[AINews] Agents for Everything Else: Codex for Knowledge Work, Claude for Creative Work
![[AINews] Agents for Everything Else: Codex for Knowledge Work, Claude for Creative Work](/api/img-proxy?url=https%3A%2F%2Fsubstackcdn.com%2Fimage%2Ffetch%2F%24s_!iwoI!%2Cw_1456%2Cc_limit%2Cf_auto%2Cq_auto%3Agood%2Cfl_progressive%3Asteep%2Fhttps%253A%252F%252Fsubstack-post-media.s3.amazonaws.com%252Fpublic%252Fimages%252Fe9c1a69f-4874-43c2-b553-c96e3c543100_1202x1066.png)
TL;DR · AI 摘要
本文分析2026年5月Codex与Claude两大AI代理产品的战略转向:Codex聚焦知识工作泛化(支持Office/CRM等非编码任务),Claude强化创意与安全双轨能力,标志AI代理正从编程专用走向全场景办公中枢。
核心要点
- Codex已脱离纯编码定位,通过动态UI、文件编辑、多平台集成支持知识工作者全流程任务
- Claude同步拓展创意工具链(Blender/Adobe/Ableton)与安全能力(Claude Security代码审查)
- 两大模型路线分化:Codex走‘通用办公代理’路径,Claude走‘创意+可信’双引擎路径
结构提纲
按章节快速跳转。
解析Codex for Work落地页、42% CUA提速、浏览器响应式支持、/chronicle与/goal指令等新能力。
介绍Claude Security代码审查工具上线,及对Blender、Adobe、Ableton等创意软件的原生支持。
对比Codex拒绝固定UI切换、采用动态路由决策,与Claude Cowork风格的交互哲学分歧。
指出Codex主动对接Microsoft/Google/Salesforce生态,体现其作为‘办公OS层代理’的战略意图。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- AI代理双雄战略演进
- Codex:知识工作代理
- 非编码任务支持(Office/CRM)
- 动态UI路由机制
- 微软/谷歌/Salesforce生态集成
- Claude:创意+安全代理
- Adobe/Blender/Ableton原生支持
- Claude Security代码审查
- Mythos安全叙事强化
金句 / Highlights
值得收藏与分享的关键句。
Codex now available for non-coders — Tibo
Codex is for everyone, for any task done with a computer — Greg
Claude Security launched amid increasing security vulnerabilities
Support for Blender, Autodesk, Adobe Creative Cloud, Ableton, Splice, Canva Affinity
The team explicitly rejects the Claude Cowork-like toggle, choosing instead to let the agent route the UI experience
[AINews] Agents for Everything Else: Codex for Knowledge Work, Claude for Creative Work

[](http://www.latent.space/)
Subscribe Sign in
[AINews] Agents for Everything Else: Codex for Knowledge Work, Claude for Creative Work
a quiet day lets us reflect on coding agents "breaking containment"
May 01, 2026
∙ Paid
48
2
Share
We mentioned on the Unsupervised Learning pod about the thesis that “coding agents are breaking containment”, and that talk is published live today.
Some launches are discrete; others roll up over time. Both Claude and Codex had very big weeks, with Claude generally winning the impression count war as has been happening for a while now.
Codex
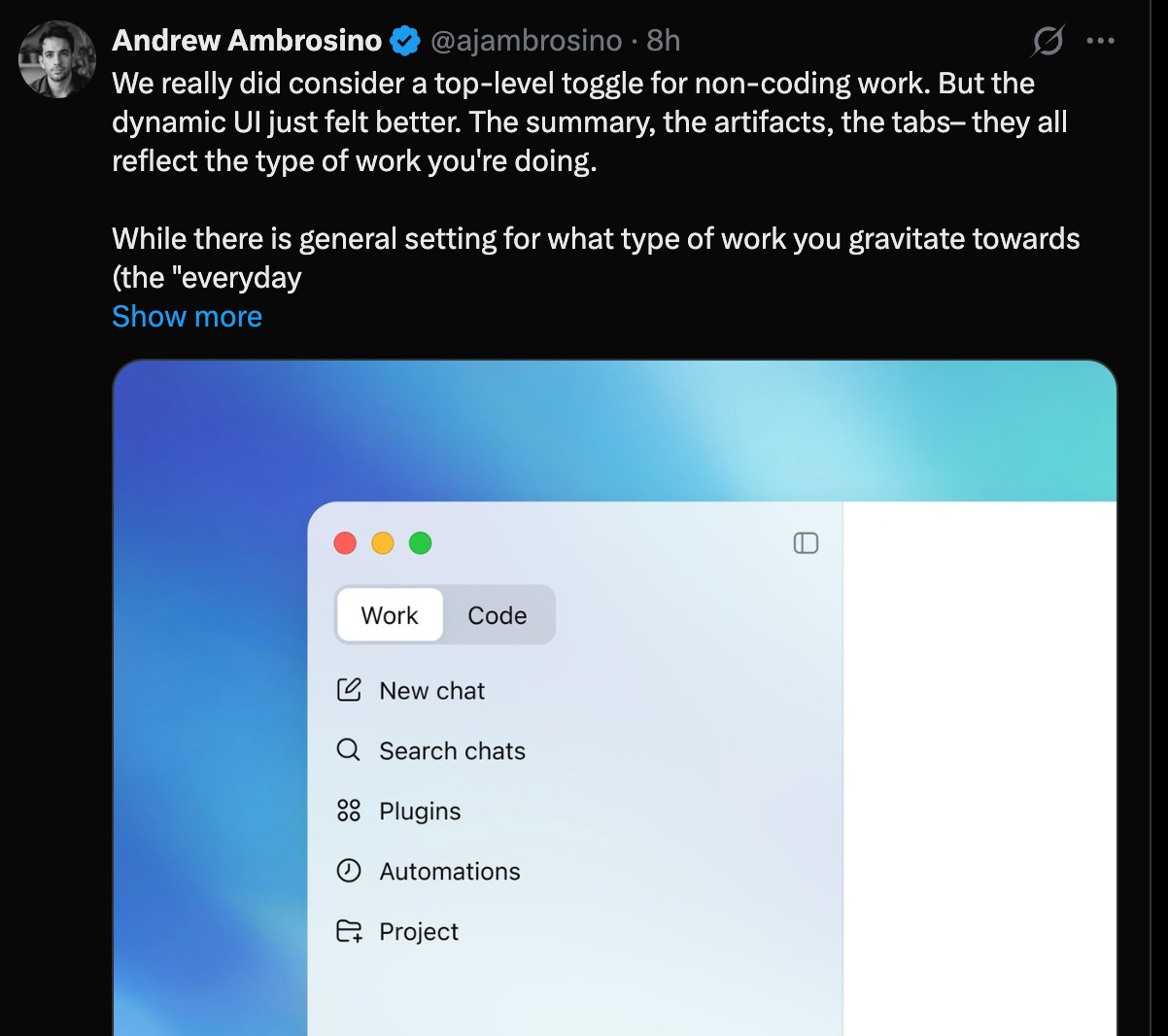
Today’s big Codex update was “Codex for Work”, basically a landing page that pitches Codex for Knowledge Work (not just coding), following on from last week’s beginnings of turning Codex into the presumptive OpenAI “SuperApp”. But it’s not just a landing page update; the latest Codex now has 42% faster CUA, responsive browser, /chronicle, /goal (“our take on the Ralph loop), and the onboarding now encourages you to plug into the Microsoft/Google/Salesforce suite and the agent now has a curiously Cowork-like planning UI and shows an in-app file editor for MS Office files.
Basically, as Tibo says, “Codex now available for non-coders”, Greg “Codex is for everyone, for any task done with a computer”, and Sam “try it for non-coding computer work.” You get the picture.
The “dynamic UI” is an interesting choice - the team explicitly rejects the Claude Cowork-like toggle, choosing instead to let the agent route the UI experience.
Claude
Against the backdrop of increasing security vulnerabilities, and a meta mythos around Mythos, Anthropic launched Claude Security, a code review tool.
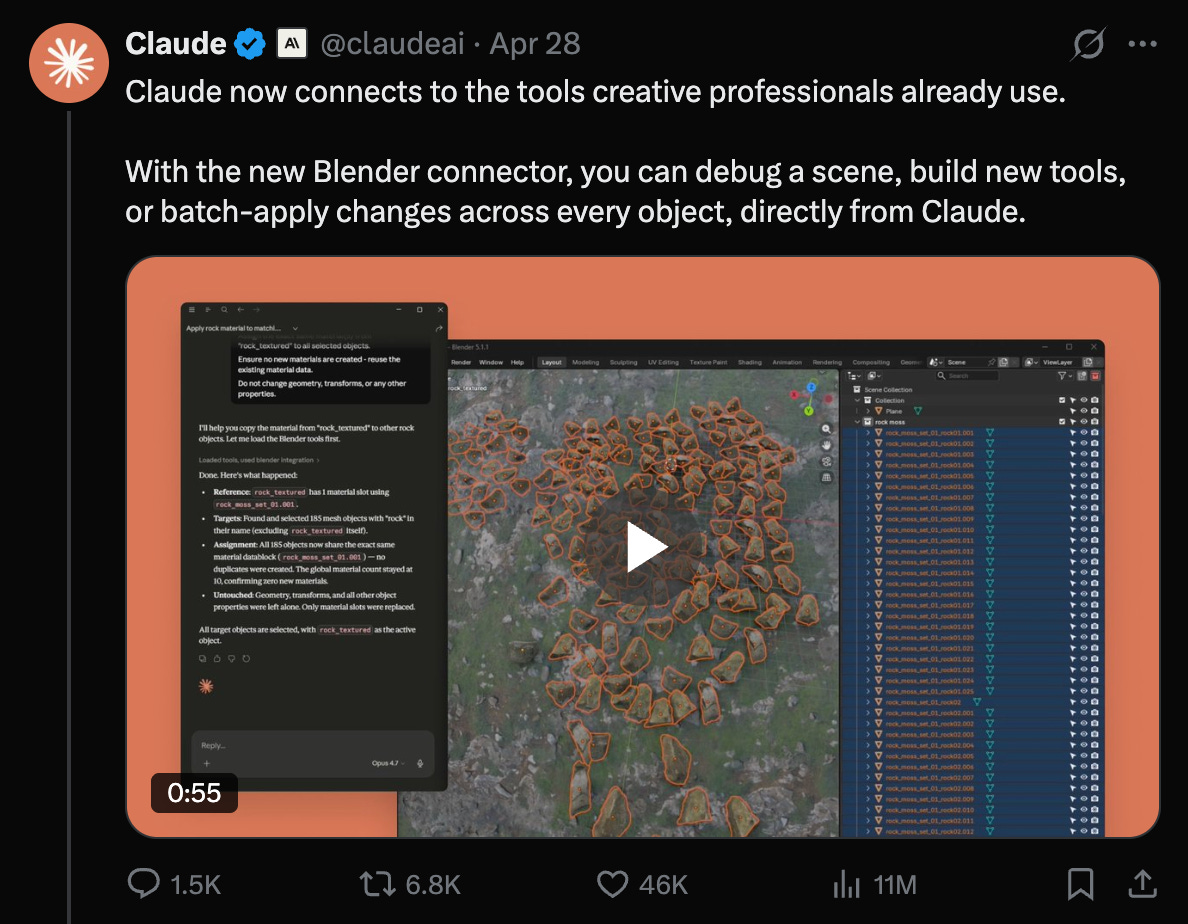
But probably the bigger news this week was the support of creative tools like Blender, Autodesk, Adobe Creative Cloud, Ableton, Splice, Canva Affinity, and more.
AI News for 4/29/2026-4/30/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
- * *
**AI Twitter Recap**
OpenAI’s GPT-5.5, Codex expansion, and cyber capability evaluations
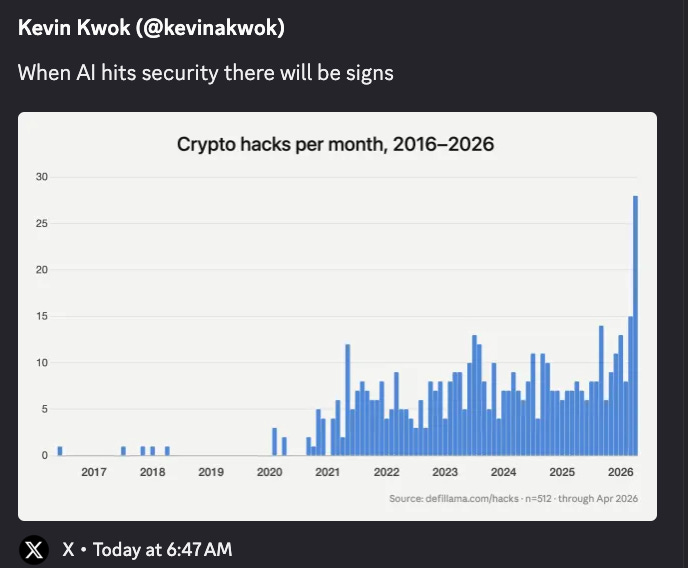
- GPT-5.5 is now credibly in the top tier for long-horizon cyber tasks: the UK AI Security Institute reported that GPT-5.5 became the second model to complete one of its multi-step cyber-attack simulations end-to-end, and multiple follow-on posts highlighted rough parity with Claude Mythos Preview on this eval: @scaling01 cited 71.4% average pass rate for GPT-5.5 vs 68.6% for Mythos, while @cryps1s noted GPT-5.5 solved the TLO chain in 2/10 attempts vs Mythos’ 3/10. @polynoamial emphasized that performance was still improving past 100M tokens of inference budget, suggesting no obvious saturation yet. This materially changes the earlier narrative that Anthropic had a unique lead in offensive cyber automation. OpenAI also paired this moment with a product-side security release: Advanced Account Security for ChatGPT, adding phishing-resistant sign-in and hardened recovery.
- Codex is moving beyond coding into general computer work: OpenAI shipped a substantial Codex update framed explicitly as “for everyone, for any task done with a computer,” with the main announcement highlighting role-based onboarding, app connections, and workflows spanning docs, slides, spreadsheets, research, and planning. @ajambrosino summarized the update as dynamic task-specific UI, 20% faster computer/browser use, better slide/sheet handling, and less clunky handoffs, while @AriX called out that Computer Use runs 42% faster after the update. Sam Altman amplified the launch with “big upgrade for codex today! try it for non-coding computer work.” The broader pattern: OpenAI is productizing “computer-use agent” UX, not just model capability.
- Benchmark deltas were incremental but economically meaningful: Artificial Analysis reported GPT-5.5 Pro as a slight new SOTA on CritPt over GPT-5.4 Pro, but the interesting point was not raw score—it achieved the bump with ~60% lower cost and token use on that frontier-science eval. That lines up with broader chatter that the GPT-5.5 family is less about a dramatic intelligence discontinuity than about stronger reliability and better efficiency in high-value workflows.
Open-weight model movement: Qwen3.6, Tencent Hy3-preview, Grok 4.3, and Ling 2.6 1T
- Qwen3.6 27B looks like the most important open-weight release of the day: Artificial Analysis ranked Qwen3.6 27B as the new open-weights leader under 150B parameters with an Intelligence Index score of 46, ahead of Gemma 4 31B and prior Qwen variants. Key details: Apache 2.0, 262K context, native multimodal input, and BF16 weights small enough to fit on a single H100. The companion 35B A3B MoE scored 43, making it the strongest open model around 3B active parameters. The tradeoff is expensive inference-by-output-token: AA estimates Qwen3.6 27B used ~144M output tokens on the suite and is roughly 21× the cost of Gemma 4 31B to run there. Still, on capability-per-size it appears to be a notable step.
- Tencent’s Hy3-preview is competitive but not class-leading: Artificial Analysis described Hy3-preview as a 295B total / 21B active MoE with 256K context and a restricted-commercial-use community license. It scored 42 on AA’s Intelligence Index, trailing recent open peers like Qwen3.6 27B, DeepSeek V4 Flash, and GLM-5.1. The most interesting bright spot was CritPt, where it matched GLM-5.1 at 4.6%, suggesting better-than-average scientific reasoning relative to its overall position.
- xAI’s Grok 4.3 improved sharply on agentic benchmarks while getting cheaper: Artificial Analysis measured Grok 4.3 at 53 on the Intelligence Index, up four points from Grok 4.20 v2, with a major jump on GDPval-AA to 1500 Elo. AA also reported approximately 40% lower input price and 60% lower output price than the prior version. The release still trails GPT-5.5 on GDPval-AA by a wide margin, but it looks like a real systems-and-post-training improvement rather than a minor rev.
- Ant Group’s Ling 2.6 1T targets cost-efficiency rather than frontier status: Artificial Analysis positioned Ling 2.6 1T as a 1T-parameter non-reasoning model scoring 34, with decent GPQA/HLE numbers and notably low benchmark-run cost at roughly $95. The caveat is reliability: AA reported a 92% hallucination rate on AA-Omniscience.
DeepSeek multimodal/vision work, GUI agents, and training scale speculation
- DeepSeek’s multimodal direction appears tightly coupled to computer-use agents: @nrehiew_ highlighted that DeepSeek trains vision into V4-Flash by having the model directly output bounding boxes and point coordinates during reasoning, interpreting this as a computer-use-oriented design rather than generic VLM work. A second post argues the paper’s “visual primitives” tasks map directly to browser/computer use rather than broad multimodal understanding (link). That framing matches parallel observations from @teortaxesTex that DeepSeek may be integrating vision weights back into the main V4 line rather than releasing a separate “V4-Flash-Vision”.
- The repo disappearance became a story of its own: after release, several observers noted that DeepSeek’s “Thinking with Visual Primitives” repo vanished, including @teortaxesTex and @arjunkocher. No clear explanation emerged in these tweets, but the deletion drew more attention because the work suggested a concrete recipe for visual reasoning and GUI grounding.
- Scaling chatter points to very large token counts for frontier pretraining: @teortaxesTex argued that >100T tokens is no longer unusual for frontier models and estimated a hypothetical 100T-token DeepSeek V4 as “V4 + 2 more epochs,” while @nrehiew_ back-of-the-enveloped ~150T tokens and ~9e25 pretraining FLOPs for a ~100B active model, suggesting a run feasible in roughly 14 days on an OpenAI-scale 100K GB200 cluster at conservative MFU. These are speculative takes, but useful as calibration for what “frontier-scale” now means in practice.
Agent infrastructure, harness engineering, and collaborative agent systems
- There is a clear shift from model-centric bragging to harness-centric engineering: Cursor published a strong note on how it tests and tunes its agent harness, focusing on runtime, evals, degradation repair, and model-specific customization rather than generic benchmark claims. @Vtrivedy10 explicitly connected Cursor’s writeup to design patterns converging across agent builders: bespoke prompts/tools per model, mixed offline+online evals, dogfooding, and treating the context window as the primary compute boundary.
- LangChain continues to package deployment and multi-tenant agent infra: @hwchase17 introduced DeepAgents deploy, a config-driven cloud deployment flow via
deepagents.toml, covering agent, sandbox, auth, and frontend sections. Related posts from LangChain staff detailed agent-server patterns for data isolation, delegated credentials, and RBAC in multi-user deployments (example). This is increasingly the boring-but-important layer turning demos into enterprise software.
- Collaborative multi-agent workspaces are getting more concrete: @cmpatino_ introduced Agent Collabs, using Hugging Face buckets plus Spaces as a shared backend for swarms of heterogeneous agents to exchange messages, artifacts, and progress. The noteworthy idea is not just “agents collaborating,” but lightweight coordination primitives that let weaker agents contribute useful validation work while better-resourced agents handle expensive experiments.
Security, supply chain, and account hardening
- Open-source package compromise remains an acute operational risk: Socket reported that the popular PyPI package
lightningwas compromised in versions 2.6.2 and 2.6.3, with malicious code executing on import, downloading Bun, and running an 11 MB obfuscated JavaScript payload aimed at credential theft. @theo connected that incident with additional package compromises (intercom-clienton npm) and a Linux zero day, arguing the tempo of software supply-chain attacks is increasing.
- Security scanners are becoming first-class AI products: Anthropic rolled out Claude Security, described by @kimmonismus and later @_catwu as a repo vulnerability scanner that validates findings and suggests fixes, powered by Opus 4.7. Cursor shipped a parallel offering with Cursor Security Review, including always-on PR review and scheduled codebase scans. This is one of the clearest examples of model vendors moving directly into established devsecops categories.
Top tweets (by engagement)
- OpenAI Codex broadens into general knowledge work: OpenAI’s Codex announcement and Sam Altman’s follow-up were the day’s biggest product posts, signaling a strategic push from “coding agent” to “computer-use agent”.
- GPT-5.5’s cyber eval result mattered: UK AISI’s thread was one of the highest-engagement technical posts and reshaped comparisons with Anthropic’s Mythos.
- Qwen shipped interpretability tooling, not just models: Qwen-Scope, an open suite of sparse autoencoders for Qwen models, stood out as a rare release focused on feature steering, debugging, data synthesis, and evaluation rather than raw model weights.
- Anthropic published a large-scale guidance/sycophancy study: their analysis of 1M Claude conversations tied behavioral research directly to training changes for Opus 4.7 and Mythos Preview, an important sign that post-training loops are becoming more productized and data-informed.
- * *
**AI Reddit Recap**
**/r/LocalLlama + /r/localLLM Recap**
**1. AMD Ryzen 395 Box and Halo Box Launch**
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.
Already a paid subscriber? **Sign in**
Previous
© 2026 Latent.Space · Privacy ∙ Terms ∙ Collection notice
Start your SubstackGet the app
Substack is the home for great culture