2025 AI BACKWARD PASS
- AI基础设施瓶颈从芯片转向系统级问题,如网络、冷却和能源。
- 2025年AI资本支出达4000亿美元,但整体技术投资周期仍处于早期阶段。
- 中国开源大模型崛起,全球数据中心仅5%支持AI工作负载。
To download in pdf, click here.
**Introduction:**
AI’s progress in 2025 was largely a continuation of trends that were already taking shape in 2024 (download the 2024 Backward Pass here). Toward the end of 2024, we flagged the emergence of Chinese models such as DeepSeek and Qwen as credible competition to their Western counterparts. At the same time, improvements in reasoning capabilities and computer use began to unlock a new term called AI agents. These advances were underpinned by rapidly increasing investment in large-scale AI infrastructure. These themes carried forward into 2025.
What differentiated 2025 was the sheer speed and scale at which these themes progressed. AI CapEx reached $400B, nearly double the prior year. At the application layer, companies such as Manus, Cursor and Lovable scaled from double-digit ARR run rates to hundreds of millions of ARR in months – unprecedented in the annals of technology. Meanwhile, Chinese LLMs came to dominate the open-source leaderboards.
2025 didn’t introduce many fundamentally new paradigms in AI. Instead, it validated and accelerated trends that were already in motion, compressing multiple years of development into one. Below, we provide a recap of the year and our outlook for 2026.
**INFRASTRUCTURE LAYER:**
**From chips to systems:**
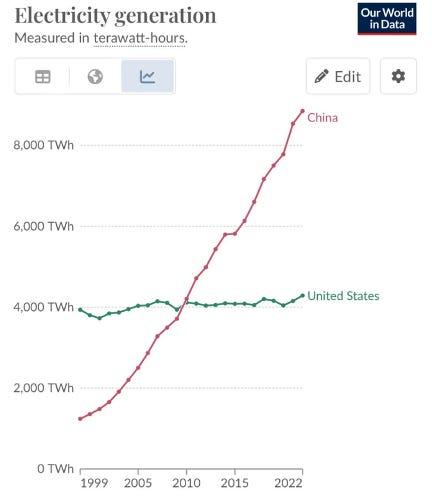
If one were to distill what is happening in AI infrastructure into a single sentence, it would be this: **chip-level bottlenecks are giving way to system-level bottlenecks**. By “system-level,” we mean the peripherals that enable chips to function at scale - networking, power transmission, cooling, data center infrastructure and ultimately energy itself. Elon Musk made a similar observation back in April 2025.
By no means are we suggesting that players like Nvidia, AMD, or Broadcom become irrelevant. In fact, our channel checks suggest that access to the latest generation of chips remains supply-constrained. But what it does mean is that energy security and resilience will become an even more important topic going forward. It means that as the long-term bottleneck shift increasingly towards energy, countries like China – which benefits from structural advantages in this area – will gain a relative advantage over others like the US (see chart below).
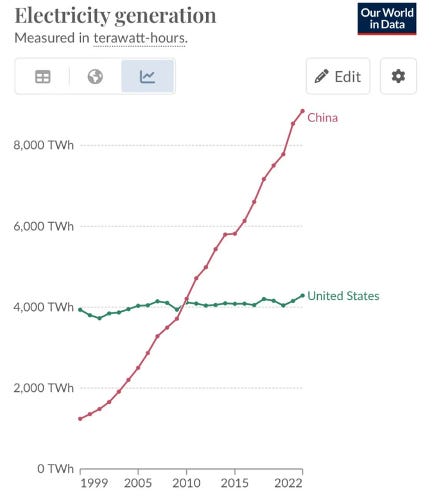
_Source: https://ourworldindata.org/_
**We are still in the early-to-mid innings:**
Despite the sheer magnitude of CapEx deployed in 2025 (~$400B), several signals suggest that there is still plenty of runway ahead.
First, across prior technology cycles such as the railroad, telephone, and internet, CapEx took on average 10-20 years to peak. The internet investment cycle, for example, began in earnest in the early 1990s and did not peak until 2000, cumulating with the dot com burst (see graph below). If we treat the launch of ChatGPT as the “iPhone moment” and starting point of the current cycle, then we are only four years in.
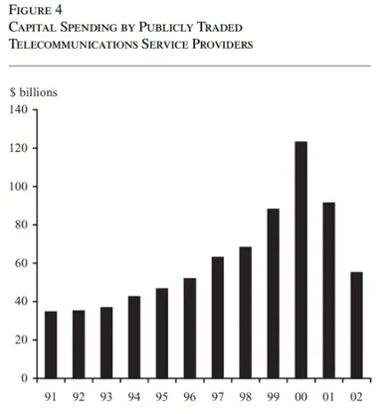
_Source: https://www.frbsf.org/wp-content/uploads/er19-34bk.pdf_
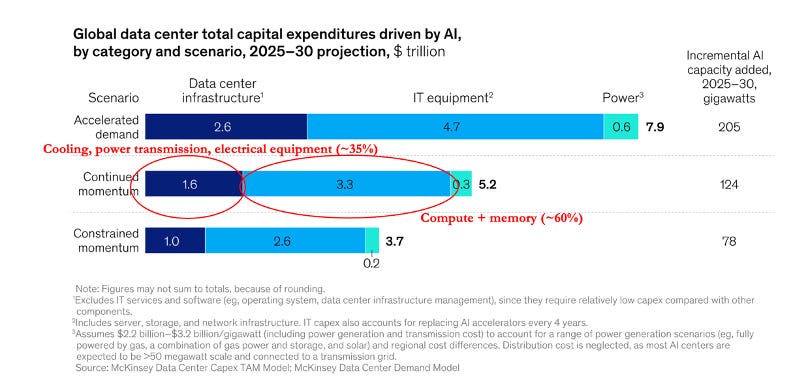
Second, only 5% of global data center capacity today is GPU- or AI-enabled. The majority of existing data center capacity remains CPU-based and optimized for traditional, non-AI workloads. If we believe that most data centers will ultimately need to support AI workloads, then this transition is still in its infancy. A separate study from McKinsey estimates that total AI-related data center spend will reach $4-8T over the next five years.
Third, tech incumbents such as Google, Microsoft, Amazon, and Meta (which together account for over 90% of total AI CapEx) continue to frame AI as a strategic existential priority. There has been little in the commentary of executives to suggest there will be any meaningful pullback in spending. Perhaps more importantly, investors have continued to support this. Google stock was up 65% in 2026, driven largely by the positive reception to the launch of Gemini 3 and their successful comeback in AI. Taken together, this suggests the AI arms race remains very much alive, and that CapEx discipline has not yet supplanted competitive exigencies.
However, some early cracks are beginning to show. CoreWeave, an AI neo cloud provider, initially traded to above 4x its IPO price before retracing meaningfully (though it remains roughly 2× above its IPO price). Similarly, Oracle shares surged 150% following its high-profile partnership announcement with OpenAI but have since pulled back by more than 30% from the peak. These moves suggest that while investors remain broadly supportive of the AI trade, there are some early signs of caution showing.
In our view, sentiment at the infrastructure layer increasingly hinges on the financial success and durability of the foundational labs themselves – most notably OpenAI and Anthropic. For example, roughly 60% or $300B of Oracle’s ~$500B total performance obligations are tied to OpenAI. Any doubts around the solvency or sustainability of these labs would likely reverberate across the broader ecosystem, with secondary effects extending well beyond infrastructure providers alone. However, as long as these labs continue to find funding sources, systemic risk at the infrastructure layer is likely to remain contained.
**Our predictions for 2026 – Infrastructure Layer:**
- **We will not reach peak investment year in 2026, but growth rates will begin to temper –**Nvidia remains a useful proxy for overall infrastructure spend. While the chipmaker’s growth rates are still strong (data center revenue grew 66% y/y last quarter) they have come down from the peaks of 90%+ in the year prior.
As mentioned earlier, we are still only four years into the current investment cycle. That said, we believe this cycle will be shorter than prior technology cycles, driven by a faster and clearer path to ROI. In the internet era, ROI was not immediately obvious because of network effects - one had to first build a large user base first before the technology became useful. The same was true for railroads, telephony, and most other technologies. In contrast, AI delivers immediate utility without the prerequisite of network effects: even a single user can extract meaningful value from ChatGPT. As a result, the ROI is much clearer, revenue ramps faster, and capital investments are deployed more quickly.
- **Increase diversification at the hardware/chip layer** – NVIDIA remains the 800-pound gorilla among chipmakers, but its margins are simply too rich for the industry to remain undisrupted indefinitely. We’re beginning to see credible alternatives emerge – most notably the improving performance of Google’s TPUs. Similarly, AMD’s data center business continues to gain traction, with management targeting ~60% CAGR through 2030. Greater diversification at the chip layer should ultimately be a net positive for the ecosystem. It should result in lower prices for both enterprises and consumers and help accelerate AI adoption. (Translink has directly underwritten this diversification thesis through our early investment in TensorWave).
- **There will be major delays in the buildout of data centers –** There was an excellent book released this year called ‘Breakneck’ by Dan Wang. In the book, the author argues that American elites are disproportionately lawyers, while Chinese elites are more often engineers. The practical implication is that the U.S. system is structurally optimized for risk mitigation and process, rather than rapid buildouts. In fact, we’ve already seen this dynamic across both the US public sector (e.g., high-speed rail, public housing) and the private sector (e.g., nuclear energy, energy grids). We expect these same structural frictions to slow large-scale data center buildouts as well. Again, this is a type of “system-level bottlenecks” that will likely constrain the pace of AI development.
- **Memory and storage will be increasingly important** – AI agents need to be stateful, which is just another way of saying they need to remember things. Every time an agent learns, recalls, or interacts, it generates new data that must be stored. This data can be in the form of text but will be increasingly multi-modal and behavioral/interaction based. Therefore – memory, or more accurately, storage is cumulative and a compounding bottleneck. Compute, on the other hand, is ephemeral. It can be recycled from one inference job to the next. More effective ways to store and retrieve information is an interesting question to think about.
**MODEL LAYER:**
**China as a disruptor:**
The first big bang that we got in 2025 was the release of DeepSeek R1 in January 2025. While we had anticipated the rise of Chinese LLMs in 2024, we ourselves were surprised at the capability of the DeepSeek R1 model. The core innovation here was showing that strong reasoning could be unlocked with large-scale reinforcement learning and aggressive inference-time compute scaling during _post-training,_ rather than relying solely on ever-larger pretrained models.

_Excerpt from our 2024 Backward Pass_
The R1 release triggered a sharp market reaction, with Nvidia shares declining by 15% in a single day. Investors interpreted this as evidence that future model performance might require less brute-force scale, and therefore fewer GPUs. What this view missed, however, is that the same techniques that reduce training demand would also increase inference demand.
Sticking to the topic of China, we believe the two key questions to ask are:
(1) will Chinese open-source models continue to catch up to Western closed-source models?
(2) will there be a large-scale disruption in the West because of Chinese models?
On question (1), our view is that Chinese models are unlikely to reach state-of-the-art performance in the near term, primarily due to constraints at the hardware layer. DeepSeek demonstrated that China is highly competitive in algorithmic and training innovation; however, today’s frontier models remain highly dependent on leading-edge chips. Even the best chefs would struggle to produce a great dish without the necessary raw ingredients.
Where we do see a durable advantage for Chinese models is on the cost-performance side. As discussed earlier, China benefits from large-scale energy supply and lower energy costs. If energy becomes the dominant long-term constraint in AI, then China is well positioned to achieve the lowest energy cost per unit of reasoning. Over time, should domestic hardware catch up as well, the combination of algorithmic/training innovation and energy advantage could position Chinese labs to compete at the frontier. But we think this is further down the road.
On question (2), we believe the threat from Chinese models is generally higher on the enterprise side than on the consumer side. In consumer, we see a lower likelihood of a Chinese model player challenging incumbents such as ChatGPT or Gemini purely through a standalone chatbot. That said, it remains possible that a consumer AI application rather than a model itself could gain meaningful traction over time, similar to how TikTok disrupted the social media space.
On the enterprise side, the dynamic looks a bit different. Here, cost and unit economics matter more, and Chinese open-source models can offer a compelling cost advantage. For AI application companies up the stack, their margins are directly tied to token and API costs, and any reduction in inference spend flows straight to their bottom line. It’s rumored that some Western application companies such as Cursor are already fine-tuning Chinese models. Consistent with this trend, downloads of Chinese models on Hugging Face have recently surpassed those of U.S. models (see below). Over time, this margin pressure will push AI application companies towards experimenting with the lowest-cost models available, especially if the cost gap widens while the performance gap continues to narrow.
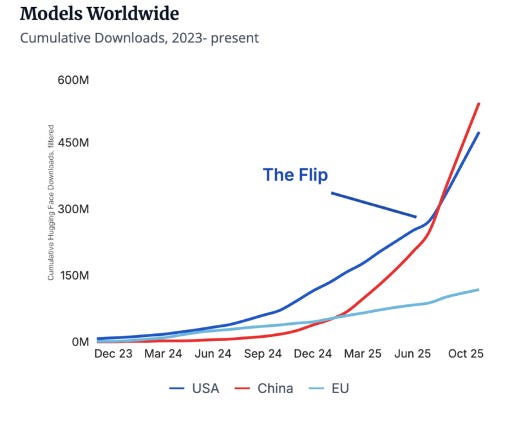
_Source: https://www.stateof.ai/_
**Google’s comeback:**
In 2025, we also saw meaningful market share shifts among leading LLM providers. Anthropic has now surpassed OpenAI in enterprise market share, and Google has largely caught up in the AI race after CEO Sundar Pichai issued a “code red” in early 2023. This has forced Sam Altman to issue his own code red in late 2025.
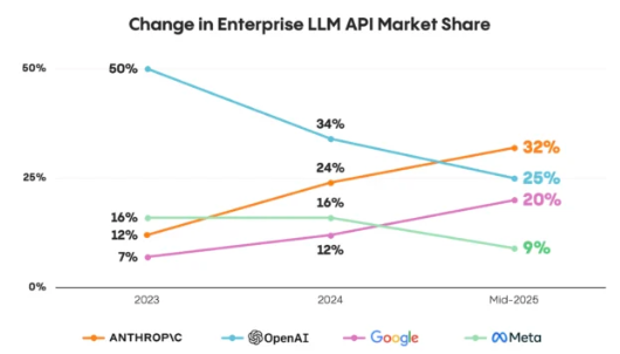
_Source: https://menlovc.com/perspective/2025-mid-year-llm-market-update/_
We believe Google is particularly well positioned in the AI race. First, vertical integration allows them to own more of the stack (from its own TPU chips to its own data centers) and reduce margin leakage to chipmakers like Nvidia and infrastructure providers. Second, strong organic cash flow gives them the ability to sustain aggressive pricing. Third, and perhaps most importantly, Google’s data advantage is unmatched, with decades of multimodal user data across Search, Maps, Gmail, Docs, YouTube, Photos, Android, etc. This diversity produces richer pretraining corpora, leading to better model generalization.
Taken together, these advantages give Google the option to push pricing meaningfully lower. While it hasn’t chosen to exercise this option yet (Gemini 3 API pricing is higher than GPT-5.1), doing so would place additional pressure on independent model labs. Over time, we expect Google to emerge as the price setter in this layer, with others becoming fast price followers.
By contrast, startups players such as OpenAI operate from a more complex position. They must simultaneously demonstrate to investors a path to profitability (which limits their ability to price aggressively), while continuing to raise hundreds of billions of dollars to remain competitive at the frontier. External estimates indicate that OpenAI will unlikely be profitable until 2030, whereas Anthropic may reach breakeven earlier, around 2027–2028.
Ultimately, the fate of these independent labs will hinge not only on their own execution, but also on continued investor belief and the decisions of incumbents such as Google and Microsoft, whose strategic choices can materially shape the competitive landscape. One important advantage independent labs like OpenAI and Anthropic has is their centrality to the broader ecosystem: a wide range of industry participants, including Nvidia and Oracle, have become economically dependent on its continued success, giving them a form of implicit strategic backing.
The reality is that we’re still early in the cycle and token prices remain high. Building a sustainable consumer AI business requires subsidizing usage upfront to accumulate the data that power the eventual moat and flywheel. In an environment where costs remain structurally high (partly due to Nvidia’s continued pricing power), well-capitalized, vertically integrated players like Google are simply better positioned to fund this flywheel over an extended period.
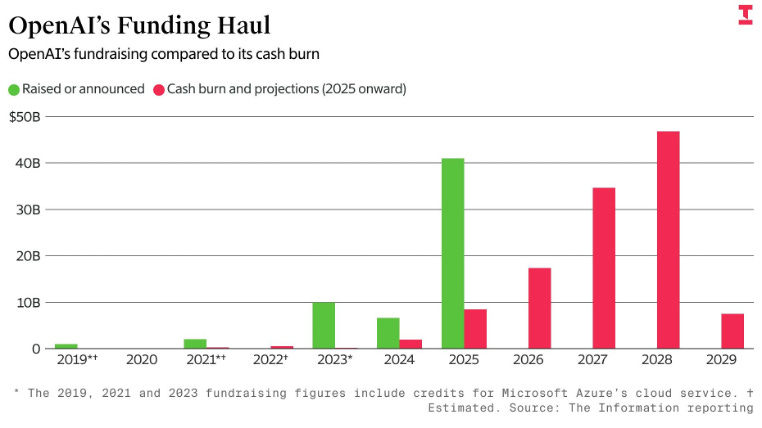
_Source: The Information_
**Our predictions for 2026 – Model Layer:**
- **At least one major lab will either pursue a public listing or be acquired –**Frontier model development is increasingly determined by **capital availability.**As private-market, financial-driven investors grow more cautious around the AI trade, independent labs will need to broaden their base of capital. In 2026, we expect to see more creative financing structures, including greater reliance on **debt-based financing**, such as asset-backed lending secured by GPUs or other hard assets. We also expect that at least one the of the labs will file for public offering. If these sources of financing are unavailable or limited, consolidation becomes the more likely outcome. In such scenario, the acquirer may likely to come from downstream players – either incumbents lacking a frontier model capability and seeking vertical integration (e.g., Oracle), or players even further down the stack.
- **Non-language models will develop faster than LLMs** – Earlier this year, Yann LeCunn remarked that he wasn’t so interested in LLMs anymore. Our own analysis shows that roughly two-thirds of AI venture funding since 2023 has been concentrated in LLM-centric technologies, compared to only ~10% for physical AI and ~5% for AI for sciences. As progress in language models begins to slow, we expect the next major breakthroughs to emerge from non-language modalities, such as physical world models, time-series models, and foundational models for sciences. The key bottleneck across these areas is data scarcity: unlike language which benefits from the open corpus of the internet, most other modalities lack large-scale, high-quality real-world data, making data generation and collection the primary challenge.
- **Data, not algorithmic innovation, will become the most important factor in model performance** – While large-scale RL and inference-time compute was all the rage this year, results from models like Gemini 3 demonstrate that large scale pretraining still matters. (For context, Gemini 3 was estimated to have used at least 2-3x more compute than GPT-5 in its pre-training). Sustaining progress at the frontier will therefore require access to larger volumes of high-quality, domain-specific data, increasingly sourced from real-world and proprietary sources. There are already several fast-growing startups in this area including Mercor and Micro1. We expect there to be a new wave of startups to emerge in this space.
- **Cost becomes significantly more important**–As the AI cycle enters its second phase, cost starts to matter a lot more. Enterprise AI budgets will begin to flatten over time, which forces companies to squeeze more value from their existing budgets. As a result, model selection increasingly becomes a finance decision rather than a purely technical one.
Cost pressures will favor inference efficiency over training breakthroughs and encourage greater experimentation with open-source models. Over time, margins at the model layer are likely to compress toward infrastructure-like returns, encouraging model companies to move up the stack into the application layer.
**APPLICATION LAYER:**
In most technology cycles, the majority of value ultimately accrued to the application layer. During the internet era, companies such as Google (search), Amazon (e-commerce), and Facebook (social networking) captured outsized value by introducing new ways for people to consume information, shop, and interact with each other. We believe the AI cycle will follow a similar pattern. While infrastructure and models provide the underlying scaffolding, long-term value will accrue to AI application companies that can fundamentally change how humans live and work.
On the enterprise side, what makes today’s AI so powerful comes down to two fundamental unlocks:
**(1) Redefining workflows through natural language as the primary user interface**
LLMs allow us to move away from complex multi-step workflows toward simple intent-driven instructions. Instead of forcing users to translate their goals into esoteric machine logic, users can now express what they want directly in natural language and abstract away all the complexities. A coding agent is a clear example of this: a developer can describe the desired outcome in plain English and let the agent generate and test code autonomously. This shift doesn’t just change how engineers get work done - it also broadens who can build software, enabling non-engineers to become product builders as well.
**(2) From “systems of record” to “systems of intelligence”**Today’s AI applications typically sit on top of existing Systems of Record (“SoR”) software - CRMs, ERPs, etc. But over time, AI will enable an entirely new system of _intelligence_. Instead of being organized around data schemas and rows, these systems are organized around intent, context, and state.
This shift is possible because AI can now reason across massive amounts of unstructured data across multiple systems and over time, surfacing context that no single system was designed to expose. For example, in many organizations, sales, customer support, and product teams historically operated in separate silos: sales insights lived in CRM notes and call transcripts, customer support data sat in tools like Zendesk and product decisions were often driven by a product manager’s intuition. AI can act as a unifying reasoning layer. By analyzing every sales call and support interaction, it can directly link feature requests to revenue and churn, allowing product teams to prioritize initiatives based on measurable business impact rather than intuition.
**Why AI-Native Companies Scale Faster Than SaaS:**
According to an analysis by Standard Metrics, AI-native companies with $1-20m ARR are on average, scaling 50% faster than traditional SaaS companies. We believe this is driven by several structural changes and tailwinds:
**(1) Clear, Measurable ROI** – AI-native applications tend to deliver clear and immediate ROI. Many are deployed against narrow, high-friction problems where value is quickly observable. For example, we invested in a company called Solve Intelligence that uses AI to write patents. By reducing the time required to write a patent by up to 80%, the product allows attorneys to take on more clients without increasing headcount, directly translating into higher revenue. The value proposition is explicit, quantifiable, and easy for buyers to justify.
**(2) Bottoms-up adoption** –Traditional SaaS was often a top-down decision. For example, if a company chose Salesforce as its CRM system, usage was mandated across the entire organization. By contrast, AI-native applications are frequently adopted by individual users or teams first, with enterprise deployments coming later. This allows many AI application startups to start out with a product-led/prosumer approach first and shorten their time-to-revenue.
**(3) Operating efficiency** - AI-native application startups can reach meaningful scale with far smaller teams. While the “one-person billion-dollar company” idea by Sam Altman is probably too extreme, the overall premise holds true. Our portfolio company Jobright was profitable from day one and scaled to tens of thousands of paid users organically. The Lean AI dashboard, which tracks AI-first companies with over $5M in ARR and fewer than 50 employees, shows an average revenue of approximately $2.5M per employee.
**(4) Increasing enterprise budgets** - According to research published by A16z, enterprise AI budgets in 2025 increased by ~200% year-over-year and are expected to grow a further ~75% in 2026. Many enterprises now have dedicated innovation budgets earmarked specifically for AI pilots. The challenge is that this rapid budget expansion has encouraged broad experimentation: enterprises are now testing many AI solutions in parallel. As a result, when evaluating AI startups, one must distinguish between durable, recurring spend and short-term pilot revenue.
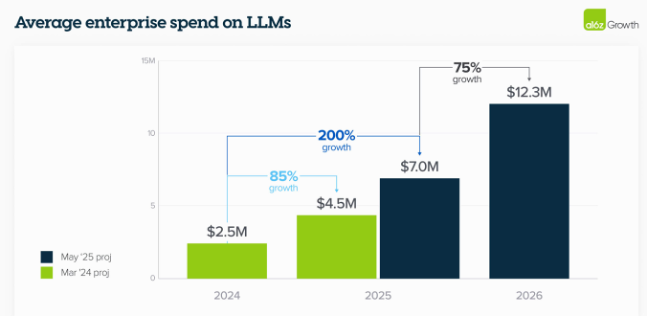
_Source: https://a16z.com/ai-enterprise-2025/_
Importantly, not all AI application startups benefit equally from these dynamics. We find that the most successful AI application companies are not competing on raw model intelligence – a battle that’s best left to the model companies. Instead, they win by tying the product to a measurable business outcome, and obsessively refining workflows and user experience.
While there are notable winners in the general-purpose space (Perplexity, Manus AI, and Genspark especially come to mind), the typical breakout AI application startup is more narrowly focused. They target a specific horizontal or vertical pain point, embed deeply into an existing workflow, and solve a problem users encounter frequently. This creates habitual usage, which drives a compounding loop of data, user feedback, and continuous product improvement.
**The year of vibe coding and multi-modal:**
In 2025, we several categories of AI applications that broke out. The common characteristics of these categories included:
(1) they address a high-frequency, high-value, task
(2) they operate in domains with clear success and failure signals and feedback loops
(3) the system can tolerate occasional mistakes at low cost
**Coding** - Coding experienced a rapid breakout in 2025, led by companies such as Replit, Cursor, and Lovable. “Vibe coding” entered the mainstream lexicon, and several of these companies now rank among the fastest-growing software businesses ever.
**Legal**– Legal has emerged as one of the strongest fits for Gen AI with companies like Harvey, EvenUp, Spellbook, and Solve Intelligence experiencing rapid growth. The category is well suited to GenAI because legal work is dominated by large volumes of unstructured text and the work is high value. Even modest productivity gains translate into meaningful ROI for the user.
**Multi-modal content generation** – Content generation followed a similar trajectory, seeing rapid adoption among creators and marketers. Platforms such as HeyGen, Higgsfield, Creatify, and OpenArt have scaled quickly by embedding AI directly into multimedia creative workflows.
In 2026, we expect a few additional breakout categories to emerge:
**Customer support** - Customer support represents a massive opportunity that has yet to fully break out. Adoption to date has been constrained by the long tail of edge cases. Klarna notably scaled back aspects of its AI-driven customer support initiatives after encountering these challenges. As agent reliability improves and voice AI matures, we expect adoption to accelerate.
**Vertical agents in traditional industries** – While many early AI application successes have focused on horizontal use cases, we expect a new wave of vertical startups to be more deeply workflow-embedded within legacy industries. Sectors such as healthcare, manufacturing, insurance, and asset management remain highly manual and process-driven, creating fertile ground for vertical agents that can automate domain-specific workflows. A good example of this is OpenEvidence, which is embedded directly into clinical workflows to help doctors quickly find and apply relevant medical evidence at the point of care.
**AI for sciences (beyond 2026)** – Longer term, we expect AI for sciences to move increasingly from research toward practical application. Early successes such as AlphaFold demonstrated that AI can meaningfully accelerate discovery, but broader adoption has been bottlenecked by long development cycles and the challenge of validating results in real-world settings. As the underlying models improve, we expect adoption to accelerate, particularly in areas such as drug discovery and materials science.
**Agentic AI – the long-term prize:**
Agentic AI represents the most ambitious opportunity in the application layer. The expectation is a world full of AI agents that can reason across complex environments, coordinate with other agents, and autonomously execute multi-step workflows. Importantly, what makes this opportunity especially powerful is not simply that agents can take actions (humans already do that), but that they can reason simultaneously across vast amounts of unstructured data, connect previously disparate concepts, and maintain context across time and changing conditions. Autonomous action closes the loop, but it is the superior reasoning abilities – not execution – that ultimately differentiates agents from traditional RPA-like automation.
The challenge is that the infrastructure required to enable this is still immature. As a result, despite the excitement, today’s agentic systems remain early, brittle, and unevenly deployed.
Over the past year, new protocols such as MCP, A2A, and A2P have emerged, aimed at making it easier for agents to use tools, communicate with each other, and transact. Of these, MCP is by far the most mature and widely adopted; the other protocols remain experimental and limited in real-world deployment. At the same time, the ecosystem remains fragmented, with no clear consolidation around agent frameworks such as LangChain, AutoGen, and LlamaIndex.
As a result, most agents today function as assistive copilots rather than true automation agents (see chart below for our definitions). Fully autonomous, multi-agent systems remain rare. The two primary bottlenecks today are long-horizon planning and memory/state management – specifically, an agent’s ability to persist context over time and share that context with other agents.
Adoption will therefore be uneven. We expect agentic use cases in internal operations and back-office workflows to mature first, where environments are controlled and the cost of failure is lower. Higher-risk domains, such as agentic payments, will likely lag.
If and when agents become reliable, the implications will be profound. AI shifts from augmenting/replacing the $500B software market to disrupting the $10T services market. Given the magnitude of this opportunity, we expect every major lab and technology company to compete aggressively to own the agent layer. The prize is simply too large to ignore. Recent moves, including Meta’s acquisition of Manus AI, underscore how strategically important agents have become, even if timelines for widespread adoption remain uncertain.
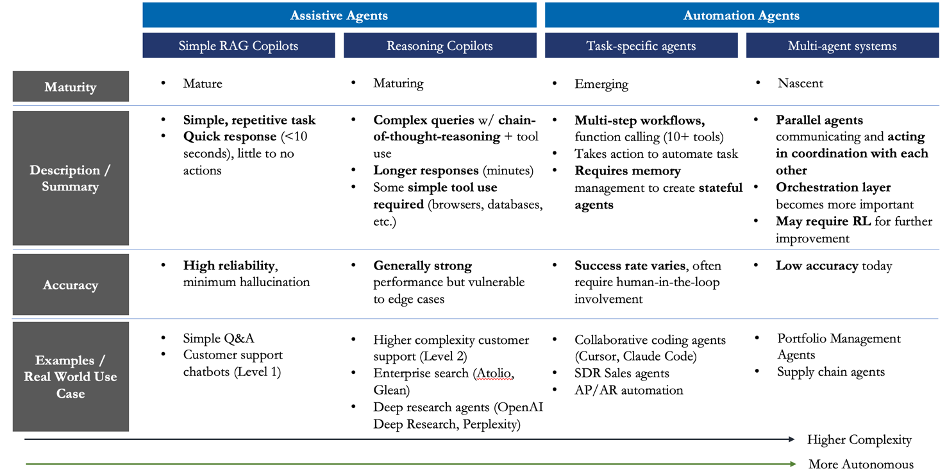
_Translink Capital’s agent taxonomy_
**Our predictions for 2026 – Application Layer:**
**Edge AI moves from experimentation to production deployments** – Improvements in small language models (SLMs) and edge hardware (e.g., NPUs) mean that much smaller models are now highly capable. Today’s 7B-parameter models can outperform the original 175B-parameter ChatGPT model. As a result, inference is increasingly shifting closer to where data is generated, particularly for latency-sensitive and security-sensitive workloads. A good example of the use of edge AI is our recent investment in AlphaVision, which deploys AI agents directly on existing CCTV cameras to monitor physical environments without streaming data to the cloud. Over time, edge AI will increasingly overlap with robotics, where real-time perception and action are critical.
**Robotics continues to gain momentum but remains constrained by bottlenecks** – We believe a true “ChatGPT moment” for robotics is coming, but it is likely still several years away. What has changed is the emergence of a new class of “robot brain” companies, such as Skild.ai and Physical Intelligence, which aims to make intelligence increasingly agnostic to hardware form factor.
A central question in robotics is whether the winning approach will be hardware-first or software-first. An analogy from the self-driving space is the contrast between Tesla/BYD approach and the Waymo/Baidu approach. In robotics, if the hardware-first, vertically integrated model wins, China likely holds the advantage. If the software-first approach prevails, the U.S. is better positioned. In practice however, geopolitical constraints are likely to result in winners on both sides.
Regardless of the prevailing approach, meaningful bottlenecks still remain – most notably data collection in real-world environments and dexterous manipulation. As a result, progress will be uneven. We expect increased real-world deployments in controlled business/enterprise settings in 2026, even as broader consumer adoption remains further out.
**ARE WE IN AN AI BUBBLE?**
The question of whether AI is in a bubble inevitably comes up today. As Howard Marks noted in his excellent memo recently, not all bubbles are created equal. Some are fueled primarily by speculation and leverage, while others are driven by genuine technological inflection points. This cycle clearly falls into the latter category.
That said, there are some signs of exuberance. A handful of AI startups are commanding valuations that appear quite disconnected from fundamentals, and there is a large degree of circularity in the ecosystem, where capital is effectively recycled from cash on one player’s balance sheet to revenue on another’s income statement. These dynamics can contribute to an overly frothy environment.
It is probable that an AI bubble will eventually form and correct. However, we don’t believe that inflection point will arrive in 2026 yet. Several factors suggest this:
- **Scale of investment remains modest relative to the opportunity –** In aggregate, roughly $1 trillion has been invested in the current AI cycle to date. While this is a large number, it represents only ~15–25% of what McKinsey estimates total AI-related spend could ultimately reach. By comparison, the internet and telecom cycle absorbed approximately $2–3 trillion (in today’s dollars) before peaking.
- **Technology investment cycles are long –**Historically, major technology buildouts have unfolded over 10–20 years. If we use ChatGPT as a reasonable starting point, we are only entering year four of the cycle.
- **Incumbent commitment remains strong.** Major technology incumbents have publicly reaffirmed aggressive AI investment plans and show little indication of spending pullback.
Taken together, these factors suggest that while there is some frothiness in the market, the AI cycle has not yet entered a late-stage phase. As such, we expect episodic valuation resets to be more likely than a full collapse.
**WHERE WE’RE FOCUSED ON IN 2026:**
As we look ahead, our focus is shaped by an observation that runs through this report: progress in AI is no longer constrained by raw model intelligence, but by systems, data, and messy real-world integration.
First, on the infrastructure side, we’re looking for startups that **unlock system-level bottlenecks**. As the infrastructure constraint shifts from chips to systems (power, networking and energy) opportunities are emerging for companies that improve reliability and utilization at the system level.
Second, we remain focused on **data infrastructure**, particularly novel approaches to data collection. As models mature, access to high-quality, domain-specific, and real-world data is becoming the primary driver of differentiation. This is especially true outside of language, where real-world data collection remains slow and expensive.
Third, we are spending more time on **agentic infrastructure**, including memory and security. As agents move from demos to production, these capabilities are becoming gating factors for enterprise adoption.
Fourth, we are increasingly focused on **vertical agents** that enable new systems of intelligence. We are particularly interested in agents embedded within existing systems that can automate high-frequency, high-value workflows.
Fifth, as language models mature, we expect more innovation to emerge from **non-language modalities** such as physical world models, time-series systems, and domain-specific models.
Finally, **edge AI** remains an area of interest for us. As cost pressure increases and latency, security, and reliability become more important, inference is moving closer to where data is generated. Edge deployments, including robotics, represent a growing share of AI value creation.
If you’re building in any of these areas, we’d welcome the opportunity to connect.
**ABOUT THE AUTHOR**
Kelvin is a Senior Principal at Translink Capital focused on artificial intelligence and machine learning. He looks at opportunities across the AI stack, including in infrastructure, foundational models, tooling and applications. Prior to joining Translink, Kelvin held various roles in business operations, strategy consulting, and investment banking in the United States and Canada. Kelvin holds an MBA from the Haas School of Business at UC Berkeley and a BA from the Ivey School of Business at Western University. In his spare time, Kelvin’s an avid reader and aims to read one non-fiction book per week. He’s also an aspiring amateur golfer who is on a quest to become a self-taught scratch golfer. He writes regularly about trends in AI, technology and business.
For the latest content, please follow him at:
LinkedIn: https://www.linkedin.com/in/kelvinmu/
Substack:
**ABOUT TRANSLINK CAPITAL**
Translink Capital is an early-stage VC firm founded in 2007 and based out of Palo Alto, California. Managing over $1 billion in AUM, Translink is backed by over 30 corporates from Asia, including multinationals such as Hyundai, NEC, LG, Foxconn, Sompo, and Japan Airlines. In addition to providing capital to startups, the firm focuses on connecting portfolio companies to their corporate LPs as customers or channel partners. The firm invest across the entire technology stack and typically write checks up to $10 million.
For more information, please visit: www.translinkcapital.com.