Benchmark and optimize LLMs on-device with AI Edge Portal
Google Cloud Blog924 字 (约 4 分钟)
85
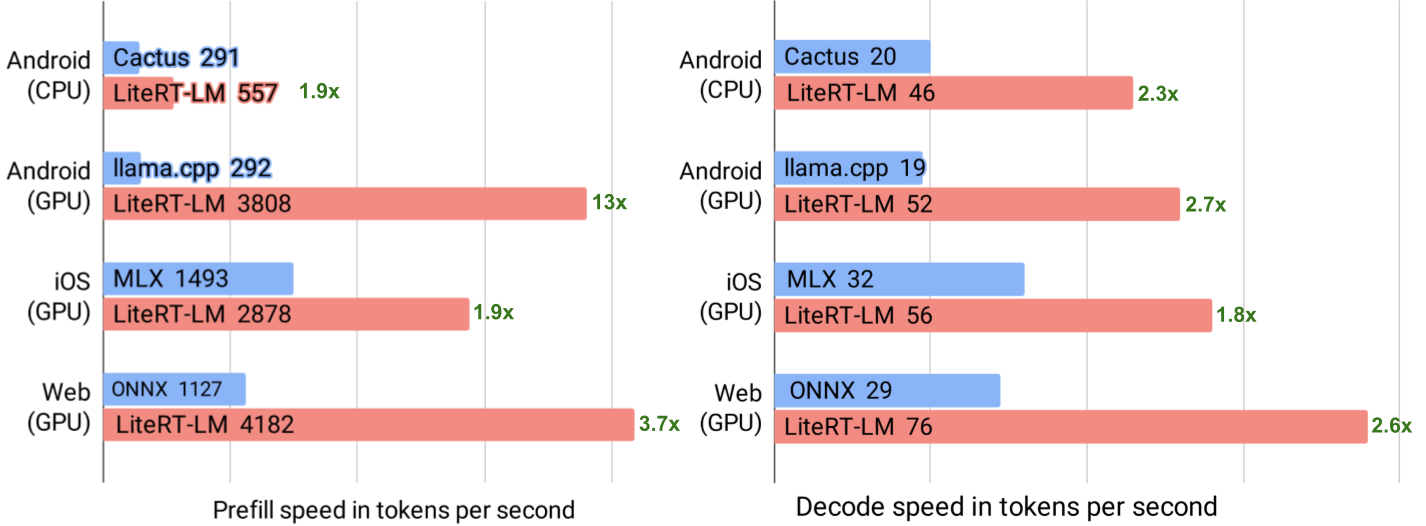
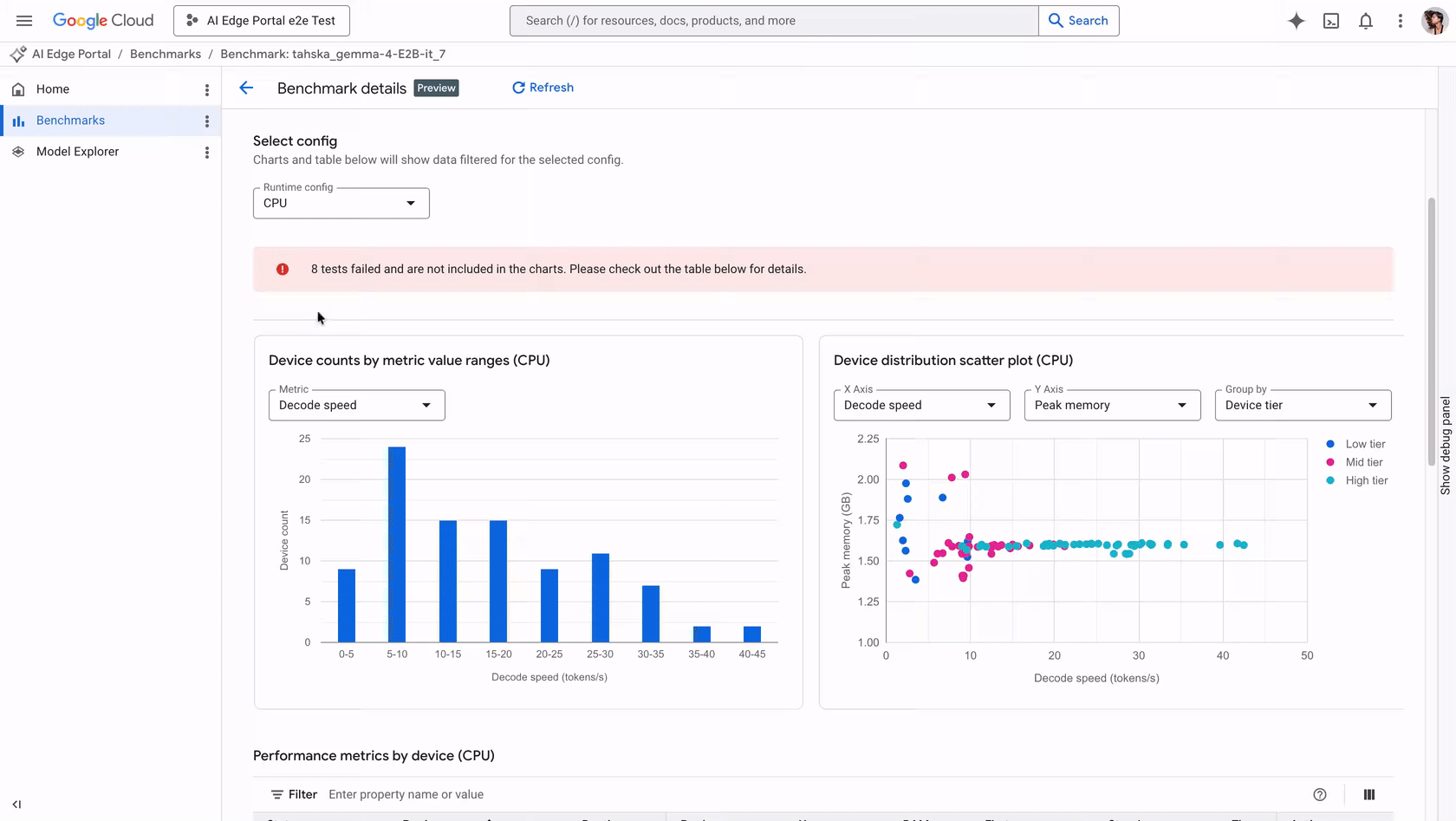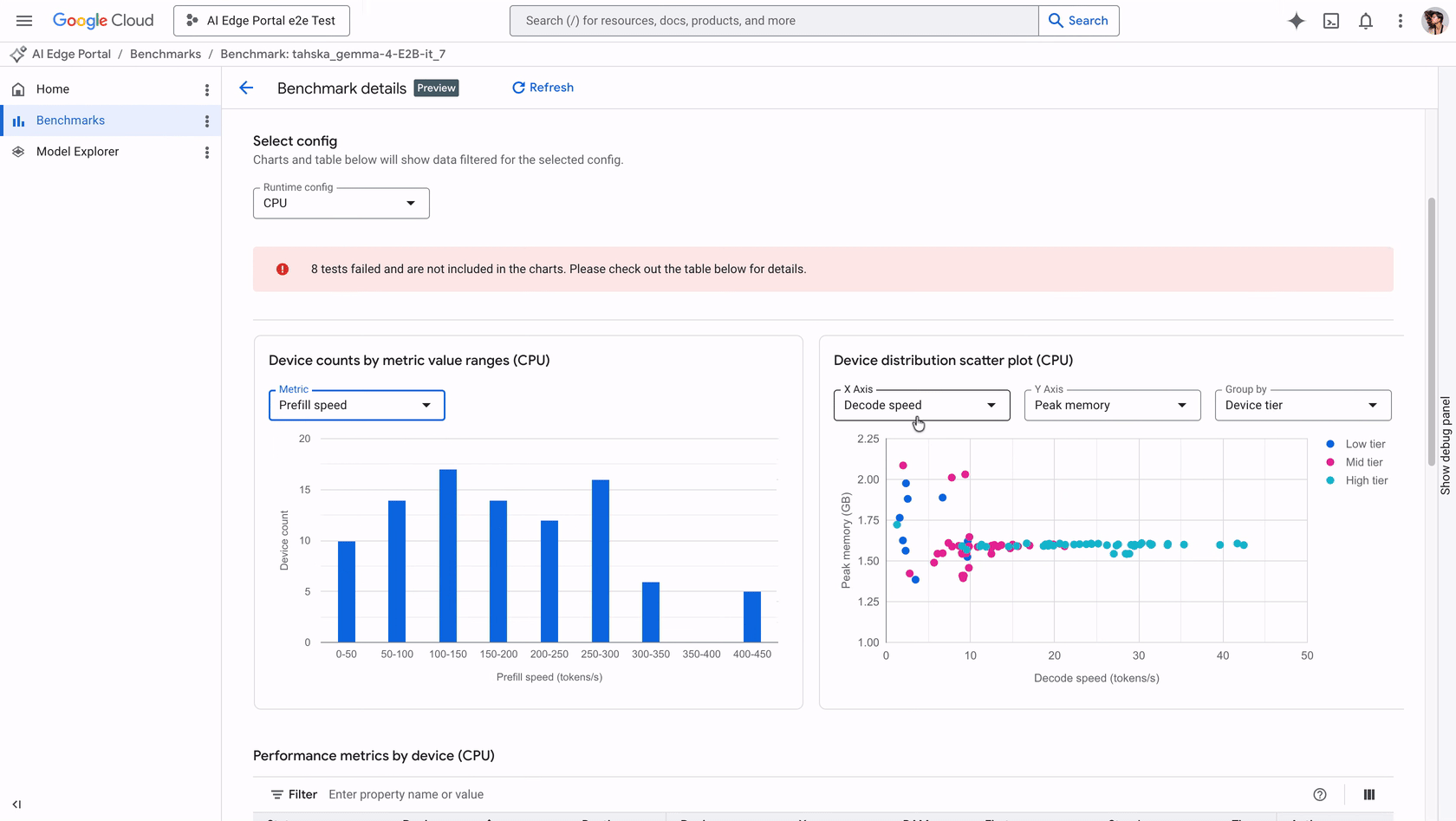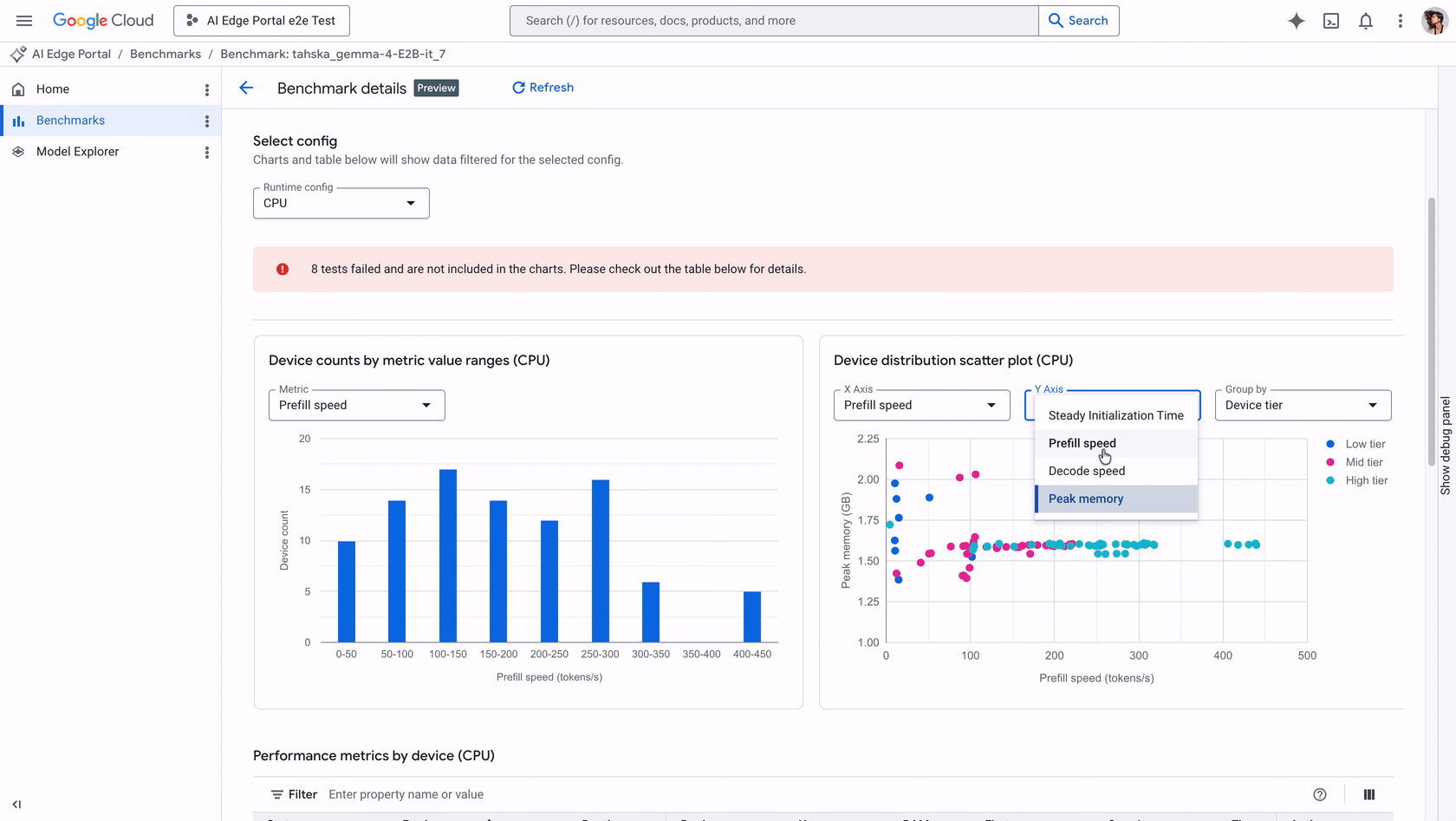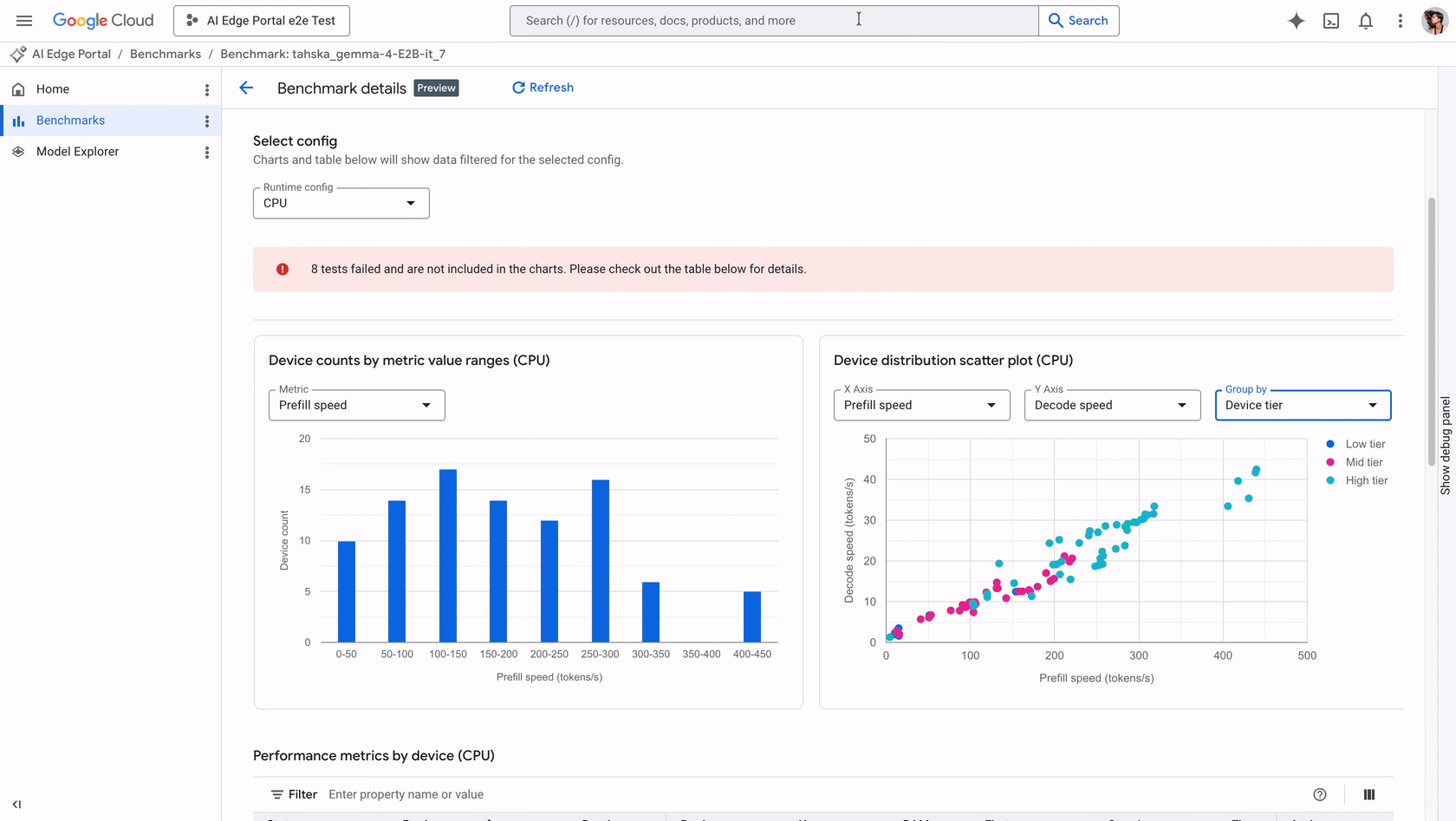
Google AI Edge Portal introduces new LLM benchmarking and debugging capabilities, enabling performance optimization across over 120 Android devices with key metrics like initialization time and decode speed analysis, plus visualization tools.
入选理由:AI Edge Portal支持在120+ Android设备上测试LLM,提供初始化时间、预填速度等4项核心性能指标
FeaturedArticle#LLM optimization#Edge computing#Android devices#Google AI Edge Portal#Model Explorer英文