Google AI Studio 3.0 (Fully Free): This is ACTUALLY AWESOME!
AICodeKing979 字 (约 4 分钟)
87
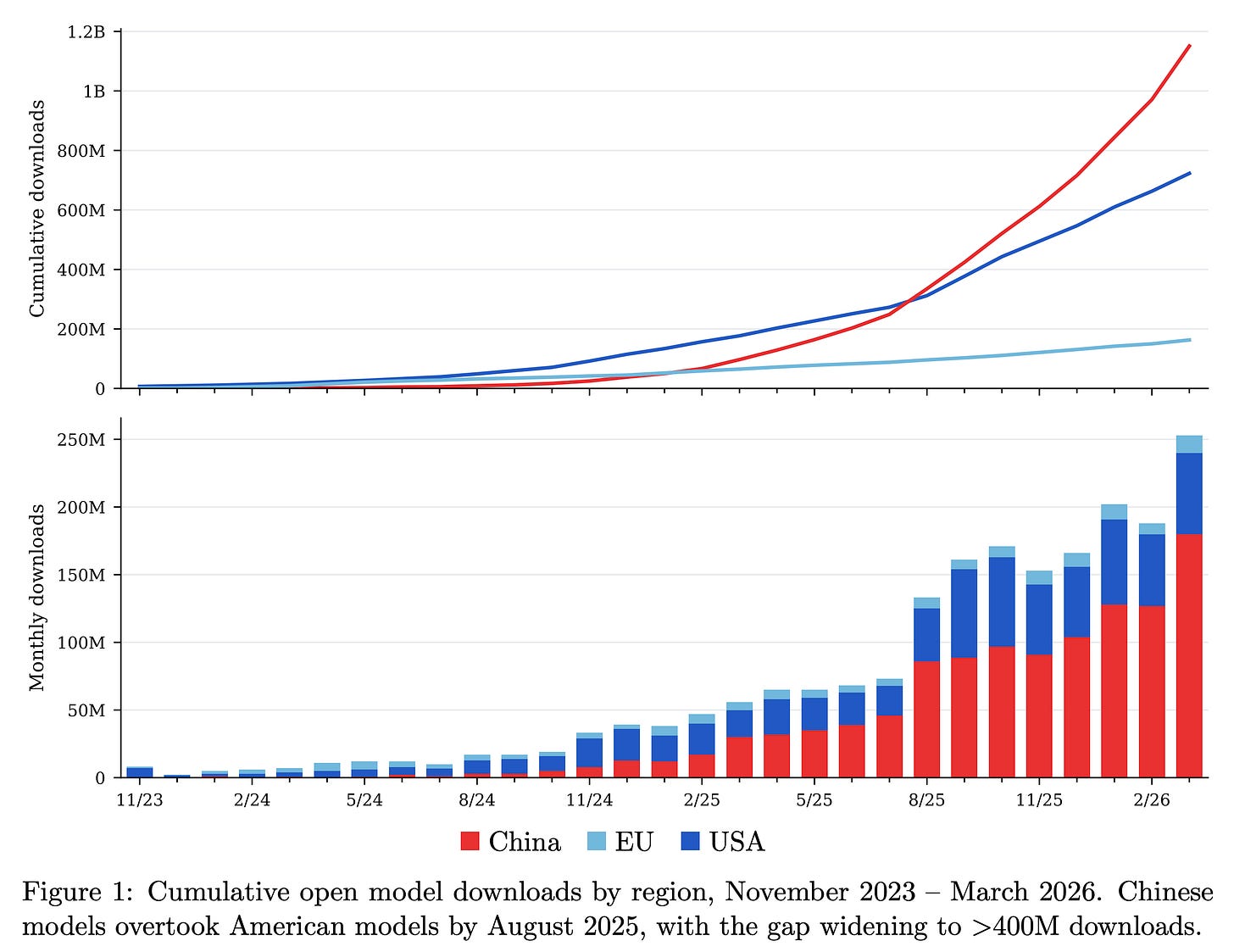
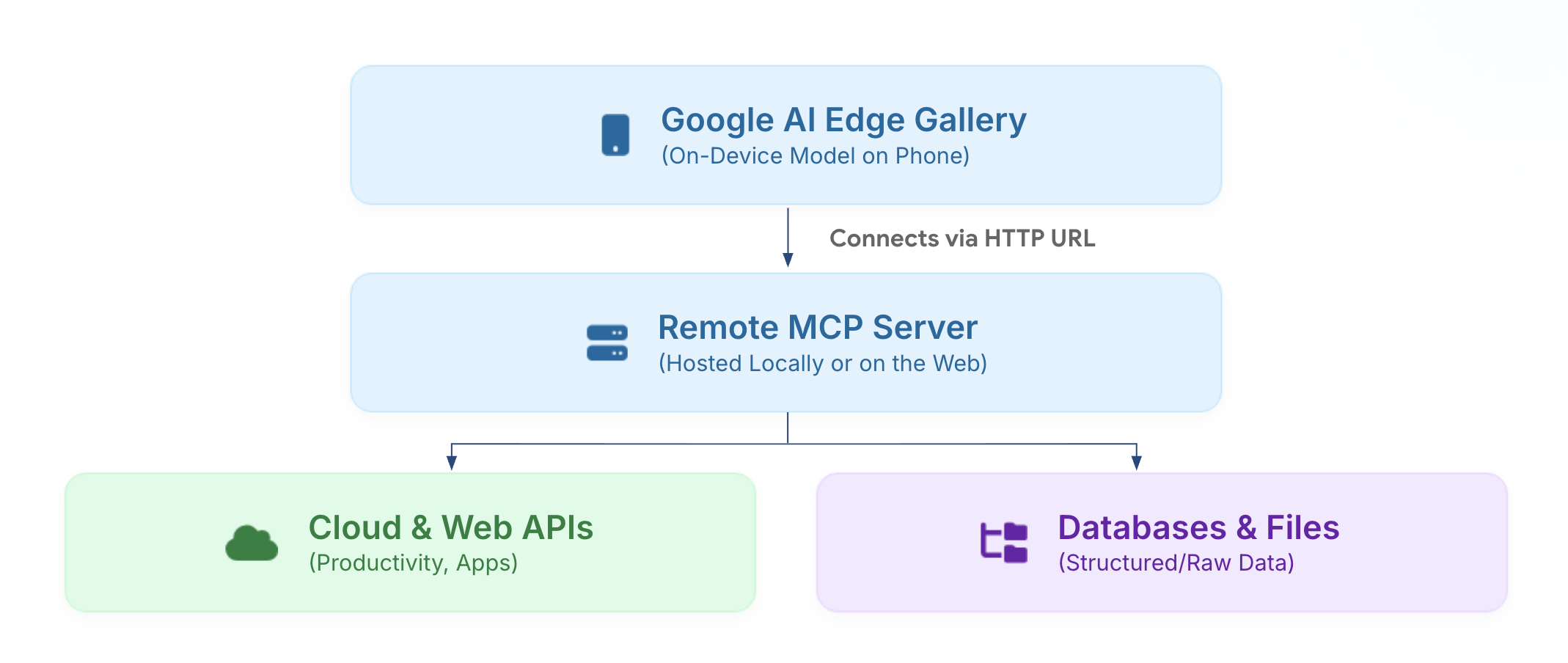
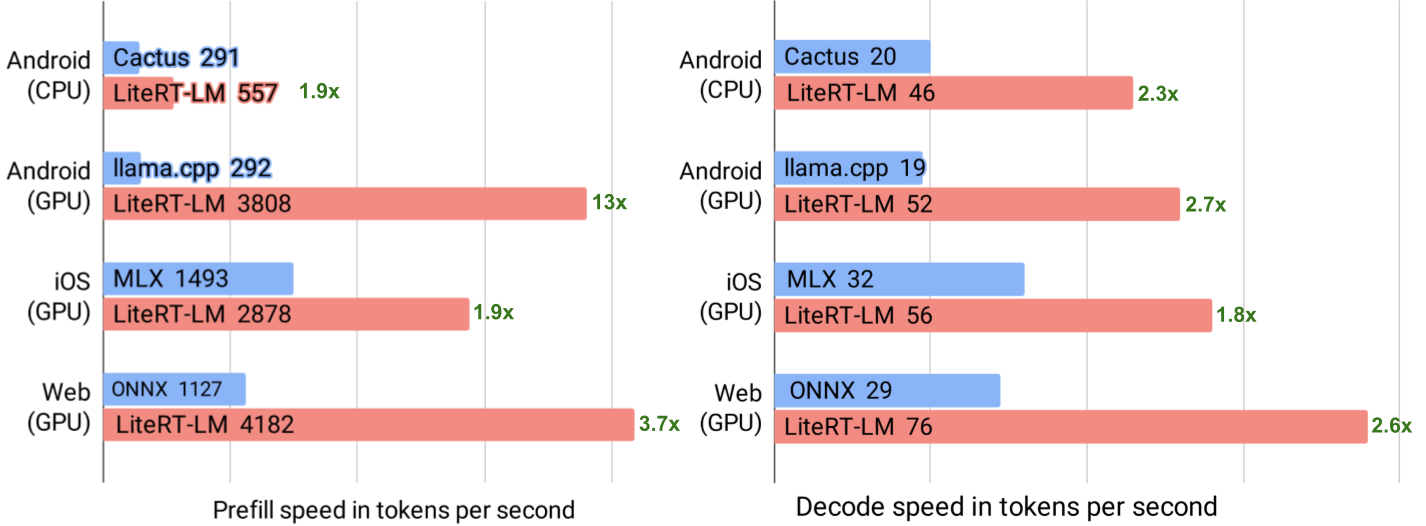
Google AI Studio 3.0 launches fully free with integrated Gemma 4 model and multimodal capabilities, enabling real-time inference, custom model deployment, and API access, significantly lowering the barrier for developers.
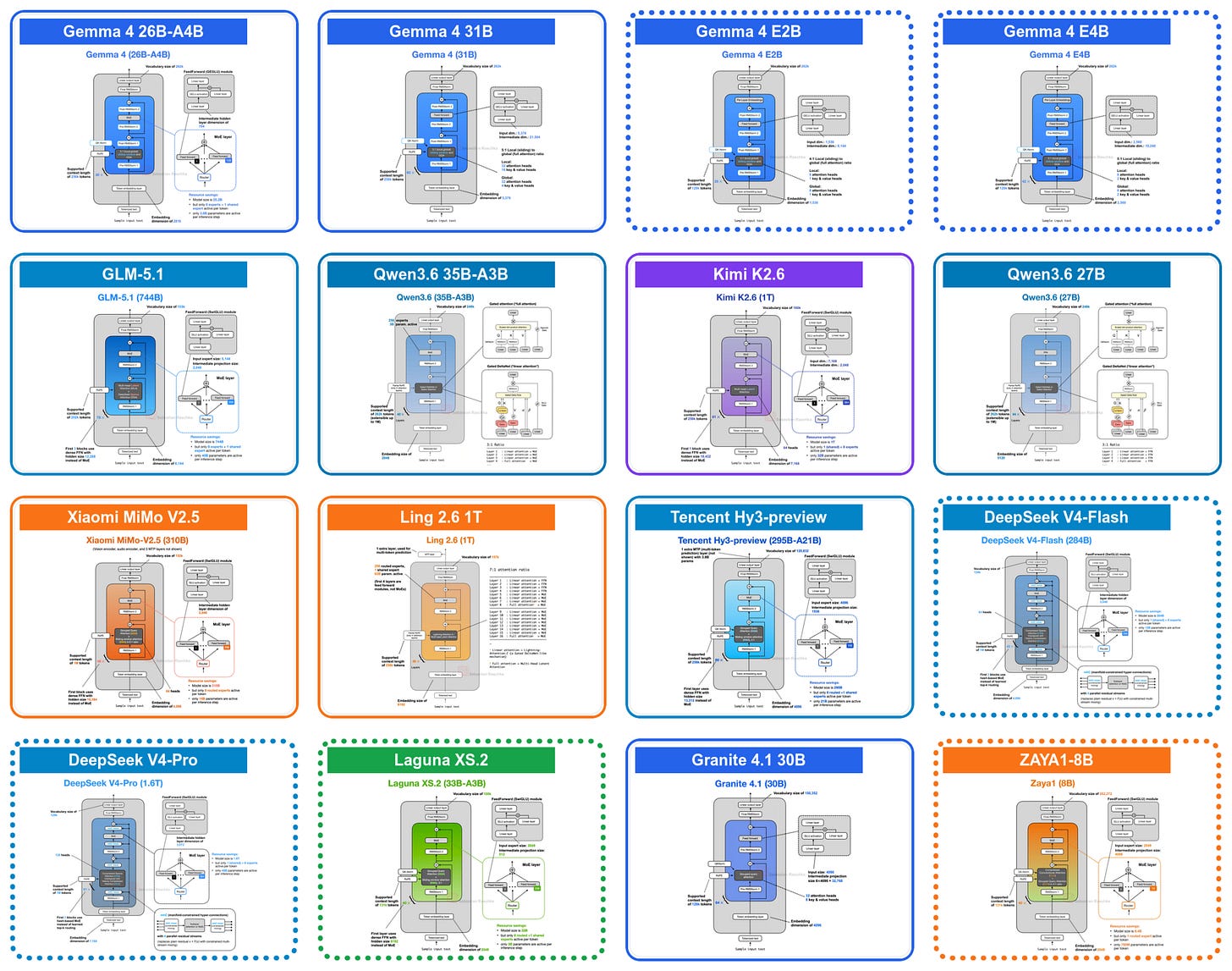
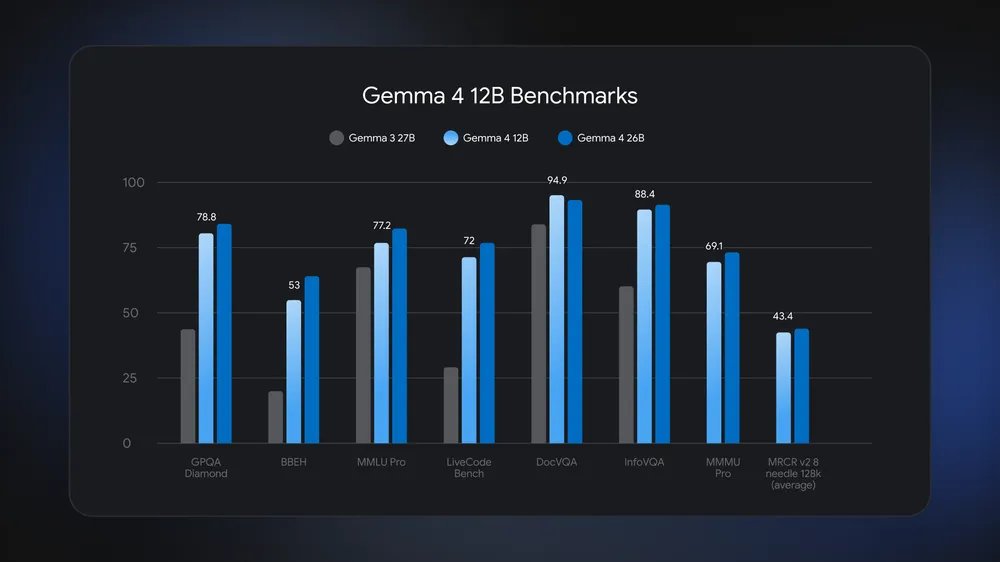
入选理由:Gemma 4 模型在 Google AI Studio 3.0 中完全免费,支持 128K 上下文长度。
FeaturedVideo#Google AI Studio#Gemma 4#AI development tool#free AI platform中文