ByteDance Open-Sources Unified Framework Bernini: Giving DiT a 'Large Model Strategist', AI Video Editing Understands First, Then Acts
量子位3715 字 (约 15 分钟)
87
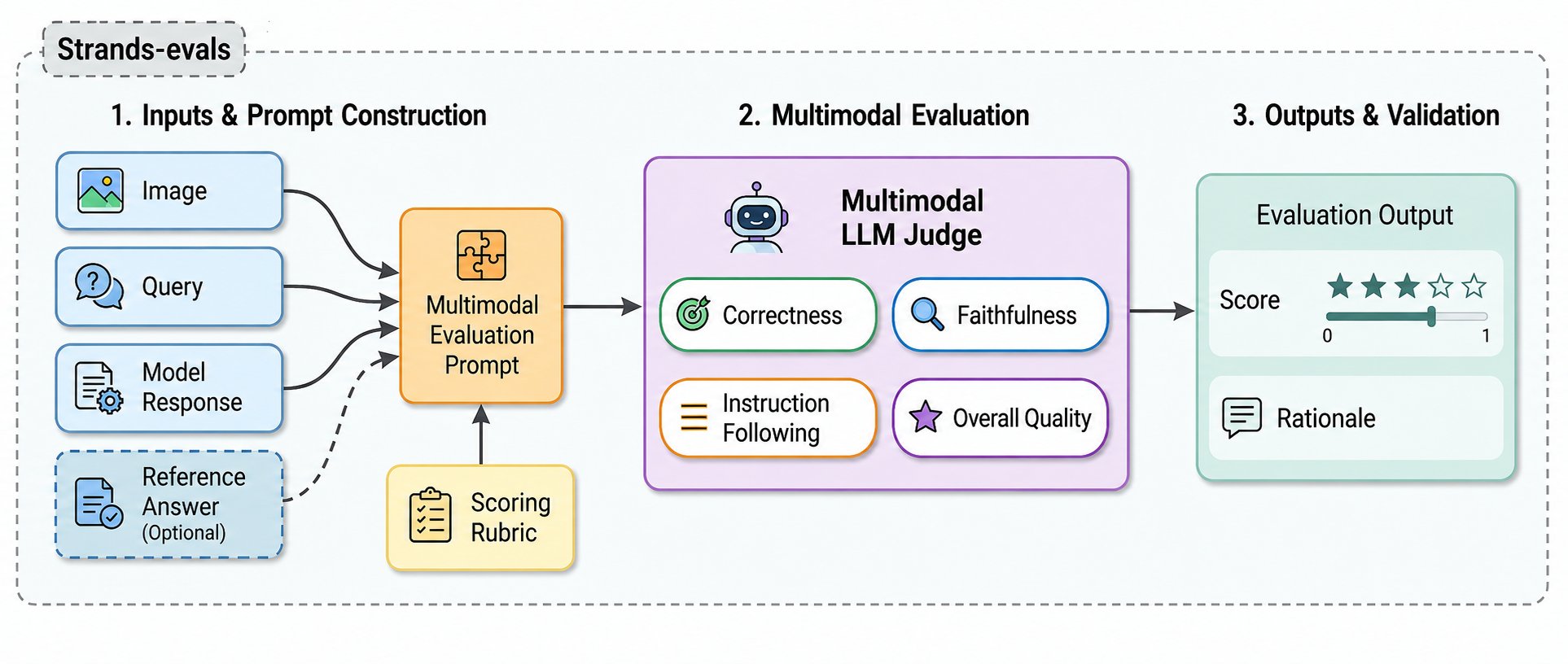
ByteDance open-sources Bernini, a unified framework for video generation and editing that uses a multimodal large model (MLLM) to understand semantic instructions first, then delegates high-quality rendering to a DiT diffusion model, enabling a paradigm shift from 'listening to prompts' to 'understanding before acting' in AI video creation, supporting controllable editing and reference-based generation.
入选理由:Bernini采用MLLM-based planner + DiT-based renderer双阶段架构,实现语义理解与视觉生成的解耦。
FeaturedArticle#AI Video Generation#Video Editing#Bernini#DiT#Multimodal Large Model中文