How DoorDash Launches a New Country in One Week

- 将入职流程拆分为独立模块并标准化接口,避免国家逻辑硬编码
- 统一状态管理至单一数据源,解决多表分散导致的进度追踪难题
- 轻量编排层连接模块,支持快速组合新流程,几乎无需新增代码

Skip the guesswork with this MongoDB cheatsheet from Datadog. You’ll get a quick, practical reference for monitoring performance and diagnosing issues in real systems.
Use it to:
- Track key metrics like latency, throughput, and resource utilization
- Monitor MongoDB and Atlas health with the right signals
- Set up dashboards to quickly identify bottlenecks and performance issues
When DoorDash needed to launch Dasher onboarding in Puerto Rico, it took about a week. That wasn’t because they cut corners or threw a huge team at it. It took a week because almost no new code was needed. The steps that Puerto Rican Dashers would go through (identity checks, data collection, compliance validation) already existed as independent modules, battle-tested by thousands of Dashers in other countries. The team assembled them into a new workflow, made one minor customization, and shipped.
And it wasn’t just Puerto Rico. Australia’s migration was completed in under a month. Canada took two weeks, and New Zealand required almost no new development at all.
This speed came from an architectural decision the DoorDash engineering team made when they looked at their growing mess of country-specific if/else statements and decided to stop patching.
They rebuilt their onboarding system around a simple idea. Decompose the process into self-contained modules with standardized interfaces, then connect them through a deliberately simple orchestration layer.
In this article, we will look at how this architecture was designed and the challenges they faced.
_Disclaimer: This post is based on publicly shared details from the DoorDash Engineering Team. Please comment if you notice any inaccuracies._
DoorDash’s Dasher onboarding started simple, with just a few steps serving a single country through straightforward logic. Then the company expanded internationally, and every new market meant new branches in the code.
At one point, three API versions ended up coexisting. V3, the newest, continued calling V2 handlers for backward compatibility and also continued writing to V2 database tables. The system literally couldn’t avoid its own history. All developers have probably seen something like this before, where nobody can fully explain which version handles what, and removing any piece feels dangerous because something else might depend on it.
See the diagram below that shows the legacy system view:
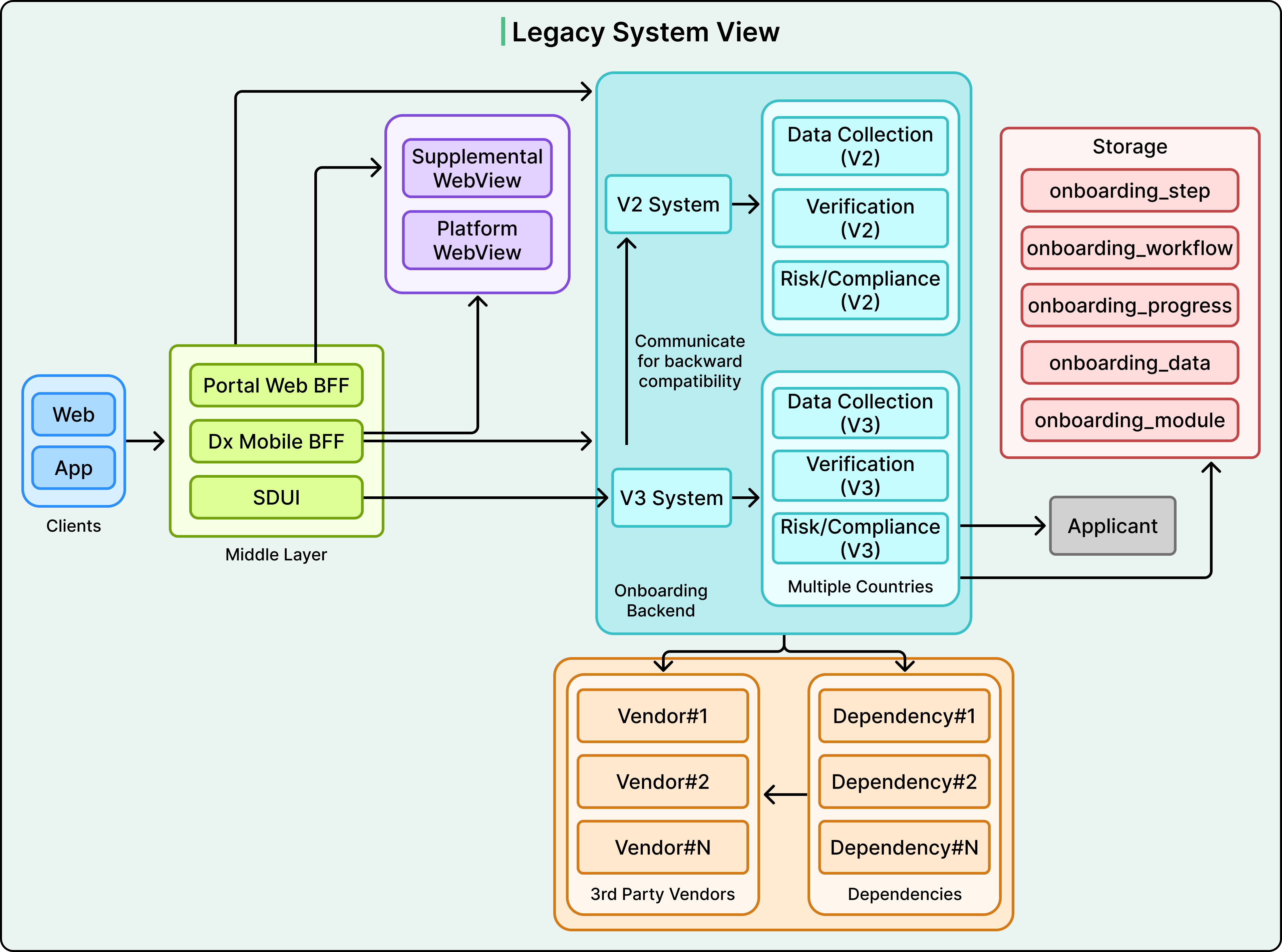
The step sequences themselves were hard-coded, with country-specific logic spread throughout. Business logic started immediately after receiving a request, branching into deep if/else chains based on country, step type, or prior state. Adding a new market meant carefully threading new conditions through this maze of conditions.
Vendor integrations followed no consistent pattern either. Some onboarding steps used internal services, which called third-party vendors. Other steps called vendors directly. This inconsistent layering made testing and debugging unpredictable.
And then there was also the state management problem. Onboarding progress was tracked across multiple separate database tables. Flags like validation_complete = true or documents_uploaded = false lived in different systems. If a user dropped off mid-onboarding and came back later, reconstructing where they actually stood required querying several systems and inferring logic. This frequently led to errors.
The practical cost was that adding a new country took months of engineering effort across APIs, tables, and code branches. Every change carried the risk of breaking something in a market on the other side of the world.
DoorDash’s rebuild was organized around three distinct layers, each with a single responsibility. It’s easy to blur these layers together, but the separation between them is where the real power lives.
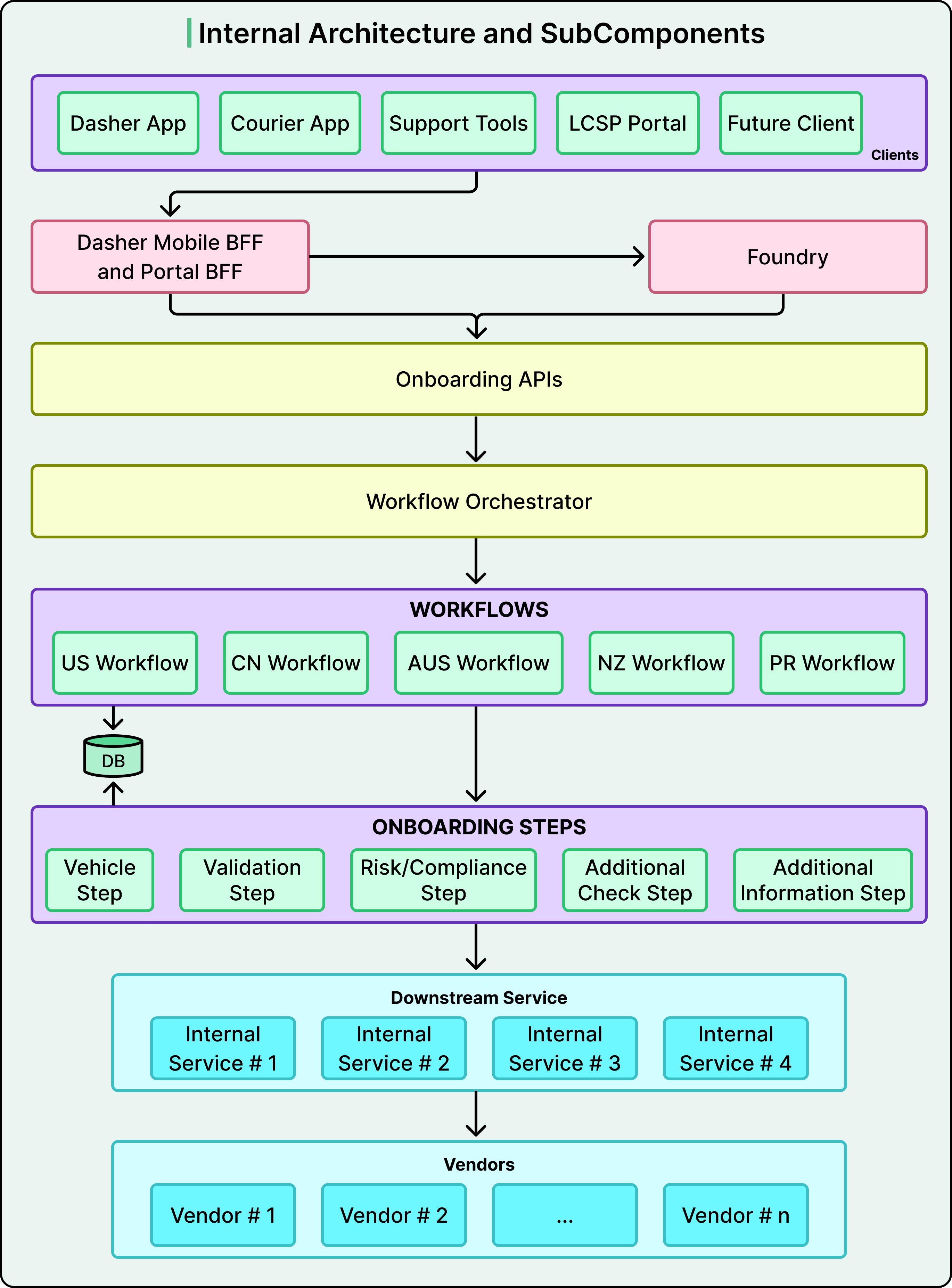
The Orchestrator sits at the top. It’s a lightweight routing layer that looks at context (which country and which market type) and decides which workflow definition should handle the request. That’s all it does. It doesn’t execute steps or manage state. It doesn’t contain business logic either. The main insight here is that the smartest thing about the orchestrator is how little it does. Developers tend to imagine the central controller as the brain of the system. However, in this architecture, the brain is distributed, and the orchestrator is just a traffic cop.
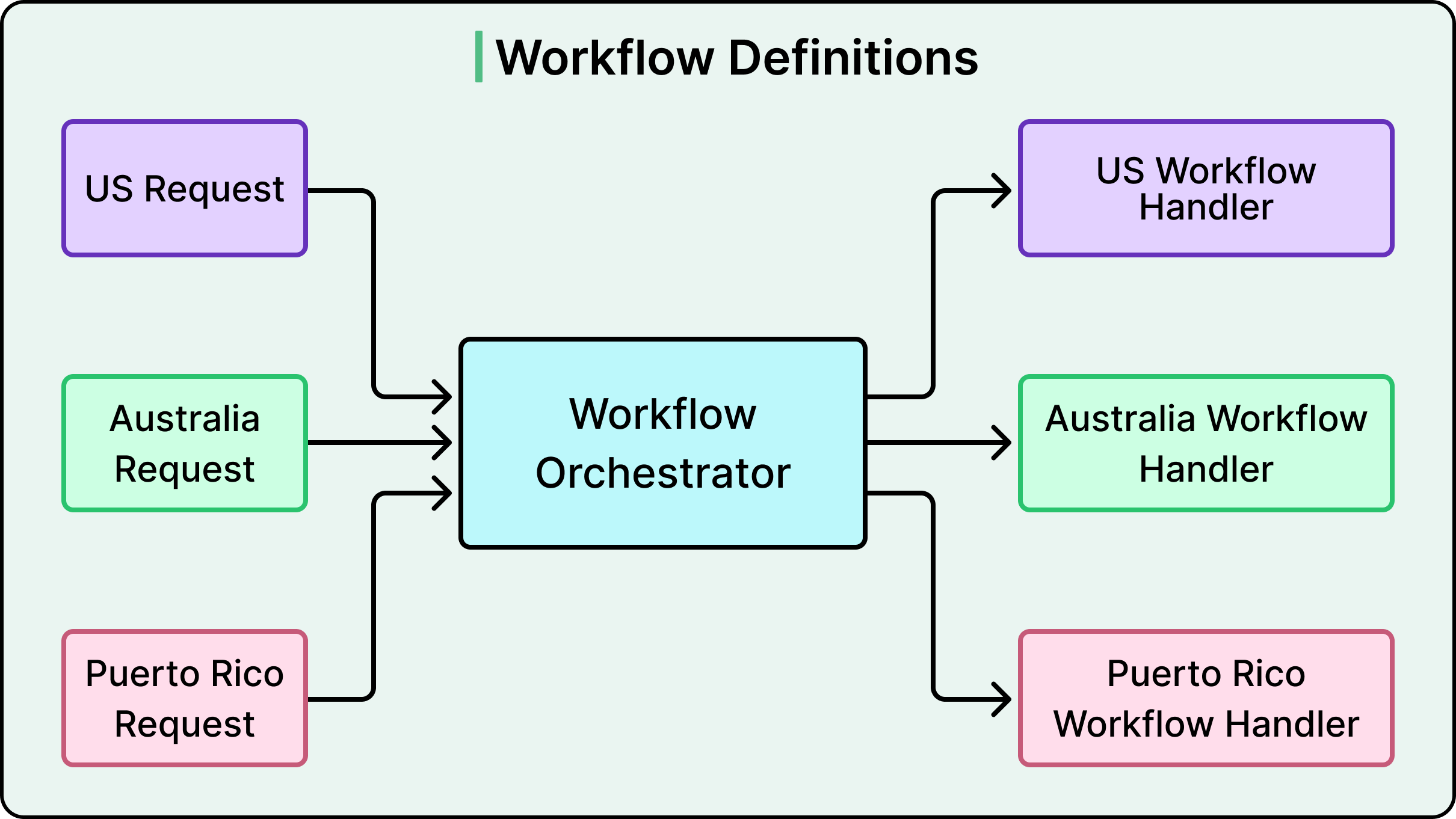
Workflow Definitions are the second layer. A workflow is simply an ordered list of steps for a specific market. The US workflow might look like Data Collection, followed by Identity Verification, followed by Compliance Check, followed by Additional Validation. Australia’s workflow skips one step and reorders another. Puerto Rico adds a regional customization. Each workflow is defined as a class with a list of step references, making it easy to see exactly what each market’s onboarding process looks like.
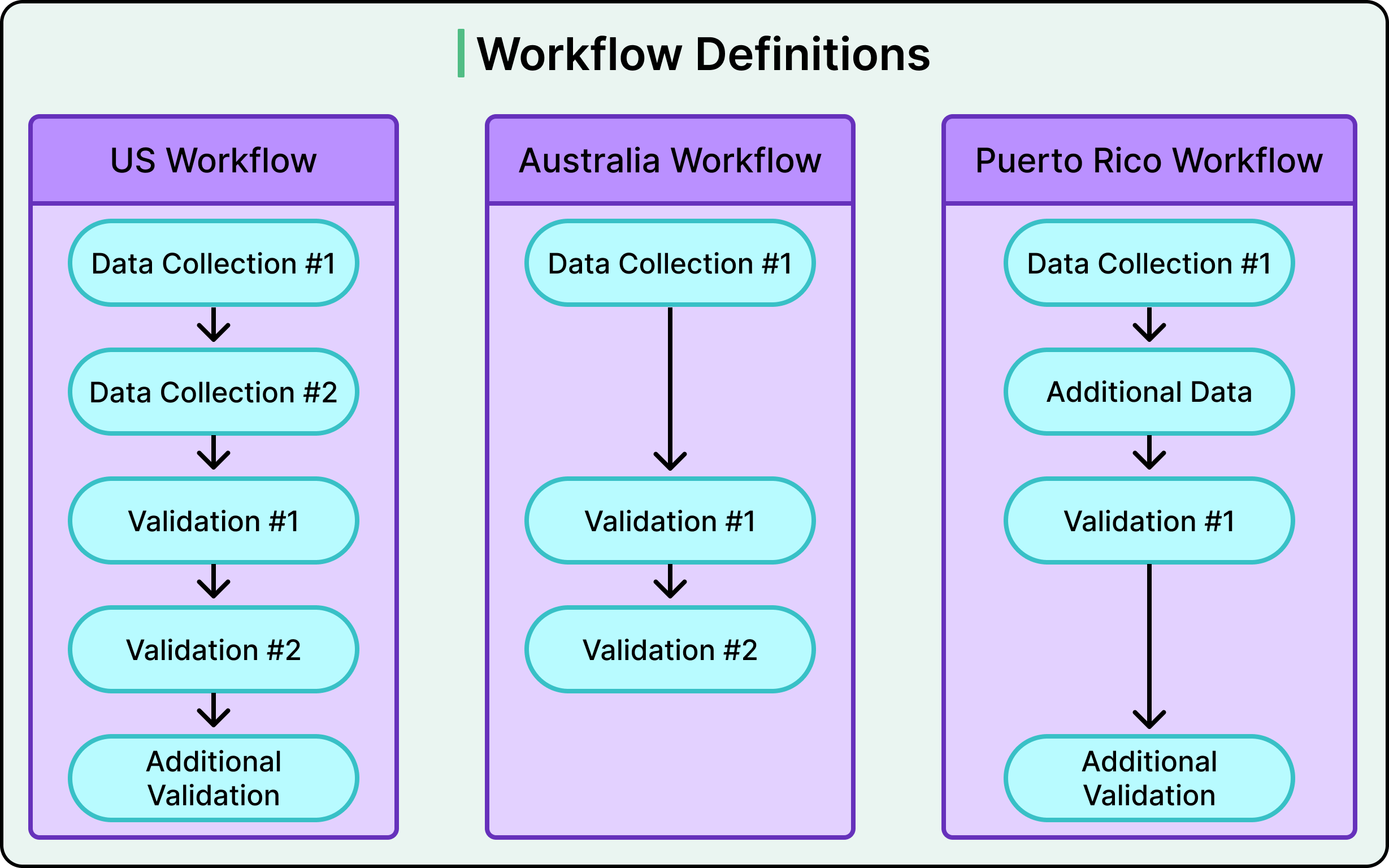
Think of it like a Lego set. Each brick has a standardized shape, studs on top, tubes on the bottom, and that standard interface lets you build anything. A workflow definition is like building instructions for a specific model.
Step Modules are the third layer, and this is where the actual work happens. Each step (data collection, identity verification, risk and compliance checking, document verification) is implemented as an independent and self-contained module. A step knows how to collect its data, validate it, call its external vendors, handle retries and failures, and report success or failure. What it doesn’t know is which workflow it belongs to, or what step comes before or after it. This isolation is what makes reuse possible.
The mechanism enabling this plug-and-play behavior is the interface contract. Every step implements the same standardized interface, with a method to process the step, a method to check if it’s complete, and a method to return its response data. As long as a new step honors this contract, it can slot into any workflow without the workflow knowing or caring about its internals.
This contract also enables team autonomy. The identity verification step can be owned entirely by the security team. Payment setup can belong to the finance team. Each team iterates on their step independently, as long as they maintain the shared interface. In a way, the architecture mirrors the organizational structure, or more accurately, it lets the organizational structure work for the system instead of against it.
Two additional capabilities make the system even more flexible:
- Composite steps group multiple granular steps into a single logical unit. One country might collect all personal information on a single screen. Another might split it across three screens. A composite step called “PersonalDetails” can wrap Profile, Additional Info, and Vehicle steps together, handling that variation without changing the individual step implementations underneath.
- And steps can be dynamic and conditional. A Waitlist step might only appear in markets with specific supply conditions. The same step can even appear multiple times within a single workflow.
This flexibility goes beyond simple reordering and confirms that steps are truly stateless and workflow-agnostic.
The address collection step is the clearest proof that this works in practice. DoorDash built it once as a standalone module. When Australia needed address collection early in their flow for compliance checks, the team simply inserted the module before the compliance step in Australia’s workflow definition, without any special logic or branching. Canada later adopted the same step for validation and service-area mapping. It worked out of the box. The US team then experimented by enabling it in select regions, and again, with no new code.
This three-layer pattern isn’t specific to onboarding. Any multi-step process that varies across contexts (checkout flows, approval pipelines, content moderation queues) can be decomposed this way.
One important clarification here is that DoorDash’s step modules are not separate microservices. They are modules within a single service, which means the lesson here is about logical decomposition and interface design rather than strict deployment boundaries. Technically, we could apply this same pattern inside a monolith.
How does the system know where each applicant is in their journey?
Answering this question is needed to make modular steps work.
In the legacy system, this was a mess. Progress was tracked across multiple separate tables, each representing part of the workflow. Introducing a new onboarding step meant modifying several of these tables. Ensuring synchronization between them required close coordination across services, and it often broke down, leading to data mismatches and brittle integrations.
The new system introduced the status map, a single JSON object in the database where every step writes its own progress. It looks something like this:
Each step is responsible for updating its own entry in the map. When a step starts, completes, fails, or gets skipped, it writes that transition directly to its entry. The workflow layer never writes to the status map. It just reads it.
See the diagram below:
Each step also exposes an isStepCompleted() method that defines its own completion logic based on the status map. One step might treat “SKIPPED” as a terminal state, while another might not. This flexibility lives at the step level, not the workflow level, which keeps the orchestration logic simple and stateless.
The practical benefit is immediate. A single query on the status map tells you exactly where any applicant stands in their onboarding journey. Partial updates are handled through atomic JSON key merges, meaning that when one step updates its status, it only touches its own entry without overwriting the rest of the map.
The architecture is only half the story. Getting there without breaking a running system is where the real engineering difficulty lives.
DoorDash didn’t flip a switch. They designed the new platform to coexist with the existing V2 and V3 APIs, running old and new systems side by side. Applicants who had partially completed onboarding under the legacy system needed to continue seamlessly, so the team built temporary synchronization mechanisms that mirrored progress between systems until the migration was complete. This parallel operation was itself a temporary technical debt, built intentionally to be thrown away.
Other major initiatives were underway during the rebuild, sometimes conflicting with the new onboarding design. Rather than treating these as blockers, the team collaborated across those efforts and adapted the architecture where necessary.
The migration started with the US in January 2025, their largest and most complex market, as the proving ground. Then the compounding payoff kicked in. Australia was completed in under a month, needing only two localized steps. Canada followed in two weeks with a single new module. Puerto Rico took a week with a minor customization. New Zealand required almost no new development.
Every migration launched with zero regressions, no user-facing incidents, no onboarding downtime, and no unexpected drop-offs in completion rates. Each rollout got faster because more modules had already been battle-tested by thousands of Dashers in prior markets.
The architecture has also proven its value beyond adding countries. DoorDash is integrating its onboarding with another large, independently developed ecosystem that has its own mature onboarding flow. The modular design allowed them to build integration-specific workflows while reusing much of the existing logic, something that would have been extremely painful with the legacy system.
The tradeoffs are real, though. Modularity adds coordination overhead. For a single-market startup, this architecture can be considered overkill. A monolithic onboarding flow is completely fine until you hit the inflection point where country-specific branching becomes more expensive than decomposition.
Reusable modules work well when the underlying concept generalizes across markets. For example, addresses are conceptually similar everywhere, which is why the address step was reused so cleanly. However, compliance requirements can be fundamentally different between regulatory regimes.
The boundary between the platform team and domain teams also requires ongoing negotiation. DoorDash addresses this through published platform principles, versioned interface contracts, and joint KPIs that create shared accountability. Domain expert teams own their business logic (fraud detection, compliance, payments) while the platform enforces consistency. This is a human coordination challenge that architecture alone doesn’t solve.
Looking ahead, DoorDash’s roadmap includes dynamic configuration loading to enable workflows to go live through config rather than code, step versioning to allow multiple iterations of a step to coexist during experiments or rollouts, and enhanced operational tooling to give non-engineering teams the ability to manage workflows directly.
That said, DoorDash deliberately kept workflows code-defined rather than jumping straight to config-driven. While config-driven systems are powerful, they introduce their own complexity. They can be harder to debug and harder to test.
Ultimately, what DoorDash built is a sort of pattern for any system that needs to support multiple variants of a multi-step process. The core idea is three layers (a thin orchestrator, composable workflows, and self-contained steps behind standardized interfaces) connected by a single shared state structure.
**References:**