Gemma 4 12B: The Developer Guide
Google Developers Blog1171 字 (约 5 分钟)
92
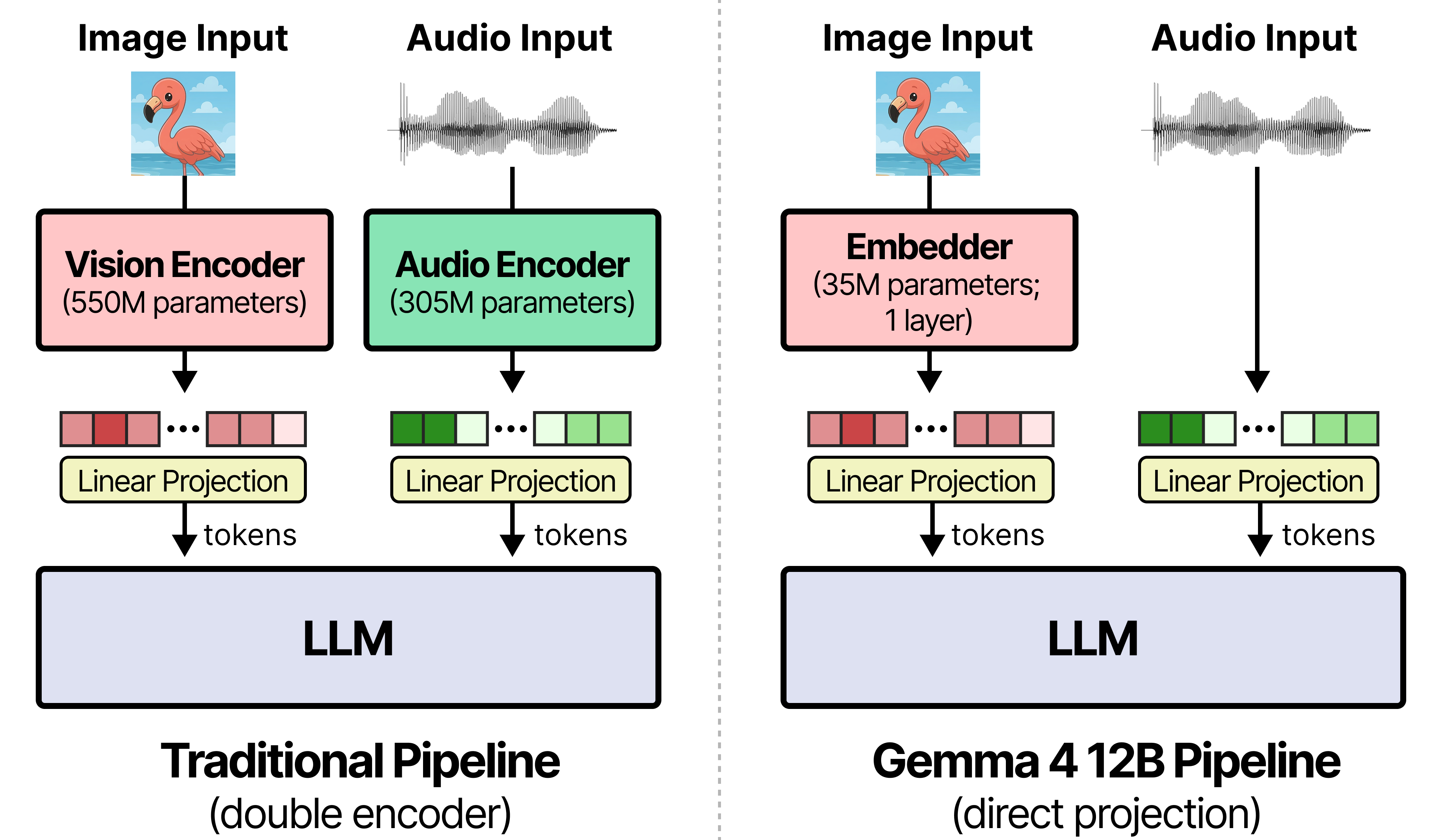
Gemma 4 12B features an encoder-free multimodal architecture that runs locally on 16GB VRAM devices with native audio support. By eliminating separate vision and audio encoders, it reduces latency and pairs with a dedicated MTP model for faster inference, marking the first mid-sized multimodal model with a macOS desktop app for fully offline interaction.
入选理由:Gemma 4 12B移除独立编码器,视觉仅用35M参数嵌入层,音频直接线性投影至LLM输入空间
FeaturedArticle#Gemma 4#Multimodal LLM#Encoder-Free Architecture#Local AI#Google英文




