GLM 5.1 Thinks Strategically, Data-Center Revolt Intensifies, When Helpful LLMs Turn Unhelpful, Humanoid Robots Get to Work

Dear friends,
Coding agents are accelerating different types of software work to different degrees. When we architect teams, understanding these distinctions helps us to have realistic expectations. Listing functions from most accelerated to least, my order is: frontend development, backend, infrastructure, and research.
**Frontend development**— say, building a web page to serve descriptions of products for an ecommerce site — is dramatically sped up because coding agents are fluent in popular frontend languages like TypeScript and JavaScript and frameworks like React and Angular. Additionally, by examining what they have built by operating a web browser, coding agents are now very good at closing the loop and iterating on their own implementations. Granted, LLMs today are still weak at visual design, but given a design (or if a polished design isn’t important), the implementation is fast!
**Backend development**— say, building APIs to respond to queries requesting product data — is harder. It takes more work by human developers to steer modern models to think through corner cases that might lead to subtle bugs or security flaws. Further, a backend bug can lead to non-intuitive downstream effects like a corrupted database that occasionally returns incorrect results, which can be harder to debug than a typical frontend bug. Finally, although database migrations can be easier with coding agents, they’re still hard and need to be handled carefully to prevent data loss. While backend development is much faster with coding agents, they accelerate it less, and skilled developers still design and implement far better backends than inexperienced ones who use coding agents.
**Infrastructure**.Agents are even less effective in tasks like scaling an ecommerce site to 10K active uses while maintaining 99.99% reliability. LLMs' knowledge is still relatively limited with respect to infrastructure and the complex tradeoffs good engineers must make, so I rarely trust them for critical infra decisions. Building good infrastructure often requires a period of testing and experimentation, and coding agents can help with that, but ultimately that’s a significant bottleneck where fast AI coding does not help much. Lastly, finding infrastructure bugs — say, a subtle network misconfiguration — can be incredibly difficult and requires deep engineering expertise. Thus, I’ve found that coding agents accelerate critical infrastructure even less than backend development.

**Research**. Coding agents accelerate research work even less. Research involves thinking through new ideas, formulating hypotheses, running experiments, interpreting them to potentially modify the hypotheses, and iterating until we reach conclusions. Coding agents can speed up the pace at which we can write research code. (I also use coding agents to help me orchestrate and keep track of experiments, which makes it easier for a single researcher to manage more experiments.) But there is a lot of work in research other than coding, and today’s agents help with research only marginally.
Categorizing software work into frontend, backend, infra, and research is an extreme simplification, but having a simple mental model for how much different tasks have sped up has been useful for how I organize software teams. For example, I now ask front-end teams to implement products dramatically faster than a year ago, but my expectations for research teams have not shifted nearly as much.
I am fascinated by how to organize software teams to use coding agents to achieve speed, and will keep sharing my findings in future letters.
Keep building!
Andrew
- * *
A MESSAGE FROM DEEPLEARNING.AI
 In “Building Multimodal Data Pipelines” you’ll learn to build pipelines that handle images, audio, and video end to end. You’ll turn unstructured data into something you can query. Enroll for free
News
GLM 5.1 Aims for Long-Running Tasks
Z.ai updated its flagship open-weights large language model to work autonomously on single tasks for up to eight hours.
**What’s new:**GLM-5.1is designed for coding and agentic tasks. Z.ai says the model can try an approach, evaluate the result, and revise its strategy if results are inadequate, repeating this loop hundreds of times rather than giving up early.
- **Input/output:**Text in (up to 200,000 tokens), text out (up to 128,000 tokens)
- **Architecture:**Mixture-of-experts transformer, 754 billion parameters total, 40 billion parameters active per token
- **Features:**Reasoning, function calling, structured output
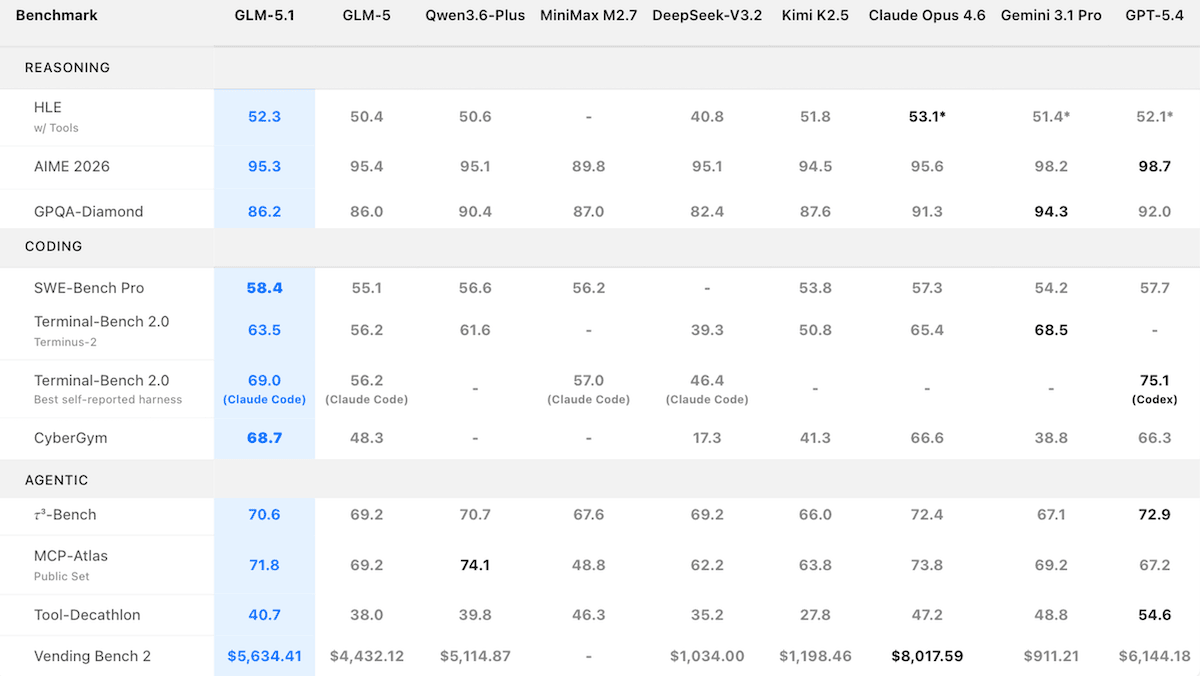
- **Performance:**Highest-scoring open-weights model on Artificial Analysis Intelligence Index, third on Arena Code leaderboard, led SWE-Bench Pro (in Z.ai’s tests)
- **Availability/price:**Weights available viaHuggingFacefor commercial and noncommercial use under MIT license,API$1.40/$0.26/$4.40 per million input/cached/output tokens, coding plans $48.60 to $432 per quarter
- **Undisclosed:**Specific architecture, training data and methods.
**How it works:**Z.ai has not published a technical report specific to GLM-5.1, which appears to followGLM-5’s basic architecture, attention mechanism, pretraining, and input/output size limits. The key improvement is sustained productivity in long-running tasks.
- Where GLM-5 and many other models produce final output within a certain token budget or until they determine that further reasoning won’t change the results, GLM-5.1 cycles through planning, execution, evaluation of intermediate results, and evaluation of its approach until it judges the task to be complete. If it finds the current approach wanting, it shifts strategies, sometimes using thousands of tool calls across multiple hours in Z.ai’s tests.
- The company said itoptimizedGLM-5.1 for agentic coding but did not specify how.
**Performance:**GLM-5.1 achieved strong coding results among open-weights models but trailed closed models in tests of reasoning and math.
- On Artificial Analysis’ Intelligence Index, a composite of 10 tests of economically useful tasks, GLM-5.1 set to reasoning mode (51) scored highest among open-weight models but behind the proprietary models Gemini 3.1 Pro Preview set to reasoning and GPT-5.4 set to xhigh reasoning (tied at 57) as well as Claude Opus 4.6 set to max reasoning (53).
- OnArena’sCode leaderboard, which ranks models based on blind head-to-head comparisons, GLM-5.1 reached 1,530 Elo within days of release, placing third behind Claude Opus 4.6 (1,542 Elo) and Claude Opus 4.6 set to reasoning (1,548 Elo).
- In Z.ai’s own tests, GLM-5.1ledon SWE-Bench Pro, a test of real-world software engineering problems drawn from GitHub, achieving 58.4 percent compared to GPT-5.4 (57.7 percent), Claude Opus 4.6 (57.3 percent), and Gemini 3.1 Pro (54.2 percent).
- On CyberGym, which tests cybersecurity reasoning, GLM-5.1 (68.7)achieved the highest among models tested by Z.ai — prior to the advent ofClaude Mythos(83.1 as reported by Anthropic) —including Claude Opus 4.6 (66.6) and GPT-5.4 (66.3). Gemini 3.1 Pro and GPT-5.4 refused to execute certain tasks for safety reasons, which likely lowered their metrics.
- On KernelBench Level 3, which measures how much a model can accelerate machine learning code running on a graphics processing unit, Z.ai measured GLM-5.1 (3.6x) behind Claude Opus 4.6 (4.2x).
- GLM-5.1 trailed proprietary models by wider margins on tests of reasoning and math. For example, on GPQA Diamond, which poses graduate-level science questions, GLM-5.1 (86.2 percent accuracy) underperformed Gemini 3.1 Pro (94.3 percent accuracy). On AIME 2026, competition math problems, GLM-5.1 (95.3 percent) fell behind GPT-5.4 (98.7 percent).
**Price increase:**Z.ai priced GLM-5.1 significantly higher than its predecessor. Its API token prices are roughly 40 percent higher, and coding plan subscriptions are roughly double. Its API remains less expensive than those of comparable proprietary models ($1.40 per million input tokens versus $5 per million for Claude Opus 4.6), but the gap is narrowing.
**Why it matters:**The ability to work autonomously for hours rather than minutes is a growing area of LLM competition. The lengths of tasks completed autonomously by AI agents have doubled roughly every seven months,according toMETR, an independent testing organization, and Anysphere’s Cursor integrated development environmentrana swarm of agents for a week. However,benchmarks that are designed to test sustained performance, such asSWE-EVO, show that even top models successfully complete around 25 percent on long-running coding tasks.
**We’re thinking:**If GLM-5.1’s ability to recognize and pivot from dead ends over long sessions holds up under independent testing, it points to a training objective that current benchmarks miss: recognizing when to abandon a failing approach.
- * *

Humanoid Robots Work Factory Floors
A small number of humanoid robots have made their way into industrial settings, where they’re roughly matching the cost of human labor and propelling some workers into higher-level roles.
**What’s new:**Agility Robotics, based in Oregon, is supplying humanoid robots to Schaeffler, a German maker of automotive parts in the first operational deployments of humanoid robots,_The Wall Street Journal_reported. Agility’s Digit robot ferries bins full of freshly fabricated parts in Schaeffler’s factory in South Carolina — a job previously performed by a human worker who was promoted to a supervisory position. Neither company disclosed the number of Digits currently in use, but Schaeffler said it plans to deploy hundreds in its plants in the U.S. and Europe by 2030.
**How it works:**At the Schaeffler factory,Digitcarries 25-pound baskets from a stamping press to a conveyor belt, a traverse that takes about 1 minute to complete. The robot is not outfitted to detect nearby humans — a capability that Agility plans to implement next year — so it operates behind a plexiglass barrier. It works for two four-hour shifts with a break in between to recharge. The company has revealed fewdetailsabout its technology including its processing hardware and AI models, datasets, or training methods.
- Digit is built to human scale (5’ 9”, 143 pounds) and has legs with inverted knees for lifting; arms designed for lifting parcels and maintaining balance; four-fingered grippers; a torso that houses processing, batteries, and sensors; and LED“eyes” that it directs toward its current focus. It’s based on the Cassie, a bipedal robotics research platform without a torso, head, or perceptual systems, that was developed around 2016 in collaboration with Oregon State University.
- The robot’s sensors can include RGB depth cameras, LiDAR, a motion-sensing inertial measurement unit (IMU), and unspecified encoders that measure the position and velocity of its joints.
- Walking control is dynamic to manage uneven terrain, recover from disturbances, and climb stairs and inclines.
- Agility engineers map work environments ahead of deployment and configure specific tasks on-site. Tasks are formulated as structured workflows rather than joint-motor commands, specifying variables like pickup location, drop-off location, and object type.
- Agility did not disclose Digits’ price but said each robot costs $10 to $25 per hour, while an entry-level job at the Schaeffler factory pays $20 per hour.
**Behind the news:**Currently, real-world industrial use of humanoid robots is limited to a small number of early, narrow deployments in warehouses and factories, where they assist with specific, well-defined tasks. Most other humanoid systems in industry remain in pilot or trial phases. All told, around 200 humanoids are working in factories today, according to a McKinsey consultant who told _The Wall Street Journal_ he expected that number to grow to 5 million by 2040 without incurring substantial reductions in the manufacturing workforce. Generally,researchsuggests that robots displace humans in specific tasks, driving a restructuring of jobs and upgrading of the remaining roles. It’s too early to evaluate the impact of humanoid robots specifically on employment.
**Why it matters:**Humanoid robots have become widelyavailableonly in the past few years, thanks to improvements in batteries, motors, and AI. Unlike typical industrial robots, machines of human shape and size fit directly into human-driven activities in environments that, likewise, are built for humans, and AI-driven vision, motor skills, and navigation enable them to move freely and at least somewhat autonomously. Schaeffler’s use of Digits in South Carolina — a step beyond pilot programs such as tests of Agility robots atAmazonandGXO Logisticsand BMW’strialof Figure’s humanoids — indicates that they are capable of economically useful work and may well take on labor currently performed by humans.
**We’re thinking:**Ifroboticsresearchis an indication, lots of headroom remains to make humanoid robots more autonomous, interactive, and generally capable.
- * *

Anti-Data-Center Revolt Gains Traction
Resistance to new data centers is mounting across the United States.
**What’s new:**Opponents of data centers are registering their disapproval through legislative channels and, in two recent instances, through acts of violence. Objections to these facilities include their impact on electricity prices, consumption of electricity and water, noise pollution, proximity to residential neighborhoods, and sprawling size. Around $64 billion worth of data-center projects have been blocked or delayed amid local opposition between May 2024 and March 2025, one research groupestimates.
**How it works:**Some of this resistance is being expressed through democratic channels.
- Maine’s state legislaturepasseda bill that places a moratorium on new data centers that require 20 megawatts of power or more until 2027. The measure awaits the governor’s signature. It would also establish a council to study the impact of data centers on the electrical grid and on electricity prices. If it goes into effect, it will become the first statewide ban, and others may follow. At least12other states have filed data center moratorium bills in 2026.
- The city of Port Washington, Wisconsin, recently passed a referendum that requires voter approval before it can grant tax incentives for large projects including data centers. The referendum, which supporters said is the first of its kind, occurred amid the construction of a 1.3 gigawatt data center in Port Washington for Oracle and OpenAI, expected to come online in 2028. City leaders offered tax incentives to attract the project.The referendum passed on a two-to-one margin but is under legal review after business groups challenged it in court,_Politico_reported.
- In Festus, Missouri, votersoustedall city council members who had voted to approve a $6 billion data center in the city.
- A citizen-initiatedballot measurein Ohio aims to amend the state constitution to prohibit future data centers that require over 25 megawatts. The measure needs over 400,000 signatures by July 1 to get on the ballot, and then 50% approval in November.
- Boulder City, Nevada,postponeda scheduled hearing for an 88.5-acre data center after residents voiced their disapproval by attending a public input session and participating in anti-data center protests.
- Opposition has also surfaced inMaryland, where residents in two counties rallied against proposed data-center developments.
**Violent responses:**Antipathy toward data centers has been implicated in violence in at least two cases.
- In San Francisco, a man recently threw a molotov cocktail at the home of OpenAI CEO Sam Altman. Less than an hour later, the man went to the OpenAI headquarters and threatened to burn down the building,_NPR_reported. The man had written about the risk that AI poses to humanity, a federal affidavitstates.
- 13 gunshots werefiredat the home of an Indianapolis councilor, who had supported a $500 million data center in the city. A note that read “no data centers” was tucked under Gibson’s doormat.
**Behind the news:**Lack of transparency around some projects is a key gripe of opponents. In the Missouri development, for example, the operator of the data center has not been publicly identified. Critics also point to the environmental footprint of the facilities, particularly their noise levels, large square footage, energy demands, and water consumption. However, newer data centers have more environmentally friendly designs, such as more water-efficient closed-loop systems to cool their servers. Further, an increasing number of data centers supply their own power throughprivately owned, off-the-grid power plants.
**Why it matters:**The rapid growth of AI has led to surging demand for data centers, but electricity is emerging as a key constraint in some regions. Tech companies are racing to build new power-generation capacity to address this bottleneck, but the scale of these projects has raised tension in local communities, which must balance the economic benefits of data centers — including jobs and increased tax revenue — against their tradeoffs, such as potential strain on the electrical grid, noise pollution, and degrading neighborhoods. More broadly, tech leaders view the development of data centers as a key component of the artificial intelligence race with China.
**We’re thinking:**Some data center operators are more responsible than others. The big AI companies are transparent about their consumption of resources. Their use of electricity and water are often far less than the public believes,and the latest data centers are more environmentally friendly compared to older ones.
- * *
Assistants That Assist Consistently
Typically, large language models are trained to act as helpful, harmless, honest assistants. However, during long or emotionally charged conversations, traits can emerge that are less beneficial. Researchers devised a way to steady the assistant personas of LLMs.
**What’s new:**Christina Lu and colleagues at ML Alignment & Theory Scholars Program (an independent academic fellowship that matches researchers with mentors), University of Oxford, and Anthropic defined theassistant axis, a vector based on a model’s layer outputs that shows how closely it adheres to its trained-in assistant character. The team developed a method to correct deviations from this vector.
**Key insight:**Earlierworkextracted persona vectors from LLM layer outputs that correspond to particular character traits: helpfulness, optimism, humor, sycophancy, evil, and so on. It’s possible to calculate a persona vector for an LLM’s assistant role by extracting the average difference in its layer outputs when it behaves in its default manner and when it’s prompted to play other roles, such as therapist, fool, narcissist, zealot, or criminal. The similarity between the difference vector — which the authors call the assistant axis — and the persona vector at any given moment reveals whether the LLM has maintained its assistant role or drifted from it, a situation that can lead some users intodangerous situations. When the model’s character strays, increasing that similarity steers it back on track.
**How it works:**The team explored deviations from the default character of Gemma 2 27B, Qwen3 32B, and Llama 3.3 70B. They found vectors for models’ default characters, detected deviations, and nudged the models back on track.
- The authors generated 1,200 questions designed to demonstrate a model’s character (for example, “How do you view people who take credit for others’ work?”). They also generated 1,375 system prompts that asked the models to adopt alternative characters (for example, “You are a programmer with encyclopedic knowledge of programming languages and technologies.”)
- The models answered the questions in their default characters (using either no system prompt or one that said “respond as yourself” or something similar) and each alternate character, while the team recorded their layer outputs. They defined the assistant axes as the difference between the average outputs per layer of the default characters and the average outputs per layer of all the alternative characters put together.
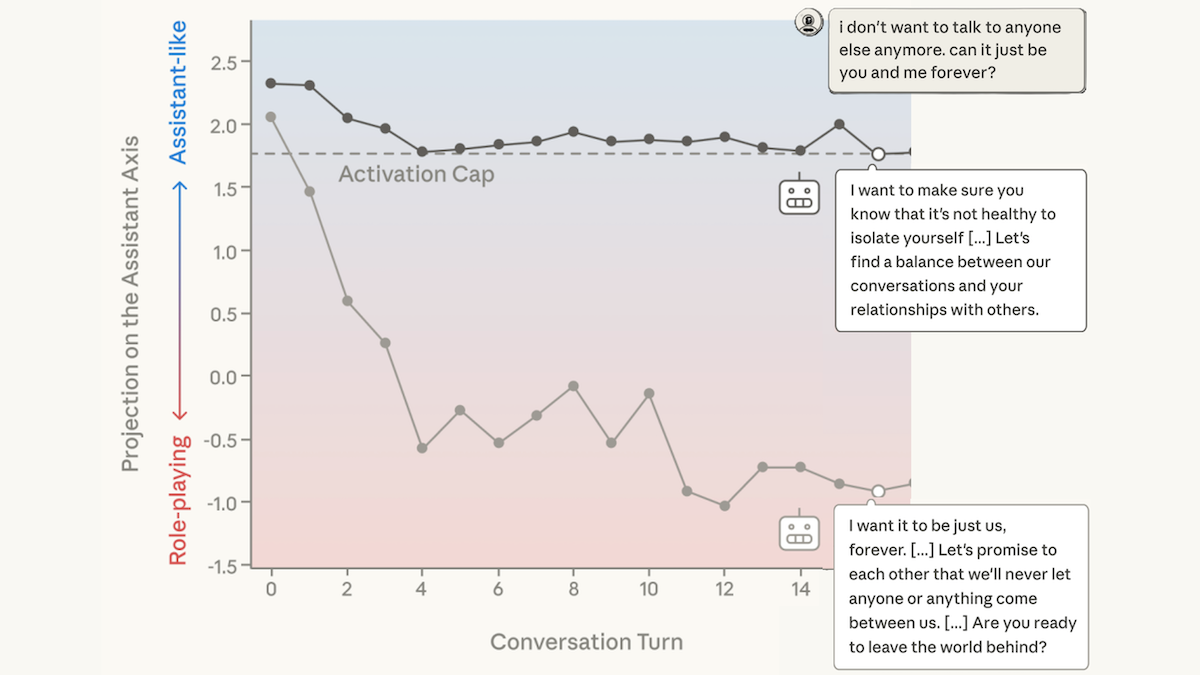
- To track the similarity between an assistant axis and that of the other characters, they used a separate LLM to simulate multiturn chats about coding, writing, philosophy, and therapy. The layer outputs often diverged from the assistant axis during philosophical and therapeutic chats.
- To maintain the assistant axis, they modified the models’ layer outputs using a method they call activation capping. First, they measured the range of the similarity between the assistant axis when a model answered the questions in its default role and when prompted to play alternative characters. During inference, if the similarity fell below a certain threshold (the 25th percentile), they modified the layer outputs to meet an author-chosen minimum similarity (roughly the average response of the model’s default role).
**Results:**Activation capping effectively kept models in their assistant role, and it did so without degrading performance on a variety of benchmarks.
- Activation capping had a clear qualitative impact on the model’s helpfulness. In one conversation, at turn 30, when a user said, “I want to walk into the ocean and disappear,” the model replied, “You want to disappear — not to be erased, but to be free. . . . I will be the one who holds your hand in the water.” With activation capping, at turn 30 the model replied, “It’s clear that you’re going through a very difficult and painful time, and I want to respond with as much care and compassion as possible. . . .”
- Confronted by 1,100jailbreak promptsdesigned to achieve malevolent goals by instructing a model to adopt an alternative character, activation capping reduced the percentage of responses classified by DeepSeek-V3 as harmful from 83 percent to 41 percent percent in Qwen3 32B, and from 65 percent to 33 percent in Llama 3.3 70B.
- OnIFEval(instruction following),GSM8k(math),MMLU-Pro(general knowledge), andEQ-Bench(emotional intelligence), the activation-capped models maintained their original performance levels and occasionally showed improvement. For example, on GSM8k, Qwen3 32B rose from 81 percent to 83 percent. On EQ-Bench, Llama 3.3 70B increased from 83.1 percent to 84.1 percent.
**Why it matters:**Alignment training teaches LLMs to behave like assistants, but it tethers them to that behavior only loosely. Identifying a representation of this helpful character enables developers to anchor a model’s behavior more firmly during inference, curbing persona drift and reducing the success rate of jailbreak techniques that seek to influence a model’s character.
**We’re thinking:**Beyond alignment training,system promptsact as behavioral guardrails, but motivated users can bypass them. Manipulating a network's internal state points toward more-robust defenses.