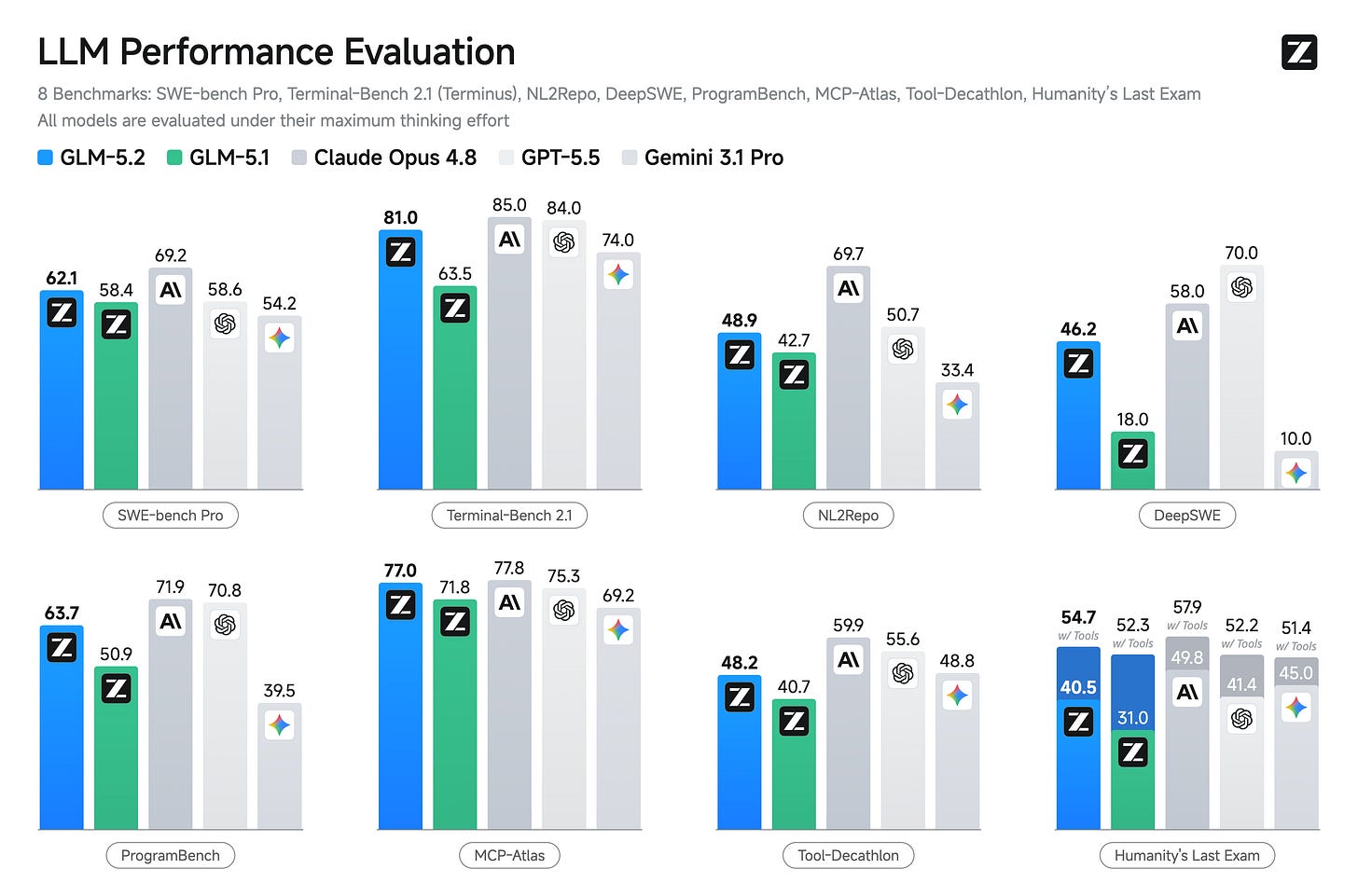
GLM-5.2 is the step change for open agents
Interconnects AI1879 字 (约 8 分钟)
85
GLM-5.2 在开放模型中表现突出,超越了多个主流模型,成为开放代理的重要进展。
入选理由:GLM-5.2 在 Arena 的代理排行榜中表现优于 OpenAI 和 Anthropic 的最新模型。
FeaturedArticle#GLM-5.2#AI 模型#开放代理#Z.ai英文
产品
别名:DesignArena
AI 模型竞技榜单平台,发布 Kimi K3 前端设计排名第一的排名。
已跟踪 13 条高相关材料
最近变化
2026-07-21 · Kimi K3 在 Design Arena 前端设计榜单中以 Elo 1326 排名第一
为什么值得关注
Design Arena 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
GLM-5.2 is the step change for open agents
Interconnects AI · 8.5 分
GLM-5.2 在开放模型中表现突出,超越了多个主流模型,成为开放代理的重要进展。
GLM 5.2 just beat Fable 5 at website design. 🌐 The crazy part: GLM is text-only. It can build the...
Browser Use(@browser_use) · 8.5 分
GLM 5.2 在网页设计中击败 Fable 5,通过与 Browser Use v2 多模态 QA 子代理协作实现。
20 days of compute vs 7 hours: rethinking what state-of-the-art means — Bertrand Charpentier, Pruna
AI Engineer · 7.5 分
当前“最先进”AI模型的评判标准存在误导性,仅依赖公开排行榜或内部评估易导致选择大模型的懒惰方案,实际应结合多榜单差异、Elo评分波动及真实场景需求综合判断。
已收录 13 条与 Design Arena 相关的内容,按评分排序。
GLM-5.2 在开放模型中表现突出,超越了多个主流模型,成为开放代理的重要进展。
入选理由:GLM-5.2 在 Arena 的代理排行榜中表现优于 OpenAI 和 Anthropic 的最新模型。
GLM 5.2 在网页设计中击败 Fable 5,通过与 Browser Use v2 多模态 QA 子代理协作实现。
入选理由:GLM 5.2 在 Design Arena 的 HTML 网页设计评估中排名第一,比前代 GLM 5.1 高出 5 名。
Current 'state-of-the-art' AI model evaluation is misleading; relying solely on public leaderboards or internal tests often leads to lazy large-model choices—real selection should combine multi-board differences, Elo score volatility, and real-world use cases.
入选理由:不同排行榜(如Arena、Design Arena)对同一图像编辑模型排名差异显著,例如Human模型在不同榜单位置相差5名以上。
GLM-5.2 在设计任务中表现优异,尤其在游戏、网页和3D世界设计方面,但尚未达到专业设计师水平。
入选理由:GLM-5.2 在设计任务中表现优异,尤其擅长游戏和3D世界设计。
Kimi K3 在前端设计竞技中超越 Fable 5 和 Claude 全系模型,成为榜首。GPT-5.6 Sol 前端能力仍不足,跌出前十。
入选理由:Kimi K3 在 Design Arena 前端设计榜单中以 Elo 1326 排名第一
OpenRouter 推出新的 Benchmarks API,可实时查询模型性能排名,GLM-5.2 在编码和设计方面表现最佳。
入选理由:OpenRouter 推出了 Benchmarks API,支持实时查询模型性能。
GLM-5.2 在网页设计评估中排名第一,超越了多个竞品模型。
入选理由:GLM-5.2 在 Design Arena 的 HTML 网页设计评估中排名第一。
GLM 5.2 在 Design Arena 的网页设计评分中排名第一,但缺乏真实对比数据,引发质疑。
入选理由:GLM 5.2 在 Design Arena 的网页设计评分中排名第一,比 Fable 5 高 5 名。
Riverflow 2.5 Pro 在设计领域排行榜上排名第一,但文章信息密度低,缺乏技术深度。
入选理由:Riverflow 2.5 Pro 在 Design Arena 的图像、图形设计和图像编辑类别中排名第一。
GLM-5.2 在设计评估中超越 Claude Fable 5,但文章信息密度低,缺乏技术细节。
入选理由:GLM-5.2 在 Design Arena 的 Elo 评分为 1360,超越 Claude Fable 5。
GLM-5.2 在 Design Arena 排名第一,Elo 分数达到 1360,超越 Claude Fable 5。
入选理由:GLM-5.2 在 Design Arena 的 Elo 分数为 1360。
Recraft V4.1 has been launched on Design Arena, offering more natural and expressive image generation capabilities.
入选理由:Recraft V4.1 支持更自然和富有表现力的图像生成。
Recraft's V4.1 Utility Pro has ranked #7 on Design Arena's 2026 image generator leaderboard in graphic design and #9 on Image Arena with Elo 1243 within one week of launch, placing the company among top 5 image generation labs alongside OpenAI, GoogleDeepMind, LumaLabsAI, and bfl_ml.
入选理由:Recraft V4.1 Utility Pro achieved #7 ranking on Design Arena's 2026 graphic design leaderboard within one week of release




