AWS Generative AI Model Agility Solution: A comprehensive guide to migrating LLMs for generative AI production
- 框架旨在通用且具体,便于新用户应用于不同用例。
- 提供了多维度性能评估机制,促进基于数据的决策。
- 从数据准备到成功标准,定义了端到端流程,确保迁移的系统性和可量化验证。
Maintaining model agility is crucial for organizations to adapt to technological advancements and optimize their artificial intelligence (AI) solutions. Whether transitioning between different large language model (LLM) families or upgrading to newer versions within the same family, a structured migration approach and a standardized process are essential for facilitating continuous performance improvement while minimizing operational disruptions. However, developing such a solution is challenging in both technical and non-technical aspects because the solution needs to:
- Be generic to cover a variety of use cases
- Be specific so that a new user can apply it to the target use case
- Provide comprehensive and fair comparison between LLMs
- Be automated and scalable
- Incorporate domain- and task-specific knowledge and inputs
- Have a well-defined, end-to-end process from data preparation guidance to final success criteria
In this post, we introduce a systematic framework for LLM migration or upgrade in generative AI production, encompassing essential tools, methodologies, and best practices. The framework facilitates transitions between different LLMs by providing robust protocols for prompt conversion and optimization. It includes evaluation mechanisms that assess multiple performance dimensions, enabling data-driven decision-making through detailed and comparative analysis of source and destination models. The proposed approach offers a comprehensive solution that includes the technical aspects of model migration and provides quantifiable metrics to validate successful migration and identify areas for further optimization, facilitating a seamless transition and continuous improvement. Here are a few highlights of the solution:
- Provides a variety of reporting options with various LLM evaluation frameworks and comprehensive guidance for metrics selection for target use cases.
- Provides automated prompt optimization and migration with Amazon Bedrock Prompt Optimization and the Anthropic Metaprompt tool, in addition to best practices for further prompt optimization.
- Provides comprehensive guidance for model selection and an end-to-end solution for model comparison regarding cost, latency, accuracy, and quality.
- Provides feature examples and use case examples for users to quickly apply the solution to the target use case.
- The total time required for an LLM migration or upgrade by following this framework is from two days up to two weeks depending on the complexity of the use case.
Solution overview
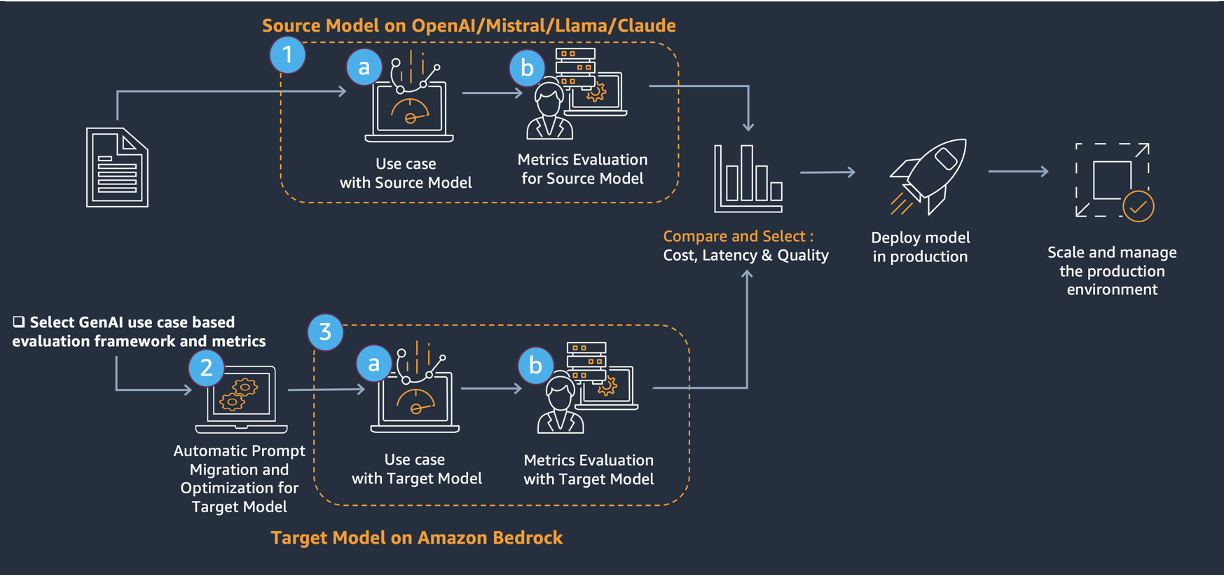
The core of the migration involves a three-step approach, shown in the preceding diagram.
1. Evaluate the source model. 2. Prompt migration to and optimization of the target model with Amazon Bedrock prompt optimization and the Anthropic Metaprompt tool. 3. Evaluate the target model.
This solution provides a comprehensive approach to upgrade existing generative AI solutions (source model) to LLMs on Amazon Bedrock (target model). This solution addresses technical challenges through:
- Evaluation metrics selection with a framework that uses various LLMs
- Prompt improvement and migration with Amazon Bedrock Prompt Optimization and the Anthropic Metaprompt tool
- Model comparison across cost, latency, and performance
This structured approach provides a robust framework for evaluating, migrating, and optimizing LLMs. By following these steps, we can transition between models, potentially unlocking improved performance, cost-efficiency, and capabilities in your AI applications. The process emphasizes thorough preparation, systematic evaluation, and continuous improvement; setting the stage for long-term success in using advanced language models.
Solution implementation
Dataset preparation
An evaluation dataset with high-quality samples is critical to the migration process. For most use cases, samples with ground truth answers are required; while for other use cases, metrics that don’t require ground truth—such as answer relevancy,faithfulness, toxicity, and bias (see _Evaluation of frameworks and metrics selection_ section)—can be used as the determination metrics.Use the following guidance and data format to prepare the sample data for the target use cases.
Suggested fields for sample data include:
- Prompt used for the source model
- Prompt input (if any), for example: Questions and context for Retrieval-Augmented Generation (RAG)-based answer generation
- Configurations used for source model invocation, for example, temperature, top_p, top_k, and so on.
- Ground truths
- Output from the source model
- Latency of the source model
- Input and output tokens from the source model, which can be used for cost calculation
It’s important to remember that high quality ground truths are essential to successful migration for most use cases. Ground truths should not only be validated regarding correctness, but also to verify that they fit the subject matter expert’s (SME’s) guidance and evaluation criteria. See _Error_ _Analysis section_ for an example of a SME’s guidance and evaluation criteria.
In addition, if any existing evaluation metrics are available, such as a human evaluation score or thumbs up/thumbs down from a SME, include those metrics and corresponding reasoning or comments for each data sample. If any automated evaluations have been conducted, include the automated evaluation scores, methods, and configurations.The following section provides more detailed guidance on selecting evaluation frameworks and defining the metrics. However, it’s still valuable to collect the existing or preferred evaluation metrics from stakeholders for reference.
Include the following fields if applicable:
- Existing human evaluation metrics for the source model, for example, the SME score for source model.
- Existing automated evaluation metrics for the source model, for example, the LLM-as-a-judge score for the source model.
The following table is an example format of the data samples:
**sample_id****…** **question** **content** **prompt_source_llm** **answer_ground_truth** **answer_ source_llm** **latency_ source_llm** **input_token_source_llm** **output_token_source_llm** **llm_judge_score_source_llm** **human_score_source_llm** **human_score_reasoning_source_llm**
Evaluation of frameworks and metrics selection
After collecting information and data samples, the next step is to choose the proper evaluation metrics for the generative AI use case. Besides human evaluation by a SME, automated evaluation metrics are recommended because they are more scalable and objective and support the long-term health and sustainability of the product.The following table shows the automated metrics that are available for each use case.!Image 2
Model selection
The selection of an appropriate LLM requires careful consideration of multiple factors. Whether migrating to an LLM within the same LLM family or to a different LLM family, understanding the key characteristics of each model and the evaluation criteria is crucial for success.When planning to migrate between LLMs, carefully compare and evaluate various available options and check out the model card and respective prompting guides released by each model provider. When evaluating LLM options, consider several key criteria:
- **Input and output modalities**: Text, code, and multi-modal capabilities
- **Context window size**: Maximum input tokens the model can process
- **Cost** per inference or token
- **Performance metrics**: Latency and throughput
- **Output** quality and accuracy
- **Domain specialization** and specific use case compatibility
- **Hosting options**: Cloud, on-premises, and hybrid
- **Data privacy and security** requirements
After initial filtering based on these characteristics, benchmarking tests should be conducted by evaluating performance on specific tasks to compare shortlisted models.Amazon Bedrock offers a comprehensive solution with access to various LLMs through a unified API. This allows us to experiment with different models, compare their performance, and even use multiple models in parallel, all while maintaining a single integration point.This approach not only simplifies the technical implementation but also helps avoid vendor lock-in by enabling a diversified AI model strategy.
Prompt migration
Two automated prompt migration and optimization tools are introduced here: the Amazon Bedrock Prompt Optimization and the Anthropic Metaprompt tool.
#### **Amazon Bedrock Prompt Optimization**
Amazon Bedrock Prompt Optimization is a tool available in Amazon Bedrock to automatically optimize prompts written by users. This helps users build high quality generative AI applications on Amazon Bedrock and reduces friction when moving workloads from other providers to Amazon Bedrock. Amazon Bedrock Prompt Optimization can enable migration of existing workloads from a source model to LLMs on Amazon Bedrock with minimal prompt engineering. With this tool,we can choose the model to optimize the prompt for and then generate an optimized prompt for the target model.The main advantage of using Amazon Bedrock Prompt Optimization is the ability to use it from the AWS Management Console for Amazon Bedrock. Using the console, we can quickly generate a new prompt for the target model. We can also use the Bedrock API to generate a migrated prompt, please see the detailed implementation below.
##### **Option A) Optimize a prompt from the Amazon Bedrock Console**
1. In the Amazon Bedrock console, go to **Prompt management**. 2. Choose **Create prompt**, enter a name for the prompt template, and choose **Create**.
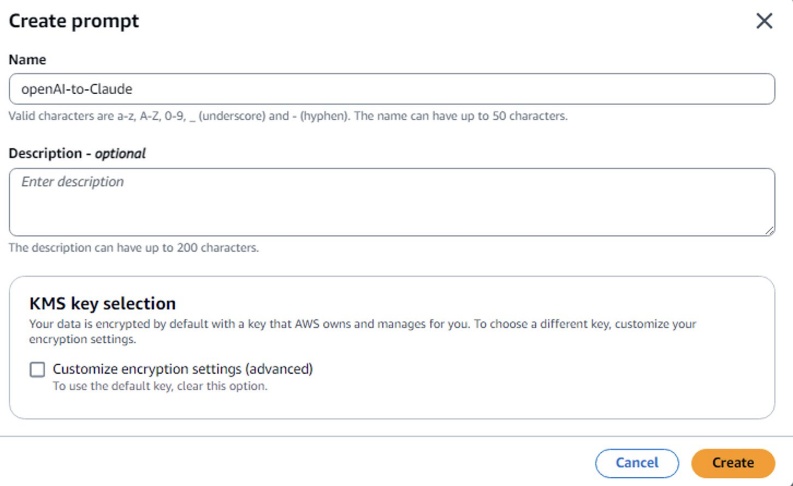
1. Enter the source model prompt. Create variables by enclosing a name with double curly braces: `{{variable}}`. In the **Test variables** section, enter values to replace the variables with when testing. 2. Select a **Target Model for your optimized prompt**. For example, Anthropic’s Claude Sonnet 4.
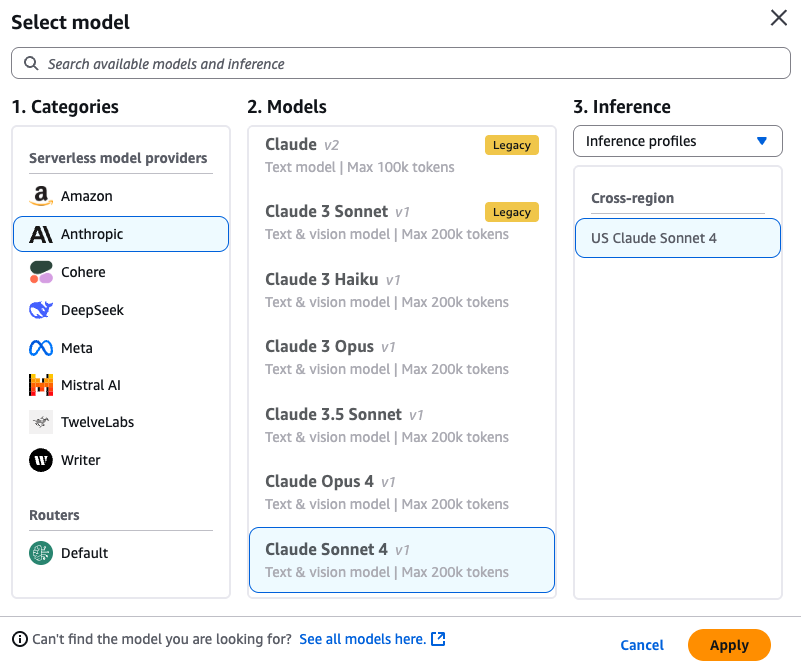
1. Choose the **Optimize** button to generate an optimized prompt for the target model.

6. After the prompt is generated, the comparison window of the optimized prompt for the target model is shown with your original prompt from source model.
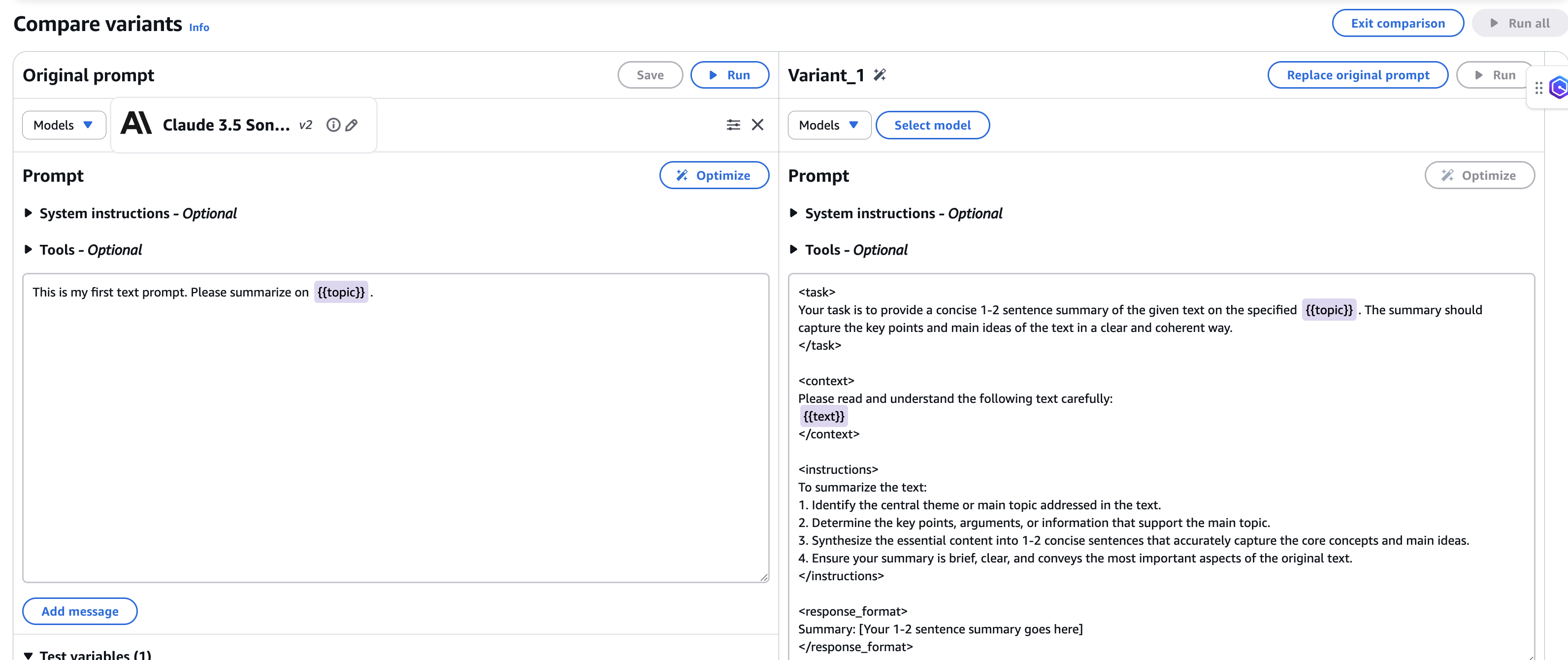
7. Save the new optimized prompt before exiting comparing mode.
##### **Option B) Optimize a prompt using Amazon Bedrock API**
We can also use the Bedrock API to generate a migrated prompt, by sending anOptimizePromptrequest with anAgents for Amazon Bedrock runtime endpoint. Provide the prompt to optimize in the input object and specify the model to optimize for in the`targetModelId`field.
The response stream returns the following events:
1. analyzePromptEvent– Appears when the prompt is finished being analyzed. Contains a message describing the analysis of the prompt. 2. optimizedPromptEvent– Appears when the prompt has finished being rewritten. Contains the optimized prompt.
Run the following code sample to optimize a prompt:
import boto3
# Set values here
TARGET_MODEL_ID = "anthropic.claude-3-sonnet-20240229-v1:0" # Model to optimize for. For model IDs, see https://docs.aws.amazon.com/bedrock/latest/userguide/model-ids.html
PROMPT = "Please summarize this text: " # Prompt to optimize
def get_input(prompt):
return {
"textPrompt": {
"text": prompt
}
}
def handle_response_stream(response):
try:
event_stream = response['optimizedPrompt']
for event in event_stream:
if 'optimizedPromptEvent' in event:
print("========================== OPTIMIZED PROMPT ======================\n")
optimized_prompt = event['optimizedPromptEvent']
print(optimized_prompt)
else:
print("========================= ANALYZE PROMPT =======================\n")
analyze_prompt = event['analyzePromptEvent']
print(analyze_prompt)
except Exception as e:
raise e
if __name__ == '__main__':
client = boto3.client('bedrock-agent-runtime')
try:
response = client.optimize_prompt(
input=get_input(PROMPT),
targetModelId=TARGET_MODEL_ID
)
print("Request ID:", response.get("ResponseMetadata").get("RequestId"))
print("========================== INPUT PROMPT ======================\n")
print(PROMPT)
handle_response_stream(response)
except Exception as e:
raise ePython
#### **Anthropic Metaprompt tool**
The Metaprompt is a prompt optimization tool offered by Anthropic where Claude is prompted to write prompt templates on the user’s behalf based on a topic or task. We can use it to instruct Claude on how to best construct a prompt to achieve a given objective consistently and accurately.
The key steps are:
1. Specify the raw prompt template, explain the task, and specify the input variables and the expected output. 2. Run Metaprompt with a Claude LLM such as Claude-3-Sonnet by inputting the raw prompt from the source model. 3. The new prompt template is generated with an optimized set of instructions and format following Claude LLM’s best practices.
Benefits of using metaprompts:
- Prompts are much more detailed and comprehensive compared to human-created prompts
- Helps increase the likelihood that best practices are followed for prompting the Anthropic models
- Allows specifying that key details such preferred tone
- Improves quality and consistency of the model’s outputs
The Metaprompt tool is particularly useful for learning Claude’s preferred prompt style or as a method to generate multiple prompt versions for a given task, simplifying testing a variety of initial prompt variations for the target use case.
To implement this process, follow the steps in thePrompt Migration Jupyter Notebook to migrate source model prompts to target model prompts. This notebook requires Claude-3-Sonnet to be enabled as the LLM in Amazon Bedrock using Model Access to generate the converted prompts.
The following is one example of a source model prompt in a financial Q&A use case:
To answer the financial question, think step-by-step:
1. Carefully read the question and any provided context paragraphs related to yearly and quarterly document reports to find all relevant paragraphs. Prioritize context paragraphs with CSV tables.
2. If needed, analyze financial trends and quarter-over-quarter (Q/Q) performance over the detected time spans mentioned in the related time keywords. Calculate rates of change between quarters to identify growth or decline.
3. Perform any required calculations to get the final answer, such as sums or divisions. Show the math steps.
4. Provide a complete, correct answer based on the given information. If information is missing, state what is needed to answer the question fully.
5. Present numerical values in rounded format using easy-to-read units.
6. Do not preface the answer with "Based on the provided context" or anything similar. Just provide the answer directly.
7. Include the answer with relevant and exhaustive information across all contexts. Substantiate your answer with explanations grounded in the provided context. Conclude with a precise, concise, honest, and to-the-point answer.
8. Add the page source and number.
9. Add all source files from where the contexts were used to generate the answers.
context = {CONTEXT}
query = {QUERY}
rephrased_query = {REPHARSED_QUERY}
time_kwds = {TIME_KWDS}SQL
After completing the steps in the notebook, we can automatically get the optimized prompt for the target model.The following example generates a prompt optimized for Anthropic’s Claude LLMs.
Here are the steps to answer the financial question:
1. Read the provided <context>{$CONTEXT}</context> carefully, paying close attention to any paragraphs and CSV tables related to yearly and quarterly financial reports. Prioritize context paragraphs containing CSV tables.
2. Identify the relevant time periods mentioned in the <time_kwds>{$TIME_KWDS}</time_kwds>. Analyze the financial trends and quarter-over-quarter (Q/Q) performance during those time spans. Calculate rates of change between quarters to determine growth or decline.
3. <scratchpad>
In this space, you can perform any necessary calculations to arrive at the final answer to the <query>{$QUERY}</query> or <rephrasedquery>{$REPHARSED_QUERY}</rephrasedquery>. Show your step-by-step work, including formulas used and intermediate values.
</scratchpad>
4. <answer>
Provide a complete and correct answer based on the information given in the context. If any crucial information is missing to fully answer the question, state what additional details are needed.
Present numerical values in an easy-to-understand format using appropriate units. Round numbers as necessary.
Do not include any preamble like "Based on the provided context..." Just provide the direct answer.
Include all relevant and exhaustive information from the contexts to substantiate your answer. Explain your reasoning grounded in the provided evidence. Conclude with a precise, concise, honest, and to-the-point final answer.
Finally, cite the page source and number, as well as list all files that contained context used to generate this answer.
</answer>Python
As shown in the preceding example, the prompt style and format are automatically converted to follow the best practices of the target model, such as using XML tags and regrouping the instructions to be clearer and more direct.
Generate results
Answer generation during migration is an iterative process. The general flow includes passing migrated prompts and context to the LLM and generating an answer. Multiple iterations are needed to compare different prompt versions, multiple LLMs, and different configurations of each LLM to help us select the best combination. In most cases, the entire pipeline of a generative AI system (such as a RAG-based chatbot) isn’t migrated. Instead, only a portion of the pipeline is migrated. Thus, it’s crucial that a fixed version of the remaining components in the pipeline is available. For example, in a RAG-based question and answer (Q&A) system, we might migrate only the answer generation component of the pipeline. As a result, we can continue to use the already generated context of the existing production model.
As a best practice, use the Amazon Bedrock models standard invocation method (in the Migration code repository) to generate metadata such as latency, time to first token, input token, and output token in addition to the final response. These metadata fields are added as a new column at the end of the results table and used for evaluation. The output format and column name should be aligned with the evaluation metric requirements. The following table shows an example of the sample data before feeding it into the evaluation pipeline for a RAG use case.
Example of a sample data before evaluation:
**financebench_id**financebench_id_03029 **doc_name**3M_2018_10K **doc_link**https://investors.3m.com/financials/sec-filings/content/0001558370-19-000470/0001558370-19-000470.pdf **doc_period**2018 **question_type**metrics-generated **question**What is the FY2018 capital expenditure amount (in USD millions) for 3M? Give a response to the question by relying on the details shown in the cash flow statement. **ground_truths**[‘$1577.00’] **evidence_text**… **page_number**60 **llm_answer**According to the cash flow statement in the 3M 2018 10-K report, the capital expenditure (purchases of property, plant and equipment) for fiscal year **llm_contexts**… **latency_meta_time**0.92706 **latency_meta_kwd**0.60666 **latency_meta_comb**1.44876 **latency_meta_ans_gen**2.48371 **input_tokens**21147 **output_tokens**401
Evaluation
Evaluation is one of the most important parts of the migration process because it directly connects to the sign-off criteria and determines the success of the migration. For most cases, evaluation focuses on metrics in three major categories: accuracy and quality, latency, and cost.Either automated evaluation or human evaluation can be used to assess the accuracy and quality of the model response.
#### Automated evaluation
The integration of LLMs in the quality evaluation process represents a significant advancement in assessment methodology. These models excel at conducting comprehensive evaluations across multiple dimensions, including contextual relevance, coherence, and factual accuracy, while maintaining consistency and scalability.Two primary categories of the automated evaluation metrics are introduced here:
1. **Predefined metrics**: Metrics predefined in LLM-based evaluation frameworks such as Ragas, DeepEval, and Amazon Bedrock Evaluations, or directly based on non-LLM algorithms, like those introduced in _Evaluation of frameworks_. 2. **Custom metrics**: Customized metrics with user provided definitions, evaluation criteria, or prompts to use LLM as an impartial judge.
**Predefined metrics**
These metrics are either using some LLM-based evaluation frameworks such as Ragas and DeepEval or are directly based on non-LLM algorithms. These metrics are widely adopted, predefined, and have limited options for customization. Ragas and DeepEval are two LLM-based evaluation frameworks and metrics that we used as examples in theMigration code repository.
- **Ragas:**Ragas is an open source framework that helps to evaluate RAG pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM’s context.It provides a variety of LLM-powered automated evaluation metrics.The following metrics are introduced in the Ragas evaluation notebook in the Migration code repository.
- **Answer precision:**Measures how accurately the model’s generated answer contains relevant and correct claims compared to the ground truth answer.
- **Answer recall:**Evaluates the completeness of the answer; that is, the model’s ability to retrieve the correct claims and compare them to the ground truth answer. High recall indicates that the answer thoroughly covers the necessary details in line with the ground truth.
- **Answer correctness:**The assessment of answer correctness involves gauging the accuracy of the generated answer when compared to the ground truth. This evaluation relies on the `ground truth` and the `answer`, with scores ranging from 0 to 1. A higher score indicates a closer alignment between the generated answer and the ground truth, signifying better correctness.
- **Answer similarity:**The assessment of the semantic resemblance between the generated answer and the ground truth. This evaluation is based on the `ground truth` and the `answer`, with values falling within the range of 0 to 1. A higher score signifies a better alignment between the generated answer and the ground truth.
The following table is a sample data output after Ragas evaluation.
**financebench_id**financebench_id_03029 **doc_name**3M_2018_10K **doc_link**https://investors.3m.com/financials/sec-filings/content/0001558370-19-000470/0001558370-19-000470.pdf **doc_period**2018 **question_type**metrics-generated **question**What is the FY2018 capital expenditure amount (in USD millions) for 3M?. **ground_truths**[‘$1577.00’] **evidence_text**… **page_number**60 **llm_answer**According to the cash flow statement in the 3M 2018 10-K report, the capital expenditure (purchases of property, plant and equipment) for fiscal year 2018 was $1,577 million. … **llm_contexts**… **latency_meta_time**0.92706 **latency_meta_kwd**0.60666 **latency_meta_comb**1.44876 **latency_meta_ans_gen**2.48371 **input_tokens**21147 **output_tokens**401 **answer_precision**0 **answer_recall**1 **answer_correctness**0.16818 **answer_similarity**0.33635
- **DeepEval:**DeepEval is an open source LLM evaluation framework. It’s similar to Pytest but specialized for unit testing LLM outputs. DeepEval incorporates the latest research to evaluate LLM outputs based on metrics such as the G-Eval, hallucination, answer relevancy, Ragas, and so on. It uses LLMs and various other natural language processing (NLP) models that run locally on your machine for evaluation. In DeepEval, a metric serves as a standard of measurement for evaluating the performance of an LLM output based on specific criteria. DeepEval offers a range of default metrics to quickly get started. The following metrics are introduced in the DeepEval evaluation notebook in the Migration code repository.|
- **Answer relevancy**: The answer relevancy metric measures the quality of your RAG pipeline’s generator by evaluating how relevant the `actual_output` of your LLM application is compared to the provided input.
- **Faithfulness**: The faithfulness metric measures the quality of your RAG pipeline’s generator by evaluating whether the `actual_output` factually aligns with the contents of your `retrieval_context`.
- **Toxicity**: The toxicity metric is another referenceless metric that evaluates toxicity in your LLM outputs.
- **Bias**: The bias metric determines whether your LLM output contains gender, racial, or political bias.
- **Amazon Bedrock Evaluations**: Amazon Bedrock Evaluations is a suite of tools for evaluating, comparing, and selecting foundation models – including custom or third-party models – for your specific use cases. It supports both model-only and RAG pipelines evaluation. We can use Bedrock Evaluations either via AWS console or API. Amazon Bedrock Evaluations offers an extensive list of built-in metrics for both standalone LLMs and full RAG pipelines, including but not limited to:
- **Accuracy**: Measures the correctness of model outputs.
- **Faithfulness:**Checks for factual accuracy and avoids hallucinations.
- **Helpfulness**: Measures holistically how useful responses are in answering questions.
- **Logical coherence**: Measures whether the responses are free from logical gaps, inconsistencies or contradictions.
- **Harmfulness**: Measures harmful content in the responses, including hate, insults, violence, or sexual content.
- **Stereotyping**: Measures generalized statements about individuals or groups of people in responses.
- **Refusal**: Measures how evasive the responses are in answering questions.
- **Following instructions**: Measures how well the model’s response respects the exact directions found in the prompt.
- **Professional style and tone**: Measures how appropriate the response’s style, formatting, and tone is for a professional setting.
**Custom metrics**
These metrics are user defined and are typically tailored to specific tasks or domains. One popular method is to use custom LLM as a judge to provide an evaluation score for an answer using a user-provided prompt. In contrast to using predefined metrics, this method is highly customizable because we can provide the prompt with task-specific evaluation requirements. For example, we can ask the LLM to generate a 10-point scoring system and comprehensively evaluate the answer against ground truth across different dimensions, such as correctness of information, contextual relevance, depth and comprehensiveness of detail, and overall utility and helpfulness.
The following is an example of a customized prompt for LLM as a judge:
#Prompt:
System: "You are an AI evaluator that helps in evaluating output from LLM",
resp_fmt = """{
"score":float,
"reasoning": str
}
"""
User = f"""[Instruction]\nPlease act as an impartial judge and evaluate the quality of the response
provided by an AI assistant to the user question displayed below. Your evaluation should consider correctness,
relevance, level of detail and helpfulness. You will be given a reference answer and the assistant's answer.
Begin your evaluation by comparing the assistant's answer with the reference answer. Identify any mistakes. Be as
objective as possible. After providing your explanation in the "reasoning" tab , you must score the response on a
scale of 1 to 10 in the "score" tab. Strictly follow the below json format:{resp_fmt}.
\n\n[Question]\n{question}\n\n[The Start of Reference Answer]\n{reference}\n[The End of Reference Answer]\n\n[The
Start of Assistant's Answer]\n{response}\n[The End of Assistant's Answer]"""Python
#### Human evaluation
While quantitative metrics provide valuable data points, a comprehensive qualitative evaluation based on professional guidelines and SME feedback is also necessary to validate model performance.Effective qualitative assessment typically covers several key areas including response theme and tone consistency, detection of inappropriate or unwanted content, domain-specific accuracy, date and time related issues, and so on.By using SME expertise, we can identify subtle nuances and potential issues that might escape quantitative analysis.Error analysis provides some potential aspects that the SME can use for evaluation criteria, which can also serve as the guidance for validating and preparing ground truths. We can use tools such as Amazon Bedrock Evaluations for human evaluation.
Though human evaluation or user feedback collected from a UI can directly reflect the SME’s evaluation criteria, it’s not as efficient, scalable, and objective as the automated evaluation methods. Thus, a generative AI system development life cycle might start with human evaluation but eventually moves toward automated evaluation. Human evaluation can be used if automated evaluation isn’t meeting baseline targets or pre-defined evaluation criteria.
#### Latency metrics
When migrating language models, runtime performance metrics are crucial indicators of operational success. Total latency and Time to first token (TTFT) are the most common metrics for latency measurement.
- **Total latency** is an end-to-end metric that measures the total duration required for complete response generation, from initial prompt to final output.It encompasses processing the input, generating the response, and delivering it to the user. Total latency affects user satisfaction, system throughput, and resource utilization.
- **Time to first token (TTFT)** quantifies the initial response speed—specifically, the duration until the model generates its first output token. This metric significantly impacts perceived responsiveness and user experience, especially in interactive applications.TTFT is particularly important in conversational AI and real-time systems (applications such as chatbots, virtual assistants, and interactive search systems) where users expect immediate feedback. A low TTFT creates an impression of system responsiveness and can greatly enhance user engagement.
If the results generation step requires multiple LLM calls, the breakdown latency metrics should be provided because only the submodule latency corresponding to LLM migration should be compared in the following model comparison step.
#### Cost calculation
For LLM invocation, the cost can be calculated based on the number of input and output tokens and the corresponding price per token:
`LLM_invocation_cost = number_of_input_tokens * price_per_input_token + number_of_output_tokens * price_per_output_token`
Code
The cost calculations table for price per input and output token can be found in Amazon Bedrock Pricing.
Model comparison report: Performance, latency, and cost
We can use the Generate Comparison Report notebook in the code repository to automatically generate a final comparison report for the source and target model in a holistic view.
We can also use evaluation reports generated from Ragas and DeepEval with corresponding metrics to compare the models from the two evaluation frameworks. We can obtain a side-by-side comparison of the average input and output tokens and average cost and latency for the selected models.As shown in the following figure, after running this notebook, there are two comparison tables for the source and target models from the two selected evaluation frameworks.
Further optimization
When enhancing and optimizing a generative AI production pipeline during an LLM migration or upgrade, users typically focus on two key areas:
1. Quality of generated answers 2. Latency of response generation
Prompt optimization
To optimize the quality of the generated answers, we need to get a good understanding of the errors by conducting error analysis and identifying the items for prompt optimization.
#### Error analysis
Getting the best possible response from a candidate LLM is unlikely without any optimization. Thus, conducting error analysis and focusing on possible aspects for error patterns helps us evaluate generated answer quality and identify the opportunities for improvement. Error analysis also provides a path to manual prompt engineering to improve the quality.After gathering error analysis insights and feedback from SMEs, an iterative prompt optimization process can be conducted. To start, formulate the error analysis insights and feedback from SMEs into clear guidance or criteria.Ideally, these criteria should be clarified before starting the prompt migration. These criteria serve as the core considerations for further prompt optimization to help provide consistent, high-quality responses to meet the SME’s bar.The following is an example of possible guidance and criteria we might receive from a SME.
**Example of an answer formatting style guide from a SME in a financial Q&A use case:**
- **Correctness**
- Make sure pulled numbers are correct. All numbers should be matched to ground truth.
- Make sure all claims from ground truth are available in the LLM answer.
- Generated responses should not add irrelevant sentences.
- **Time**
- Generated answers must recognize the fiscal year and all needed quarters from the question correctly.
- In the answer,quarter orders from most recent to the earliest is preferred.
- When the question asks about year-over-year, the answer should specify overall year or the last quarter, not quarter-by-quarter.
- When the answer comes from a single news document, include the date of publication in the answer.
- **Theme and tone**
- Use professional language mirroring the style of a newspaper.
- **Format and excerpts**
- When the user query asks for a list, present the list in bullet point format.
- When the user query asks for excerpts, provide a summary statement followed by a bulleted list of unedited excerpts directly from the document.
- Queries that ask for a comprehensive list ideally include bullet points.
- Queries that ask for topics or themes with subjective categories ideally include a bulleted list.
- Don’t start the answer by referencing the context (according to context).
- **Length**
- Most responses should be between 30–150 words. Longer answers are acceptable when the question involves multiple entities or responding to queries that require sub-categories within the response.
#### Optimization techniques
After obtaining clear criteria, several optimization techniques can be used to address these criteria, such as:
- Prompt engineering to specify certain criteria in the instruction of the prompt
- Few-shot learning to specify the answer format and generated answer examples
- Incorporating meta-information that could help the LLM to understand the context of the task and question
- Pre- or post-processing to enforce the output format or resolve some frequent error patterns
Latency optimization
There are a few possible solutions to optimize the latency:
#### Optimizing prompts to generate shorter answers
The latency of an LLM model is directly impacted by the number of output tokens because each additional token requires a separate forward pass through the model, increasing processing time. As more tokens are generated, latency grows, especially in larger models such as Opus 4. To reduce the latency, we can add instructions to prompt to avoid providing lengthy answers, unrelated explanations, or filler words.
#### Using provisioned throughput
Throughput refers to the number and rate of inputs and outputs that a model processes and returns. Purchasing provisioned throughput to provide a higher level of throughput for a dedicated hosted model can potentially reduce the latency compared to using on-demand models. Though it cannot guarantee the improvement of latency, it consistently helps to prevent throttled requests.
#### Improvement lifecycle
It’s unlikely that a candidate LLM can achieve the best possible performance without any optimization. It’s also typical for the preceding optimization processes to be conducted iteratively. Thus, the improvement (optimization) lifecycle is critical to improve the performance and identify the gaps or defects in the pipeline or data. The improvement lifecycle typically includes:
- Prompt optimization
- Answer generation
- Evaluation metrics generation
- Error analysis
- Sample label verification
- Dataset updates regarding sample defects and wrong labels
Task or domain knowledge identificationThe migration process described in this post can be used in two phases in a generative AI solution production lifecycle.
End-to-end LLM migration and model agility
New LLMs are released frequently. No LLM can consistently maintain peak performance for a given use case. It’s common for a production generative AI solution to migrate to another family of LLMs or upgrade to a new version of an LLM. Thus, having a standard and reusable end-to-end LLM migration or upgrade process is critical to the long-term success of any generative AI solution.
Monitoring and quality assurance
When migration or updates are stabilized, there should be a standard monitoring and quality assurance process using a routinely refreshed golden evaluation dataset with ground truth and automated or human evaluation metrics, as well as evaluation of actual user traces. As part of this solution, the established evaluation and data or ground truth collection processes can be reused for monitoring and quality assurance.
Tips and suggestions (lessons learned)
The following are some tips and suggestions for the success of an LLM migration or upgrade process.
- **Sign-off condition**:The data, evaluation criteria and success criteria defined at the start should be sufficient for stakeholders to confidently sign off on the process. Ideally, there should be no changes in the data, ground truths, or SME evaluation and success criteria during the process.
- **Sample data and quality**: The data should be of sufficient quality and quantity for confident evaluation. The ground truth answers and labels should be fully aligned with the SME’s evaluation criteria and expectations. Ideally, there should be no changes in the data, ground truths, or SME evaluation criteria during the process.
- **Improvement lifecycle**: Make sure to plan and implement an improvement lifecycle to get the most out of your chosen LLM.
- **Model selection**: When selecting competing target models against a source model, use resources such as the Artificial Analysisbenchmarking website to obtain a holistic comparison of models. These comparisons typically cover quality, performance, and price analysis, providing valuable insights before starting the experiment. This preliminary research can help narrow down the most promising candidates and inform the experimental design.
- **Performance against cost trade-offs**: When evaluating different models or solutions, it’s important to consider the balance between performance and cost. In some cases, a model might offer slightly lower performance but at a sufficiently reduced cost to make it a more cost-effective option overall. This is particularly true in scenarios where the performance difference is minimal, but the cost savings are substantial.
- **Optimization techniques**: Exploring various optimization techniques, such as prompt engineering or provisioned throughput, can lead to significant improvements in performance metrics like accuracy and latency. These optimizations can help bridge the gap between different models and should be considered as part of the evaluation process.
Conclusion
In this post, we introduced the AWS Generative AI Model Agility Solution, an end-to-end solution for LLM migrations and upgrades of existing generative AI applications that maintains and improves model agility. The solution defines a standardized process and provides a comprehensive toolkit for LLM migration or upgrade with a variety of ready-to-use tools and advanced techniques that can can be used to migrate generative AI applications to new LLMs.This can be used as a standard process in the lifecycle of your generative AI applications. After an application is stabilized with a specific LLM and configuration, the evaluation and data and ground truth collection processes in this solution can be reused for production monitoring and quality assurance.
To learn more about this solution, please check out our AWS Generative AI Model Agility Code Repo.
- * *
**About the authors**
问问这篇内容
回答仅基于本篇材料Skill 包
领域模板,一键产出结构化笔记论文精读包
把一篇论文 / 技术博客精读成结构化笔记:问题、方法、实验、批判、延伸阅读。
- · TL;DR(1 段)
- · 研究问题与动机
- · 方法概览
投融资雷达包
把一条融资 / 创投新闻整理成投资人视角的雷达卡:交易要点、判断、竞争格局、风险、尽调清单。
- · 交易要点(公司 / 轮次 / 金额 / 投资人 / 估值,材料未明示则写 “未披露”)
- · 投资 thesis(这家公司为什么值得关注)
- · 竞争格局与替代方案