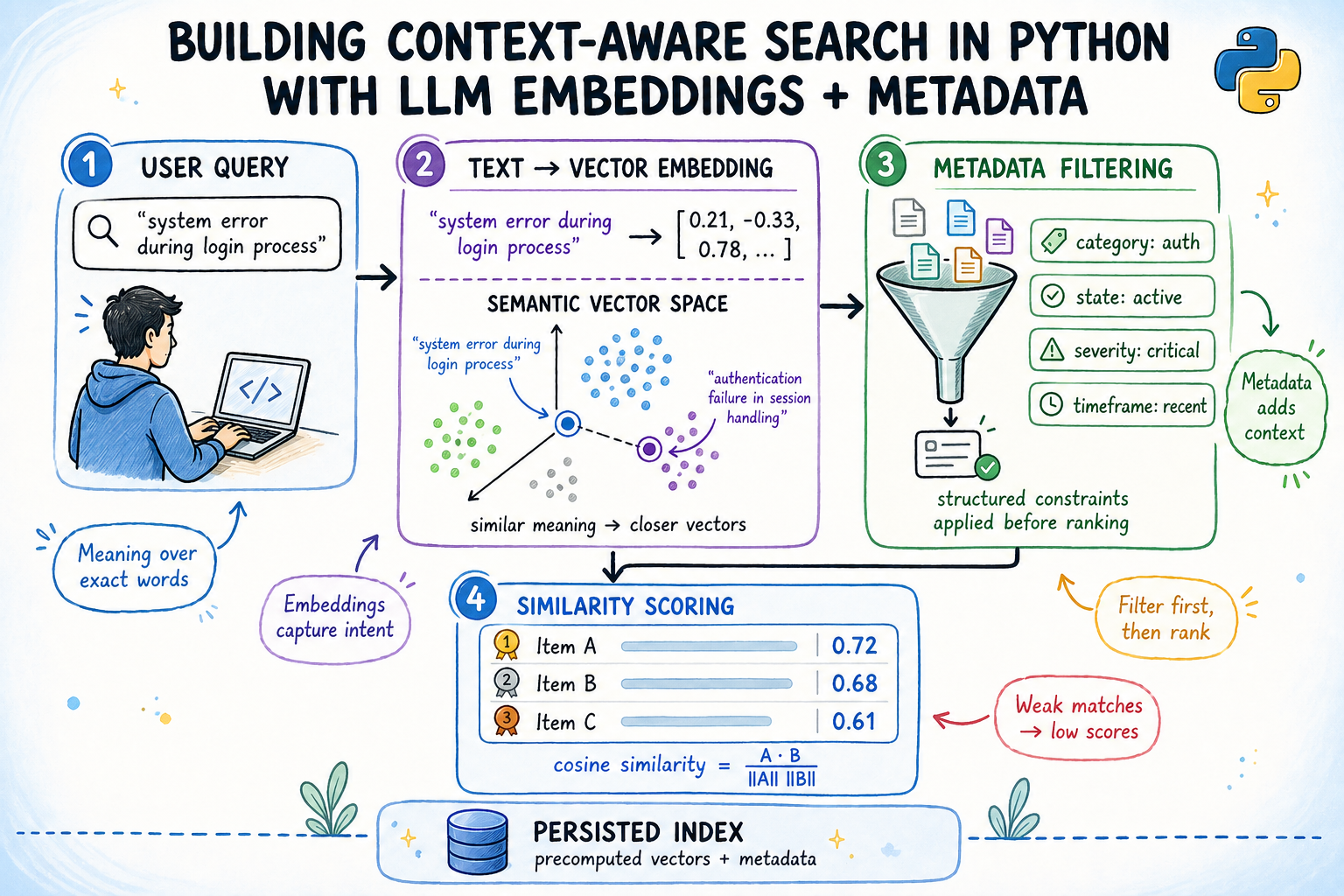
This article explains how to build a context-aware semantic search engine in Python using LLM embeddings combined with metadata filtering.
入选理由:使用本地预训练模型生成384维向量,无需API密钥即可实现语义搜索。