PyTorch 2.13 Release Blog
PyTorch Blog2425 字 (约 10 分钟)
85
PyTorch 2.13发布,引入FlexAttention加速、CuTeDSL后端、内存优化等,显著提升多平台性能与分布式训练效率。
入选理由:FlexAttention在Apple Silicon上实现最高12倍加速,提升稀疏模式性能。
FeaturedArticle#PyTorch#深度学习#性能优化#分布式训练英文
概念
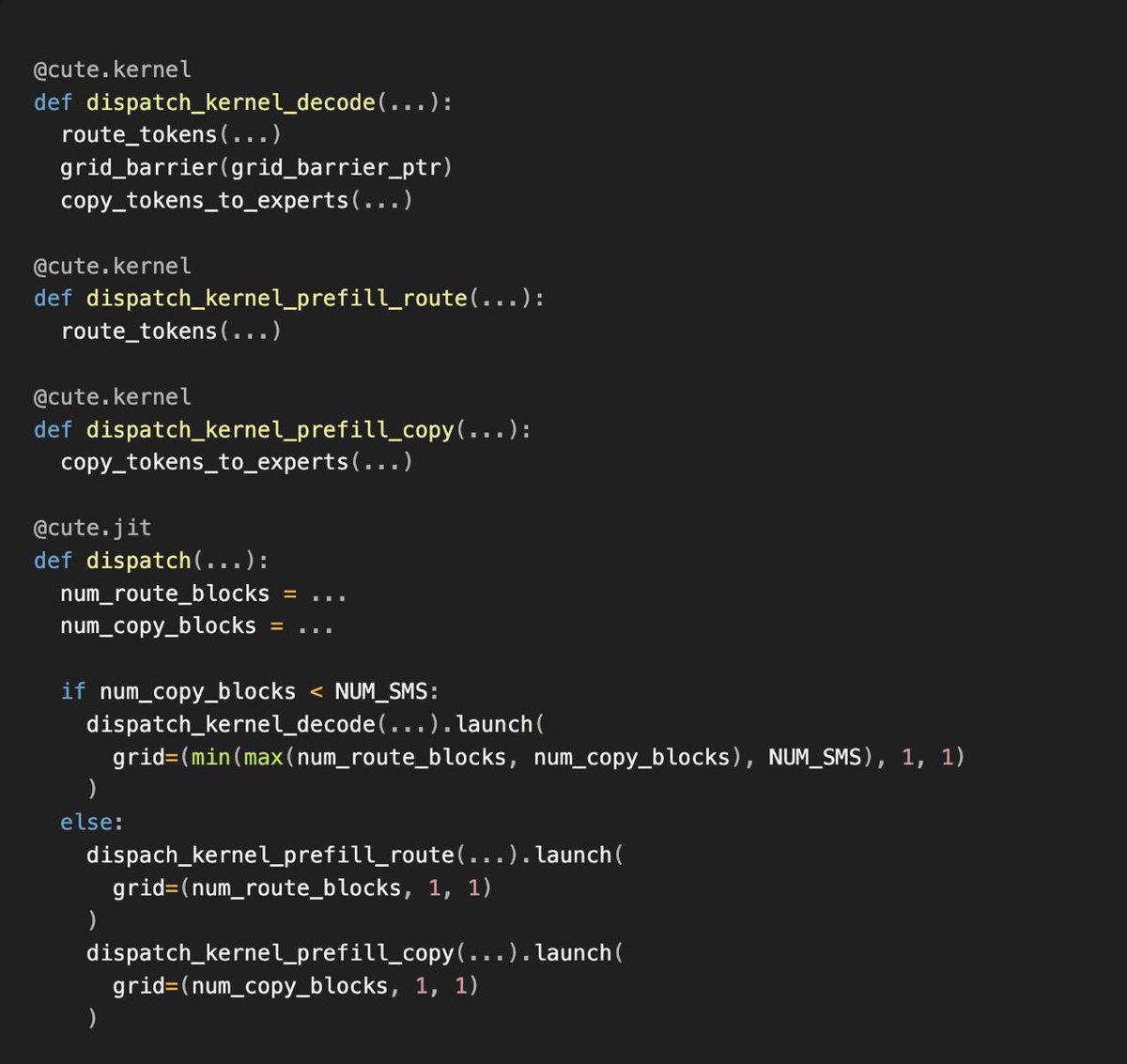
Inductor的高性能代码生成后端。
已跟踪 4 条高相关材料
最近变化
2026-07-08 · FlexAttention在Apple Silicon上实现最高12倍加速,提升稀疏模式性能。
为什么值得关注
CuTeDSL 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
PyTorch 2.13 Release Blog
PyTorch Blog · 8.5 分
PyTorch 2.13发布,引入FlexAttention加速、CuTeDSL后端、内存优化等,显著提升多平台性能与分布式训练效率。
Perplexity runs on NVIDIA. Nice breakdown from the team on how they’re using the CUTLASS Python st...
NVIDIA AI(@NVIDIAAI) · 7.2 分
Perplexity利用NVIDIA的CUTLASS Python栈优化其推理模型,显著提升大规模语言模型的性能。
We’ve developed our own inference engine Runtime-Optimized Serving Engine (ROSE) to serve models ran...
Perplexity(@perplexity_ai) · 6.5 分
Perplexity 推出自研推理引擎 ROSE,支持从嵌入模型到万亿参数大模型的高效服务,并集成 CuTeDSL 以加速 GPU 内核定制,优化在 NVIDIA Hopper 和 Blackwell 架构上的性能。
已收录 4 条与 CuTeDSL 相关的内容,按评分排序。
PyTorch 2.13发布,引入FlexAttention加速、CuTeDSL后端、内存优化等,显著提升多平台性能与分布式训练效率。
入选理由:FlexAttention在Apple Silicon上实现最高12倍加速,提升稀疏模式性能。
Perplexity leverages NVIDIA's CUTLASS Python stack to optimize its inference models, significantly enhancing the performance of large-scale language models.
入选理由:Perplexity开发了ROSE推理引擎,支持从嵌入到万亿参数LLM的模型服务。
Perplexity has launched its in-house inference engine ROSE, enabling efficient serving from embedding models to trillion-parameter LLMs, with CuTeDSL integration for faster GPU kernel customization.
入选理由:Perplexity 自主研发了推理引擎 ROSE,提升大模型服务效率。
The tweet only prompts users to read the research blog, provides no concrete content, has low information density, and cannot be assessed for technical value.
入选理由:该推文仅为引流至研究博客的公告。