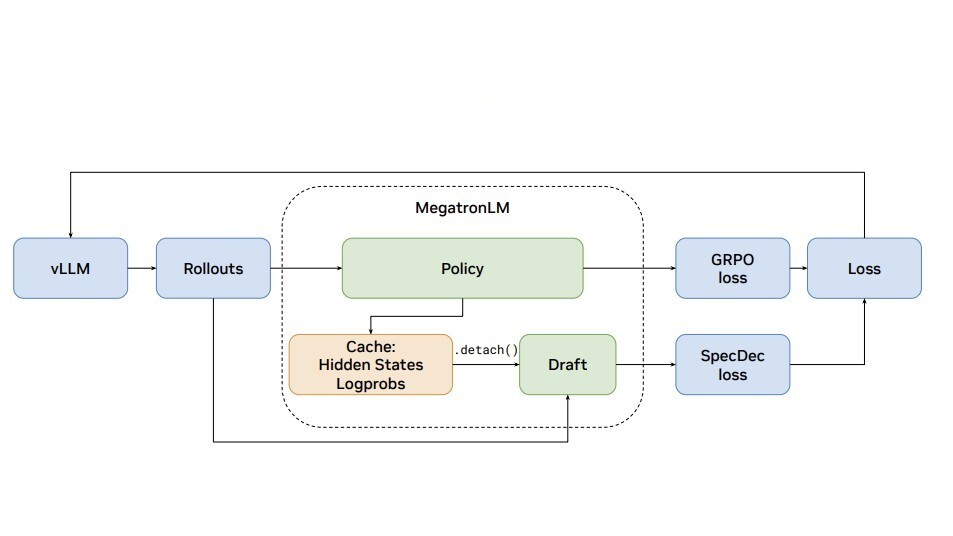
RL post-training is hitting a rollout bottleneck. This new paper from #NVIDIAResearch shows how sp...
NVIDIA AI(@NVIDIAAI)324 字 (约 2 分钟)
72
NVIDIA 研究提出将 speculative decoding 引入 NeMo-RL + vLLM 架构,实现 RL 后训练 rollout 阶段无损加速:8B 模型吞吐提升 1.8 倍,235B 模型端到端预计提速 2.5 倍。
入选理由:RLHF/RLAIF 后训练的 rollout 阶段已成为性能瓶颈
FeaturedTweet#RLHF#speculative decoding#vLLM#NeMo-RL#NVIDIA中英混合