Building AI-ready data: Vanguard’s Virtual Analyst journey
- 构建有效的对话式AI需要解决数据架构问题。
- 跨职能团队合作是成功的关键。
- AWS提供了全面的服务支持AI就绪数据架构。
结构提纲
AI 替你读一遍后整理出的核心层级。
- §引言
介绍Vanguard及其面临的挑战:分析师查询复杂数据集的困难。
描述Vanguard分析师在获取金融数据时遇到的问题及对AI的需求。
强调跨职能团队合作对于构建AI就绪数据的重要性。
详细介绍Vanguard如何使用AWS服务构建虚拟分析师解决方案。
思维导图
用一张图看清主题之间的关系。
- 构建AI就绪数据:Vanguard的虚拟分析师之旅
金句 / Highlights
值得收藏与分享的关键句。
Vanguard is a global investment management firm, offering a broad selection of investments, advice, retirement services, and insights to individual investors, institutions, and financial professionals. We operate under a unique, investor-owned structure and adhere to a straightforward purpose: To take a stand for all investors, to treat them fairly, and to give them the best chance for investing success.
When Vanguard’s financial analysts needed to query complex datasets, they faced a frustrating reality: even basic questions required writing intricate SQL queries and sometimes long response times from data teams. This challenge is not unique to Vanguard: conversational AI is a scalable solution, providing analysts immediate responses. However, deploying conversational AI requires more than choosing the right foundation model—it requires AI-ready data infrastructure.
In this post, you’ll learn how Vanguard built their Virtual Analyst solution by focusing on eight guiding principles of AI-ready data, the AWS services that powered their implementation, and the measurable business outcomes they achieved.
The challenge: When AI meets enterprise data complexity
Vanguard’s analysts and business stakeholders sought faster, more direct access to financial data for decision-making. The existing workflow required SQL expertise and data team support, with typical requests taking several days to fulfill. The data infrastructure required semantic context and metadata management to enable AI-powered tools to generate accurate, business-relevant insights.
As the Virtual Analyst project progressed, the team discovered that building effective conversational AI wasn’t a machine learning challenge—it was a data architecture challenge. The most sophisticated foundation models require proper data foundations to deliver reliable results. This realization led to a fundamental shift in approach: instead of focusing solely on AI capabilities, Vanguard needed to build what they termed _AI-ready data_.
The collaborative imperative: Breaking down silos
Building Virtual Analyst requires something many organizations struggle with: getting traditionally siloed teams to work together. Vanguard brought together data engineers, business analysts, compliance officers, security teams, and business stakeholders. Each team brought critical expertise:
- **Data engineers** understood the technical infrastructure
- **Business analysts** knew the semantic meaning of financial metrics
- **Compliance teams** helped meeting regulatory requirements
- **Business users** provided the real-world context for how they are going to use the insights.
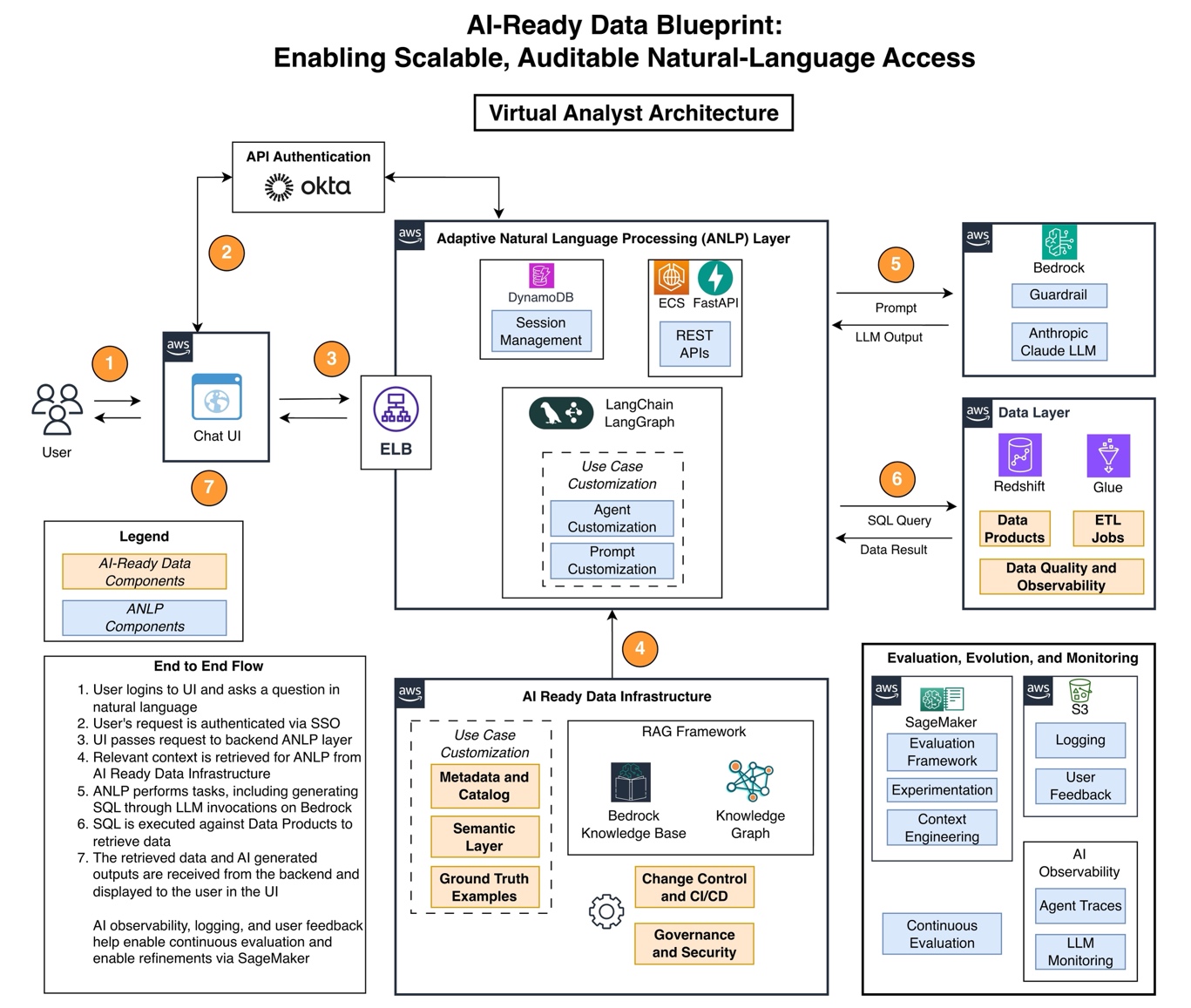
This cross-functional collaboration became the foundation for AI by developing a well-defined, cross-functional operating model where ownership models, semantic definitions and quality standards were well understood and activated. The team realized that without clear ownership models, semantic definitions, and quality standards that all teams could understand and contribute to, the AI solution would not have a good foundation. The Virtual Analyst project served as a catalyst for new processes and frameworks that provide benefits far beyond the initial AI use case. The following figure shows the AI-ready data blueprint that was developed for the Virtual Analyst architecture.
Case Study: Virtual Analyst
_The architecture reflects a single, context-specific implementation, and it should be viewed as illustrative rather than prescriptive._
Vanguard chose AWS for its comprehensive suite of integrated services. AWS offers a rich feature set for building AI-ready data architectures, from the advanced analytics capabilities of Amazon Redshift to the automated data cataloging on AWS Glue and the foundation model access on Amazon Bedrock. In addition, the security and compliance features of AWS met the stringent requirements of the financial services industry. The Virtual Analyst uses:
- Amazon Bedrockfor foundation models that power natural language understanding
- Amazon Bedrock Guardrails to secure AI inputs and outputs to protect Vanguard’s sensitive financial data
- Amazon Elastic Container Service (Amazon ECS)for scalable compute infrastructure
- Amazon DynamoDBfor conversation persistence across a horizontally scalable architecture with minimal latency
- Amazon Simple Storage Service (Amazon S3)for storage
- Amazon SageMakerfor experimentation
- Amazon Redshiftfor centralized data warehousing
- AWS Gluefor data cataloging while powering numerous extract, transform, load (ETL) jobs to consolidate accurate data
Eight guiding principles for AI-ready data
Through their journey building the Virtual Analyst, Vanguard identified eight guiding principles that build on existing foundational data capabilities (e.g. data platforms, integration, interoperability) and extend them to support AI-ready data. These principles emerged from real-world challenges encountered when trying to make AI systems work reliably with enterprise data at scale.
Establish clear data product and operating models
Higher quality data requires clear accountability. Data product owners are responsible for business alignment and engineering stewards should maintain technical quality. Service-level agreements (SLAs) for data freshness and reconciliation tolerance and established support models for downstream consumers will help ensure data products are reuseable, well-managed, and designed to deliver outcomes. Assign both business and technical owners to each critical data asset and document their responsibilities in writing.
Define governance and security measures
Work with your compliance and security teams early to establish enterprise identity management, role-based data access controls, query-level authorization, and retention policies. Vanguard implemented logging of authorization events to meet regulatory requirements while supporting business agility. Map your existing data access policies to the new AI system and implement row-level and column-level security where needed.
Build a metadata catalog that unifies technical and business context
Implement a unified metadata and catalog system as a control plane that centralizes both technical and business metadata while exposing them via APIs. Organizations often maintain complete technical metadata but lack integrated business context, creating misalignment between technical implementations and business requirements. Technical metadata includes table and column descriptions with data types, data lineage across transformations, synonyms and categorical indicators, and relationship mappings between datasets. Technical domain experts and data stewards define this layer. Start with your most frequently accessed datasets and systematically document their technical metadata before expanding to other data sources. Version your metadata and measure mapping accuracy to maintain discoverability and precision. Business metadata captures business definitions and rules for specific attributes, domain-specific terminology and ontologies, business ownership information, and usage context. Business users and domain experts contribute this layer through collaborative governance processes. A single catalog brings these two metadata types together, enabling AI systems to generate accurate queries that align with both technical structure and business meaning.
Implement a semantic layer to operationalize business metadata
The semantic layer operationalizes the business metadata defined in your catalog by transforming complex data structures into user-friendly formats. This implementation layer translates business definitions, rules, and ontologies into executable logic that standardizes how your organization defines key metrics and the relationships between different data elements. With this layer in place, business analysts can express their understanding of data relationships in natural language that can be interpreted and translated into structured SQL queries. By enforcing the business definitions and relationships documented in your metadata catalog, the semantic layer enhances consistency across queries, reduces the risk of errors, and streamlines SQL generation. For example, Vanguard’s semantic layer maintains the definition of _customer lifetime value_ across departments and systems by implementing the business rules defined by their business users. Work with business stakeholders to document the top 20 metrics your organization uses most frequently, including their precise definitions and calculation methods.
Develop ground truth examples
Ground truth examples form another critical component, comprising a set of question-to-SQL pairs that illustrate various queries users might ask. Create a library of question-to-SQL pairs that illustrate various user queries and their correct database translations. Vanguard built a collection of over 50 exemplars that serve three purposes: few-shot prompts for the AI model (providing example question-answer pairs to guide the model’s responses), evaluation benchmarks (measuring accuracy against known correct answers), and regression testing (verifying new changes don’t break existing functionality). These examples help the AI system learn through in-context learning. Start with 20–30 examples covering your most common query patterns, then expand based on user feedback and edge cases you discover.
Implement automated data quality checks
Vanguard set up observability tools to monitor data reliability through automated checks:
- **Distributional checks** – Detecting anomalies in data patterns (such as sudden spikes or drops in values)
- **Referential checks** – Verifying that relationships between tables remain valid (for example, every order references a valid customer)
- **Reconciliation checks** – Confirming data consistency across systems (for example, totals match between source and warehouse)
- **Freshness checks** – Confirming data updates occur on schedule
Establish change control processes
Treat your semantic definitions, exemplars, and configurations as code under version control. Change control and continuous integration and deployment (CI/CD) processes treat semantic definitions, exemplars, and pipeline configurations as code under continuous integration with staged deployments and gated approvals. This approach requires stakeholder sign-off for changes that affect KPIs or SLAs while enabling safe, rapid deployment of improvements. An established change control process is essential for managing the dynamic nature of the data landscape, confirming Virtual Analyst can adapt to changes effectively. Start storing data definitions in a version control system such as Git, and require peer review before changes go to production.
Create continuous evaluation mechanisms
Finally, use continuous evaluation and improvement processes define business metrics including analyst hours saved, time-to-insight improvements, user satisfaction, and measurable revenue or profit impacts where possible. The system maintains continuous regression suites and user feedback loops to evolve examples and semantics, with automated alerts for model degradation and business impact tracking. Define 3–5 key metrics that matter to your business stakeholders and establish baseline measurements before launching your AI system.
Results: From experiment to enterprise capability
The focus on AI-ready data delivered measurable outcomes:
- Reduced time-to-insight from days to minutes for complex financial queries with the use of the Virtual Analyst
- Enabled business users to access data independently without SQL knowledge
- Achieved high accuracy in AI-generated SQL queries through metadata and semantic layer implementation
- Decreased data team workload for routine analytical requests
- Established a reusable framework now being adopted across multiple Vanguard business units.
Looking forward
Vanguard is evaluating opportunities to explore how knowledge graphs and Retrieval-Augmented Generation (RAG) can further enhance Virtual Analyst. Knowledge graphs could provide explicit entity relationships, canonical resolution, and cross-domain context that materially improves fuzzy matching, join inference, and explainability for generated queries. RAG systems using Amazon Bedrock Knowledge Bases can use the exemplar library to increase accuracy while paving the way for intelligent feedback systems that will progressively refine model quality and reliability.
Conclusion: From AI project to data transformation
In this post, we showed you how Vanguard established new standards and ways of working that began a transformation of its data analytics capabilities, leveraging data as a strategic asset. What began as an AI project revealed the groundwork an organization needs to enable AI capabilities, as shown with these eight guiding principles. Successful AI isn’t just about better algorithms—it’s about building better data foundations to support AI at enterprise scale. The combination of the integrated data and AI services of AWS, coupled with disciplined data product practices, helps organizations convert model capabilities into dependable business outcomes that executives can trust for critical decision making.
- * *
About Authors
© [2026] _The Vanguard Group, Inc. All rights reserved. This material is provided for informational purposes only and is not intended to be investment advice or a recommendation to take any particular investment action._
问问这篇内容
回答仅基于本篇材料Skill 包
领域模板,一键产出结构化笔记论文精读包
把一篇论文 / 技术博客精读成结构化笔记:问题、方法、实验、批判、延伸阅读。
- · TL;DR(1 段)
- · 研究问题与动机
- · 方法概览
投融资雷达包
把一条融资 / 创投新闻整理成投资人视角的雷达卡:交易要点、判断、竞争格局、风险、尽调清单。
- · 交易要点(公司 / 轮次 / 金额 / 投资人 / 估值,材料未明示则写 “未披露”)
- · 投资 thesis(这家公司为什么值得关注)
- · 竞争格局与替代方案