自动化智能文档处理的模式生成

TL;DR · AI 摘要
AWS推出多文档发现功能,自动化生成文档处理schema,将手动创建耗时从数周缩短至数小时,支持大规模文档处理。
核心要点
- AWS IDP Accelerator新增多文档发现功能,通过视觉嵌入聚类文档,自动生成schema,减少90%手动工作量。
- 利用Amazon Bedrock嵌入模型和Strands Agents生成schema,无缝集成到IDP Accelerator配置文件。
- 支持S3或Zip输入,通过Step Functions和Lambda实现无服务器处理,处理数千文档仅需数小时。
结构提纲
按章节快速跳转。
- §问题背景
手动创建文档处理schema需大量人工,难以处理数千文档。
AWS IDP Accelerator新增多文档发现功能,自动分析未知文档并生成schema。
- ›技术实现
使用视觉嵌入模型和Strands Agents进行文档聚类和schema生成。
- ›工作流程
文档从S3输入,经嵌入、聚类、schema生成,输出结构化配置文件。
- ›实施步骤
工程师可直接在IDP Accelerator控制台运行该功能处理自定义文档集合。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- 多文档发现自动化
- 技术组件
- Amazon Bedrock
- Strands Agents
- AWS Step Functions
- AWS Lambda
- 工作流程
- 文档嵌入
- 聚类分析
- schema生成
- 质量检查
金句 / Highlights
值得收藏与分享的关键句。
多文档发现功能将schema生成时间从数周缩短至数小时,支持处理数千文档。
使用视觉嵌入而非OCR文本,捕捉布局和格式线索,提升文档类型识别准确率。
Strands Agents与Bedrock LLM协作,自动生成结构化schema,减少人工干预。
标题:自动化智能文档处理的模式生成 | 亚马逊网络服务
URL 来源:https://aws.amazon.com/blogs/machine-learning/automate-schema-generation-for-intelligent-document-processing/
发布日期:2026-05-12T07:54:08-08:00
Markdown 内容: 在使用智能文档处理(IDP)技术从文档中提取信息之前,您需要为每类文档定义一个模式,明确需要提取的内容。但当您拥有数千份文档且不确定存在哪些类别时,该如何创建模式?在大规模实施时,这需要大量人工操作,使得后续的 IDP 项目难以证明其合理性。
本文将展示我们的多文档发现功能如何解决此问题。该功能作为自动化预处理步骤,可分析未知文档、按类型聚类,并生成可直接用于 IDP Accelerator 的模式。您将了解新功能如何利用视觉嵌入实现自动聚类,以及如何通过智能体生成模式。我们还将带您完成在自有文档集合上运行该解决方案的全流程。
IDP Accelerator
IDP Accelerator 是一个可扩展的无服务器开源解决方案,用于自动化文档处理和信息提取。要将该方案适配到您的特定文档类型,需提供一个 配置文件,其中指定文档类别和字段。最小配置示例请参阅 IDP Accelerator GitHub 仓库。
若对文档类型缺乏充分理解,创建此模式将十分困难。IDP Accelerator 内置了 发现模块,可通过单个示例文档快速生成类别配置。但您需预先知晓文档类别,并能为每类文档识别代表性示例。本文介绍的多文档发现功能消除了这一前提要求,加速您将 IDP Accelerator 应用于未标注文档集合的进程。
解决方案概览
以下视频展示了 IDP Accelerator 控制台中的解决方案。
多文档发现功能可将未分类文档集合自动转换为结构化模式,为后续 IDP 项目做好准备。该功能已集成至 IDP Accelerator 现有发现模块中,作为与“单文档”发现功能并行的“多文档”能力。AWS Step Functions 状态机和 AWS Lambda 函数提供编排与无服务器计算能力。解决方案从 Amazon S3 存储桶或 ZIP 文件上传中处理文档。通过 Amazon Bedrock 提供的模型生成的模式将自动整合至 IDP Accelerator 配置文件。下图展示了完整工作流程。
发现作业首先使用 Amazon Bedrock 上可用的嵌入模型,将 Amazon S3 中的每份文档转换为向量嵌入,随后将相似文档分组至聚类。基于 Strands Agents 构建的智能体与 Amazon Bedrock 大语言模型分析每个聚类,识别文档类型并生成模式。最后,通过反思步骤对模式进行综合审查,以捕获重叠和不一致之处,供您最终审核。
技术细节
我们将逐步解析流程中的每个环节,突出关键决策与实现细节。
嵌入生成
工作流为每份文档生成嵌入,将视觉特征转换为数值表示。对于多页文档,仅使用第一页。当前工作流采用视觉嵌入而非基于 OCR 的文本,因为视觉嵌入能捕捉布局、格式和结构线索,即使文本内容相似也能区分文档类型。该解决方案默认使用 Cohere Embed v4 作为发现作业的嵌入模型。嵌入步骤自动处理图像压缩、重试逻辑和速率限制等常见痛点。
多文档发现功能通过轮廓系数)学习集合中包含的文档类型数量。在此上下文中,轮廓系数用于衡量聚类之间的分离程度以及每个聚类内文档的紧凑性。默认情况下,代理使用k均值聚类方法测试k值范围(2至20),并选择轮廓系数最高的分组。此处k表示集合中不同文档类型的数量。为确保生成有意义的聚类,每个聚类必须包含至少两个文档。若必要,上限k值将低于20以满足此约束。
嵌入与聚类的基准测试
为验证嵌入与聚类方法的有效性,我们在IDP Accelerator CloudFormation堆栈部署的测试集存储桶中,使用Cohere Embed v4模型对OCR基准数据集子集进行了实验。要查找存储桶名称,请前往CloudFormation控制台,选择IDP Accelerator堆栈,打开"输出"选项卡,并查找键S3TestSetBucketName。
该数据集包含单页文档类型。部署的子集包含9种文档类型共293个文档:银行支票、商业租赁协议、信用卡账单、交货单、设备检查表、术语表、请愿书、房地产文件及轮班表。
为评估k均值聚类能否通过Cohere嵌入模型正确识别分组,我们以轮廓系数作为选择最优k值的指标。我们运行了管道的前两个阶段(嵌入与聚类),并分析了k值范围(2至20)下的轮廓系数分布。下图展示了轮廓系数在k值范围内的分布情况。轮廓系数最高值出现在k=9,与数据集中文档类型的实际数量一致。

t-SNE图(t分布随机邻域嵌入图,一种将高维数据降至二维空间并保留数据点间关系的可视化技术)展示了这些嵌入在二维空间的分布,图例显示了聚类分类。

聚类实现了完美的调整兰德指数(ARI)和归一化互信息(NMI)值1.0。ARI衡量聚类与真实分组的匹配程度,NMI量化预测聚类与实际聚类间共享的信息量。所有聚类均以100%纯度一对一映射到真实文档类别。这些结果表明,高质量的多模态嵌入可实现完全无监督的文档分类。嵌入能准确区分银行支票、房地产表单及信用卡账单等多样化文档类型,无需标注训练数据。
注意: 本基准数据集上的性能不保证在您的特定文档数据上取得相同结果,因为您的数据集特征直接影响结果质量。
代理式模式生成
聚类识别完成后,管道进入代理阶段。针对每个聚类,调用Strands Agent以确定文档类型并生成模式。我们选择Strands Agent因其基于模型的方法,赋予模型自主推理每个模式的能力。代理需有策略地选取聚类内不同位置的文档样本,以覆盖全部变体后再生成模式。例如,它会检查中心点、边缘点及中间距离的文档。固定采样策略在此不适用,因为聚类质量高度依赖于您的特定文档。为此,代理配备了两个专用工具:
- 聚类分析工具 – 按距离聚类中心的远近获取文档ID,使代理能有策略地覆盖聚类内的变体范围。
- 文档查看工具 – 获取并压缩文档图像以供视觉检查,自动处理模型上下文窗口的尺寸限制。
代理的系统提示编码了JSON Schema规范和IDP Accelerator配置要求的领域知识。提示指令包括:
- 有策略地选取文档样本,若已足够覆盖则提前终止。
- 生成包含正确元数据、类型定义和描述的JSON Schema。
- 包含IDP Accelerator特定标注(如
x-aws-idp-document-type和x-aws-idp-evaluation-method)。x-aws-idp-evaluation-method由Stickler评估扩展使用。 - 为常见结构(如地址、明细行、税务信息)创建可复用的
$defs。 - 根据字段类型应用适当的评估方法:字符串使用
EXACT,数字使用NUMERIC_EXACT,复杂或嵌套对象使用LLM。
架构分析
每个代理独立生成架构后,架构分析步骤将评估输出的整体差异性。它会判断发现的文档分组是否区分清晰或存在重叠,并检查生成的架构是否完整且一致。同时,它会检测不同文档类型间的冗余或重复内容。基于这些分析结果,系统会提供具体建议,例如合并分组或优化字段定义。该步骤会生成包含类目概览的摘要报告,该质量报告可在 IDP Accelerator 的发现作业详情中查看。
在您的文档上运行作业
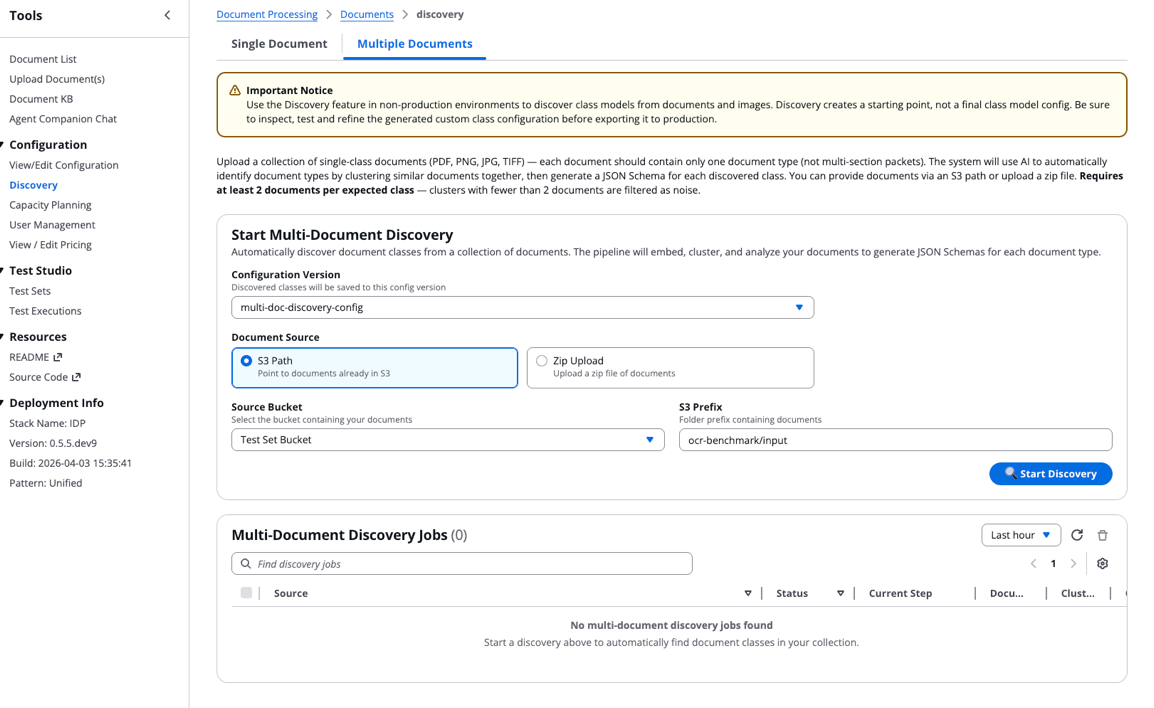
如需在您自己的文档上运行多文档发现工作流,请按以下步骤操作 IDP Accelerator 控制台。
步骤 1:创建新配置
在 IDP Accelerator 控制台中创建全新配置:
- 导航至 配置 部分,选择 查看/编辑配置。
- 选择 文档架构 > 清除全部 以创建新空配置。
- 选择 另存为版本,输入描述性 版本名称,然后点击 另存为版本。

步骤 2:运行多文档发现
配置就绪后,启动发现流程:
- 导航至 发现 部分,选择 多文档 选项。
- 选择您刚创建的配置版本。
- 配置文档源:
- 选择 S3 路径 或 ZIP 上传。
- 选择源存储桶。
- 指定存储文档的 S3 前缀。
注意:若使用源存储桶选项,您的文档必须已添加至 IDP Accelerator 的现有存储桶(发现存储桶、测试存储桶或输入存储桶)。
- 点击 开始发现 触发状态机。
步骤 3:监控发现作业并查看结果
跟踪发现作业进度:
- 多文档发现作业 表格中将新增条目,显示执行状态、当前步骤及元数据。
- 作业完成后,点击 源 字段查看结果:

- 滚动至发现作业详情底部,访问 质量报告:

发现的类目及其 JSON 架构将自动集成至您的配置文件。
最佳实践以获得最佳效果
在大规模运行多文档发现作业前,请注意以下几点最佳实践。由于当前工作流仅处理 PDF 的第一页,请确保输入文件为单文档文件(多文档包尚未支持)。获得初步结果后,务必彻底审查质量报告摘要,以识别重叠分组或文档分布不均等问题,再最终确定架构。
下一步操作
后续操作取决于工作流在您文档中发现的内容:
- 若架构清晰且质量报告显示重叠率低:可直接进入大规模 IDP 处理阶段。架构将自动添加至 IDP Accelerator 配置的类目字段。
- 若质量报告标记出重叠分组:请根据建议优化生成的架构,可能涉及合并相似架构为单一类目或调整字段定义以减少重叠。
- 若分组间架构质量不一致:检查文档集合是否存在高度不均衡的文档类型分布。在更均衡的子集上运行发现作业,有助于生成更可靠的分组与架构。
在本文中,我们向您展示了多文档发现功能如何解决一个核心挑战:需要在处理文档前确定模式,却又需要在确定模式前处理文档。该解决方案结合了视觉嵌入、自动聚类和基于多模态大语言模型的代理式模式生成,将模糊的未知文档集合转化为结构化、可审核的文档类别与模式。您已了解该工作流如何处理嵌入生成、聚类调优,以及并行分类与模式生成。同时,您也看到了复盘环节如何提供对代理生成输出的透明化分析,便于人工审核。
我们非常期待了解多文档发现功能在您文档集合中的实际效果。请在下方评论区分享您的测试结果、问题或建议。如遇问题或希望贡献代码,请在 GitHub 仓库 中提交问题或拉取请求。
- * *