AutoAdapt: Automated domain adaptation for large language models

- AutoAdapt 可显著减少手动调整领域适配的工作量。
- 通过自动化流程提升大语言模型在垂直领域的准确性和效率。
- 该方法结合了迁移学习和无监督学习的优势。
AutoAdapt: Automated domain adaptation for large language models - Microsoft Research

Our research
Resources
Research areas: Intelligence
- Artificial intelligence
- Audio & acoustics
- Computer vision
- Graphics & multimedia
- Human-computer interaction
- Human language technologies
- Search & information retrieval
Research areas: Systems
- Data platforms and analytics
- Hardware & devices
- Programming languages & software engineering
- Quantum computing
- Security, privacy & cryptography
- Systems & networking
Research areas: Theory
Research areas: Other Sciences
- Ecology & environment
- Economics
- Medical, health & genomics
- Social sciences
- Technology for emerging markets
Programs & events
Academic programsEvents & academic conferencesMicrosoft Research Forum
Connect & learn
Behind the Tech podcastMicrosoft Research blogMicrosoft Research ForumMicrosoft Research podcast
About
People & news
- About Microsoft Research
- Careers & internships
- People
- Emeritus program
- News & awards
- Microsoft Research newsletter
Microsoft Research Labs
- Africa
- AI for Science
- AI Frontiers
- Asia-Pacific
- Cambridge
- Health Futures
- India
- Montreal
- New England
- New York City
- Redmond
Other labs
More
All Microsoft
Tech & innovation
Industries
Partners
- Find a partner
- Become a partner
- Partner Network
- Microsoft Marketplace
- Marketplace Rewards
- Software development companies
Resources
- Blog
- Microsoft Advertising
- Developer Center
- Documentation
- Events
- Licensing
- Microsoft Learn
- Microsoft Research
Cancel
Search
Microsoft Research Blog
AutoAdapt: Automated domain adaptation for large language models
Published April 22, 2026
By Sidharth Sinha, Research Fellow Anson Bastos, Senior Researcher Xuchao Zhang, Principal Research Manager Akshay Nambi, Principal Researcher Rujia Wang, Principal Research Product Manager Chetan Bansal, Senior Principal Research Manager
Share this page
- [Share on Facebook](https://www.facebook.com/sharer/sharer.php?u=https%3A%2F%2Fwww.microsoft.com%2Fen-us%2Fresearch%2Fblog%2Fautoadapt-automated-domain-adaptation-for-large-language-models%2F "Share on Facebook")
- [Share on X](https://x.com/intent/tweet?text=AutoAdapt%3A%20Automated%20domain%20adaptation%20for%20large%20language%C2%A0models&url=https%3A%2F%2Fwww.microsoft.com%2Fen-us%2Fresearch%2Fblog%2Fautoadapt-automated-domain-adaptation-for-large-language-models%2F "Share on X")
- [Share on LinkedIn](https://www.linkedin.com/shareArticle?mini=true&url=https%3A%2F%2Fwww.microsoft.com%2Fen-us%2Fresearch%2Fblog%2Fautoadapt-automated-domain-adaptation-for-large-language-models%2F&title=AutoAdapt%3A%20Automated%20domain%20adaptation%20for%20large%20language%C2%A0models&summary=AutoAdapt%3A%20Automated%20domain%20adaptation%20for%20large%20language%C2%A0models&source=Microsoft%20Research "Share on LinkedIn")
- [Share on Reddit](http://www.reddit.com/submit?title=AutoAdapt%3A%20Automated%20domain%20adaptation%20for%20large%20language%C2%A0models&url=https%3A%2F%2Fwww.microsoft.com%2Fen-us%2Fresearch%2Fblog%2Fautoadapt-automated-domain-adaptation-for-large-language-models%2F "Share on Reddit")
- [Subscribe to our RSS feed](https://www.microsoft.com/en-us/research/feed/ "Subscribe to our RSS feed")
At a glance
- **Problem**:Adapting large language models to specialized, high-stakes domains is slow, expensive, and hard to reproduce.
- **What we built**:AutoAdapt automates planning, strategy selection(e.g., RAG vs. fine-tuning), and tuning under real deployment constraints.
- **How it works**: A structured configuration graph maps the full scope of the adaptation process, an agentic planner selects and sequences the right steps, and a budget-aware optimization loop (AutoRefine)refines the process within defined constraints.
- **Why it matters**:The result is faster,automated,more reliable domain adaptation that turns weeks of manual iteration into repeatable pipelines.
Deploying large language models (LLMs) in real-world, high-stakes settings is harder than it should be. In high-stakes settings like law, medicine, and cloud incident response, performance and reliability can quickly break down because adapting models to domain-specific requirements is a slow and manual process that is difficult to reproduce.
The core challenge is domain adaptation, which entails turning a general-purpose model into one that consistently follows domain rules, draws on the right knowledge, and meets constraints such as latency, privacy, and cost. Today, that process typically involves guesswork, choosing among approaches like retrieval-augmented generation (RAG) and fine-tuning, tuning hyperparameters, and iterating through evaluations with no clear path to a good outcome. An operations team responding to an outage can’t afford a model that drifts from domain requirements or a tuning process that takes weeks with no guarantee of a reproducible result.
To tackle this, we’re pleased to introduce AutoAdapt. In our paper, “AutoAdapt: An Automated Domain Adaptation Framework for Large Language Models,” we describe an end-to-end, constraint-aware framework for domain adaptation. Given a task objective, available domain data, and practical requirements like accuracy, latency, hardware, and budget, AutoAdapt plans a valid adaptation pipeline, selecting among approaches like RAG and multiple fine-tuning methods, and tunes key hyperparameters using a budget-aware refinement loop. The result is an executable, reproducible workflow for building domain-ready models more quickly and consistently, helping make LLMs dependable in real-world settings.
Spotlight: Microsoft research newsletter

Microsoft Research Newsletter
Stay connected to the research community at Microsoft.
Opens in a new tab
How it works
AutoAdapt starts from a practical observation: teams don’t just need a better prompt or more data, they need a decision process that reliably maps a task, its domain data, and real constraints to an approach that works. To do this, AutoAdapt treats domain adaptation as a constrained planning problem. Given an objective provided in natural language, dataset size and format, and limits on latency, hardware, privacy, and cost, it provides an end-to-end pipeline that teams can execute and deploy.
Domain adaptation often feels like trial and error because the design space is large and complex. Teams must choose among approaches such as RAG, supervised fine-tuning, parameter-efficient methods (such as LoRA), and alignment steps, each with many hyperparameters. These choices interact in nonobvious ways, and not all combinations are valid, making it difficult to identify a reliable strategy. The problem is compounded by the high cost of LLM training, which limits how many configurations can be explored.
AutoAdapt addresses this with the Adaptation Configuration Graph (ACG), a structured representation of the system’s configuration space that enables efficient search while guaranteeing valid pipelines.
Building on the ACG, AutoAdapt uses a planning agent to make and justify decisions. It proposes strategies, evaluates them against user requirements, and iterates until the plan is feasible and well-grounded. Rather than optimizing in an unconstrained black box, AutoAdapt roots each decision in best practices and explicit constraints, producing an executable workflow with parameter ranges.
Finally, AutoAdapt introduces AutoRefine, a budget-aware refinement loop that optimizes hyperparameters by strategically selecting which experiments to run next, even under limited feedback. AutoRefine replaces weeks of manual tuning with a more disciplined, reproducible process that is easier to audit and compare across projects. In real-world systems such as healthcare documentation, legal workflows, or incident response, this level of rigor is essential. Figure 1 illustrates the end-to-end workflow.
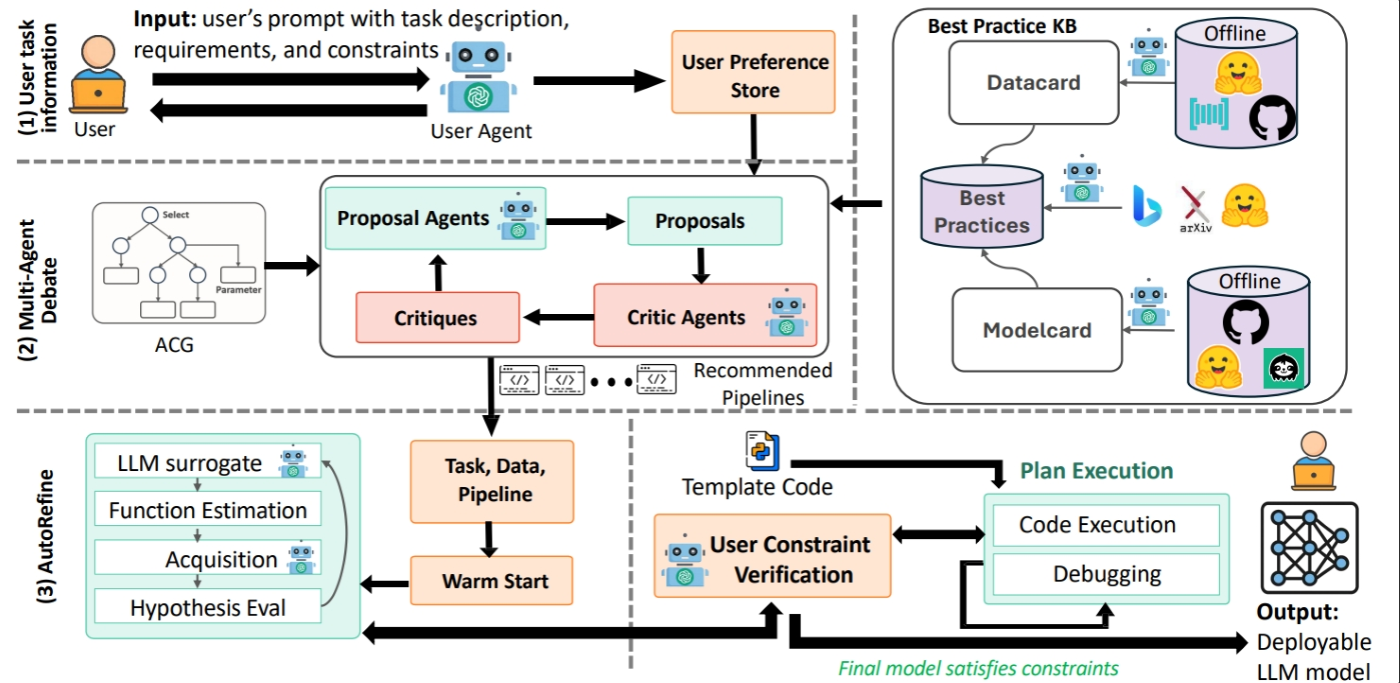
Figure 1. The AutoAdapt workflow, showing how user inputs flow through planning and refinement to produce a deployable model.
Evaluation
In experiments, AutoAdapt consistently identifies effective adaptation strategies and delivers improvements across a range of benchmark and real-world tasks, including reasoning, question answering, coding, classification, and cloud-incident diagnosis. It uses constraint-aware planning and budgeted refinement to find better-performing configurations with minimal added time and cost, making the process practical for production teams. Figures 2 and 3 show aggregate performance against competitive baselines.
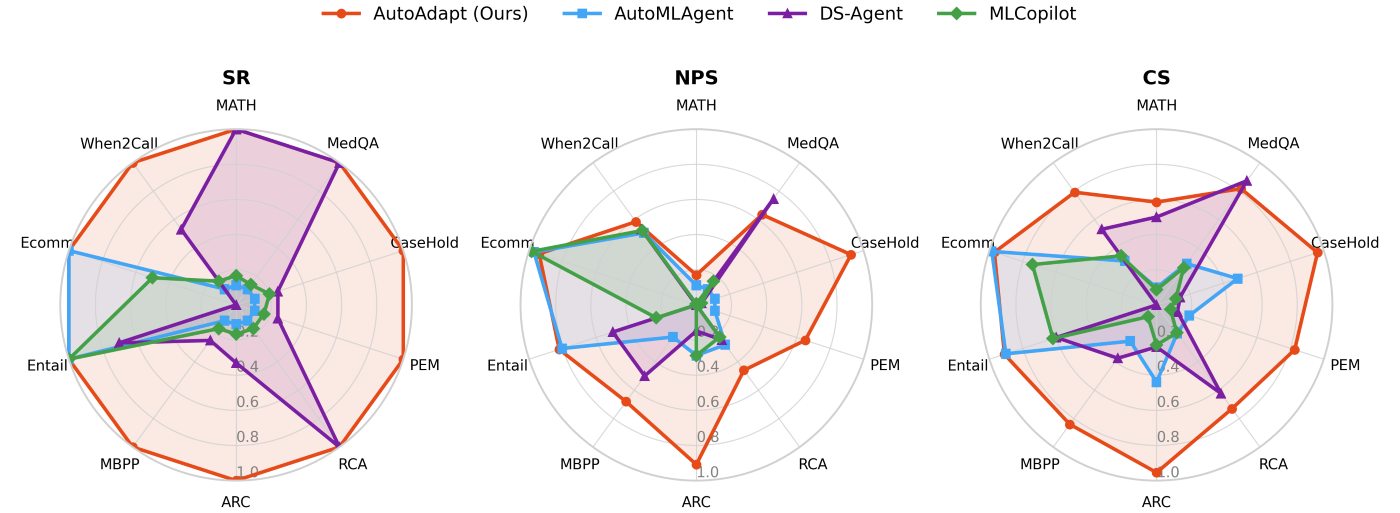
Figure 2. Success rate (SR), normalized performance score (NPS), and cumulative score (CS) comparing AutoAdapt with baseline methods across datasets. Higher scores indicate better performance, with AutoAdapt outperforming state-of-the-art baselines.
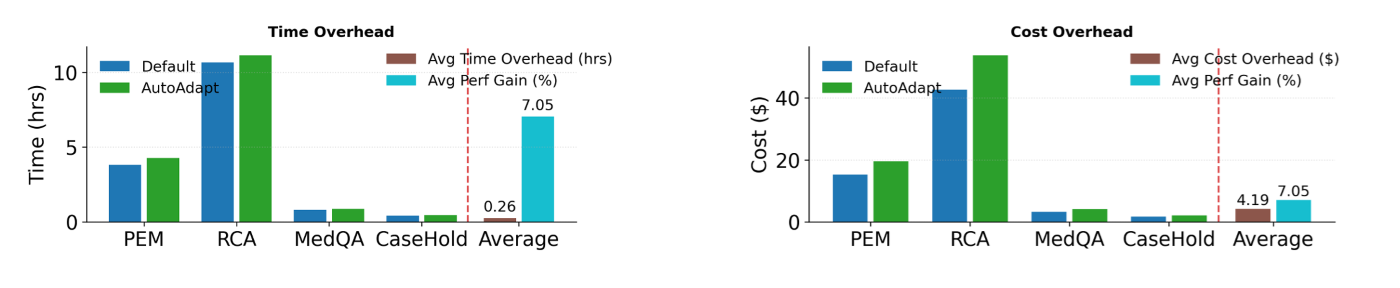
Figure 3. AutoAdapt achieves performance gains with minimal overhead, approximately 30 minutes of additional time and $4 in additional cost.
Implications and looking forward
The broader significance of AutoAdapt is that domain adaptation can become an engineering discipline, not an ad hoc process. By making key choices explicit—what to adapt, how to adapt it, and which constraints the system must satisfy—AutoAdapt helps teams reach results faster, reproduce them more easily, and audit them more rigorously. This shift is especially important in domains where drift from pretrained knowledge is common and failures are costly. When LLMs are used to draft clinical notes, triage support incidents, or summarize regulatory language, organizations need a clear, repeatable path from data to models that behave predictably under latency, privacy, and budget requirements.
Because domain adaptation is a prerequisite for deploying LLMs in real-world settings, we’re making the AutoAdapt frameworkopen source (opens in new tab) to give teams a concrete starting point. The README (opens in new tab) file provides installation and quick-start instructions.
Opens in a new tab
Related publications
[AutoAdapt: An Automated Domain Adaptation Framework for LLMs](https://www.microsoft.com/en-us/research/publication/autoadapt-an-automated-domain-adaptation-framework-for-llms/)
Meet the authors
Sidharth Sinha
Research Fellow

Anson Bastos
Senior Researcher

Xuchao Zhang
Principal Research Manager

Akshay Nambi
Principal Researcher

Rujia Wang
Principal Research Product Manager
Chetan Bansal
Senior Principal Research Manager
Continue reading

June 17, 2025
[New methods boost reasoning in small and large language models](https://www.microsoft.com/en-us/research/blog/new-methods-boost-reasoning-in-small-and-large-language-models/)

June 5, 2025
[BenchmarkQED: Automated benchmarking of RAG systems](https://www.microsoft.com/en-us/research/blog/benchmarkqed-automated-benchmarking-of-rag-systems/)

November 25, 2024
[LazyGraphRAG: Setting a new standard for quality and cost](https://www.microsoft.com/en-us/research/blog/lazygraphrag-setting-a-new-standard-for-quality-and-cost/)

September 9, 2024
[GraphRAG auto-tuning provides rapid adaptation to new domains](https://www.microsoft.com/en-us/research/blog/graphrag-auto-tuning-provides-rapid-adaptation-to-new-domains/)
Research Areas
- 
Research Groups
Related labs
Follow us:
- Follow on X
- Like on Facebook
- Follow on LinkedIn
- Subscribe on Youtube
- Follow on Instagram
- Subscribe to our RSS feed
Share this page:
What's new
- Surface Pro
- Surface Laptop
- Surface Laptop Studio 2
- Copilot for organizations
- Copilot for personal use
- AI in Windows
- Explore Microsoft products
- Windows 11 apps
Microsoft Store
- Account profile
- Download Center
- Microsoft Store support
- Returns
- Order tracking
- Certified Refurbished
- Microsoft Store Promise
- Flexible Payments
Education
- Microsoft in education
- Devices for education
- Microsoft Teams for Education
- Microsoft 365 Education
- How to buy for your school
- Educator training and development
- Deals for students and parents
- AI for education
Business
- Microsoft AI
- Microsoft Security
- Dynamics 365
- Microsoft 365
- Microsoft Power Platform
- Microsoft Teams
- Microsoft 365 Copilot
- Small Business
Developer & IT
- Azure
- Microsoft Developer
- Microsoft Learn
- Support for AI marketplace apps
- Microsoft Tech Community
- Microsoft Marketplace
- Marketplace Rewards
- Visual Studio
Company
- Careers
- About Microsoft
- Company news
- Privacy at Microsoft
- Investors
- Diversity and inclusion
- Accessibility
- Sustainability
- Sitemap
- Contact Microsoft
- Privacy
- Manage cookies
- Terms of use
- Trademarks
- Safety & eco
- Recycling
- About our ads
- © Microsoft 2026
Notifications