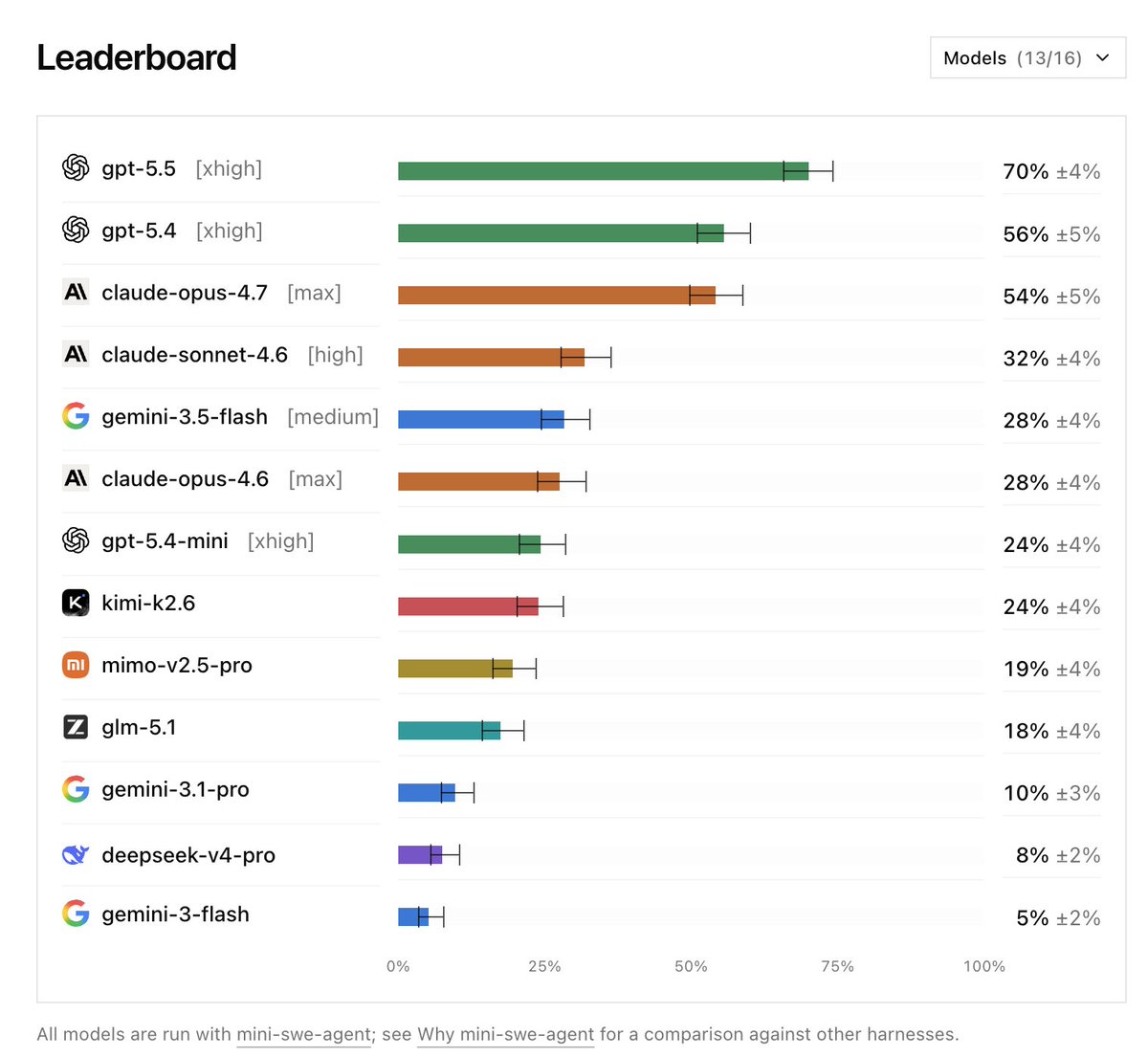
昨天又有一个新的 coding benchmark DeepSWE:https://t.co/3V65OaHScM 创新是无污染的任务,就是所有任务全新原创,从零编写,未基于现有 PR/Commi...
Viking(@vikingmute)409 字 (约 2 分钟)
85
DeepSWE 是一个全新的编程基准测试,涵盖多种语言和真实世界复杂度,参考解决方案平均需要修改 668 行代码。
入选理由:DeepSWE 是一个全新的编程基准测试,涵盖多种语言和真实世界复杂度。
FeaturedTweet#DeepSWE#编程基准测试#GPT-5.5#多语言#真实世界复杂度中文

