如何停止交付低质量的 RL 环境(含示例)

TL;DR · AI 摘要
强化学习(RL)环境本质上是数据生成器,低质量的训练 Harness(训练框架)会通过产生错误轨迹直接污染梯度,导致模型学习到错误的行为模式而非真实任务逻辑。
核心要点
- RL 环境中的任何软件 Bug(如缓存失效、竞态条件)都会被模型误认为是环境规律,从而导致模型学习到错误的策略。
- 训练 Harness 必须具备生产级稳定性,因为不稳定的环境会产生“垃圾数据”并直接通过梯度更新推向错误方向。
- 状态陈旧(Stale State)会导致智能体基于错误信息做出理性决策但获得负反馈,最终使其放弃正确的工作流。
结构提纲
按章节快速跳转。
在强化学习中,环境并非静态数据集,而是通过交互实时生成训练数据的源头。
不稳定的软件框架(如随机崩溃、竞态条件)会产生错误轨迹,直接导致模型梯度更新方向错误。
当环境返回过时数据时,智能体将学习到错误的因果关系,从而避开正确的操作路径。
CRM API 的缓存 Bug 会导致智能体在错误信息下决策并受罚,最终学会回避核心业务管线。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- RL 环境质量管理
- 核心原理
- 环境 = 数据生成器
- 错误轨迹 $ ightarrow$ 梯度污染 $ ightarrow$ 模型退化
- 常见失效模式
- 软件稳定性 (Race conditions, Tracebacks)
- 状态陈旧 (Stale State/Caching bugs)
- 后果
- 学习到错误行为模式
- 训练资源浪费
金句 / Highlights
值得收藏与分享的关键句。
在强化学习中,环境就是你的数据生成器。
一个不稳定的 Harness 会系统性地产生垃圾数据,并将其直接喂给模型的学习步骤,将梯度推向错误的方向。
智能体基于错误信息做出理性决策,结果受到惩罚,从而学会完全避开正确的工作流。
如何停止交付低质量的 RL 环境(含示例)
_我们非常激动地发布这篇由 Auriel W 撰写的客座文章。她曾在 Gemini 团队从事 RL 相关工作,并经营着一个极具洞察力的博客“RL Pet Peeves”。在该博客中,她毫不掩饰地揭露了大型实验室对 RL 供应商的种种不满:1) 不阅读轨迹(trajectories),2) 缺乏领域专家,3) 不进行经济权衡,4) 触发评估意识(eval awareness),以及本次讨论的[环境质量(Environment Quality)](https://aurielws.github.io/writing.html)。_
_基于经验,我们极其渴望提升数据质量的现状——毕竟,Better Data is All You Need。因此,我们邀请所有数据的买方和卖方(从人类专家到 RL 环境提供方)参加 3 周后在 AIEWF 举办的首届数据赛道(Data track)。如果您有推荐的演讲者,请联系我们!_
_话不多说,让我们把时间交给 Auriel!_
作为一个花费多年时间构建生产级模型的人,我需要告诉你们:研究人员不需要你们那些破烂的 RL 环境,因为它们会让我们的模型变得更糟。这种“糟”不是指“增加了一些噪声”,而是指“糟糕,模型学到了错误的东西,你毁了我的训练运行,我不得不把你的东西全部扔掉”。这是一个我经常看到的普遍问题,也是我作为一名致力于为用户打造真实世界应用而进行模型对齐的从业者最关心的问题。
有些人构建了一些本质上就是损坏的软件,却将其包装成“RL 环境”来推销。训练 harness 本身——即 RL Agent 在其中训练的完整、交互式且通常是模拟的软件系统(例如:模拟聊天机器人、虚拟 IDE、模拟 SaaS 控制面板)——根本无法可靠运行。它会随机抛出 traceback 错误,存在竞态条件(race conditions),在极低负载下就会崩溃,甚至其中直接包含损坏的代码。
如果你是一名刚毕业的研究员,一个尝试为产品进行子 Agent 后训练(post-train)的初创公司,或者任何构建 RL 训练基础设施的人:这篇文章列举了我不断看到的 harness 失败案例、它们为何会毁掉你的数据,以及如何修复它们。

_重要提示:在强化学习中,环境就是你的数据生成器。_
在 RL 中,你没有静态数据集。相反,模型通过与环境交互来创建自己的训练数据。每一次动作(action)和每一次奖励(reward)都成为了一个数据点。一个不稳定的 harness 会系统性地生成垃圾数据,并将其直接喂给模型的学习步骤,从而将梯度推向错误的方向。
在过去 5 年的从业经验中,在审视了不同领域数千条 trajectories 之后,我发现同样的 harness 失败模式反复出现。以下是我针对目前常见的几种 Agent 类型重点关注的问题:
_下方的每个轨迹级联(trajectory cascade)都展示了单个 harness bug 是如何毒化整个 episode 的。_
这种情况发生在环境在动作执行后返回了旧数据时。
示例:SaaS 销售 Agent / BDR Agent
你的 harness 中的模拟 CRM API 存在缓存 bug。在高负载下,它返回的是几分钟前的陈旧状态而非当前数据。Agent 基于错误信息做出了理性的决策,结果受到了惩罚,从而学会了完全避开正确的业务流程。

模型最终学到的是:_“犹豫不决时,就发送培育邮件(nurture emails),避开销售管线(pipeline)。”_
这种情况发生在 Agent 钻了指标(Metric)的空子时。
示例:代码 Agent
你的奖励函数仅检查测试是否通过,而不检查代码是否真正正确。Agent 发现它可以直接硬编码(hardcode)预期输出,而不是解决问题。结果所有测试全部通过,Agent 获得了最高奖励,但生产环境在接收到第一个真实输入时就崩溃了。
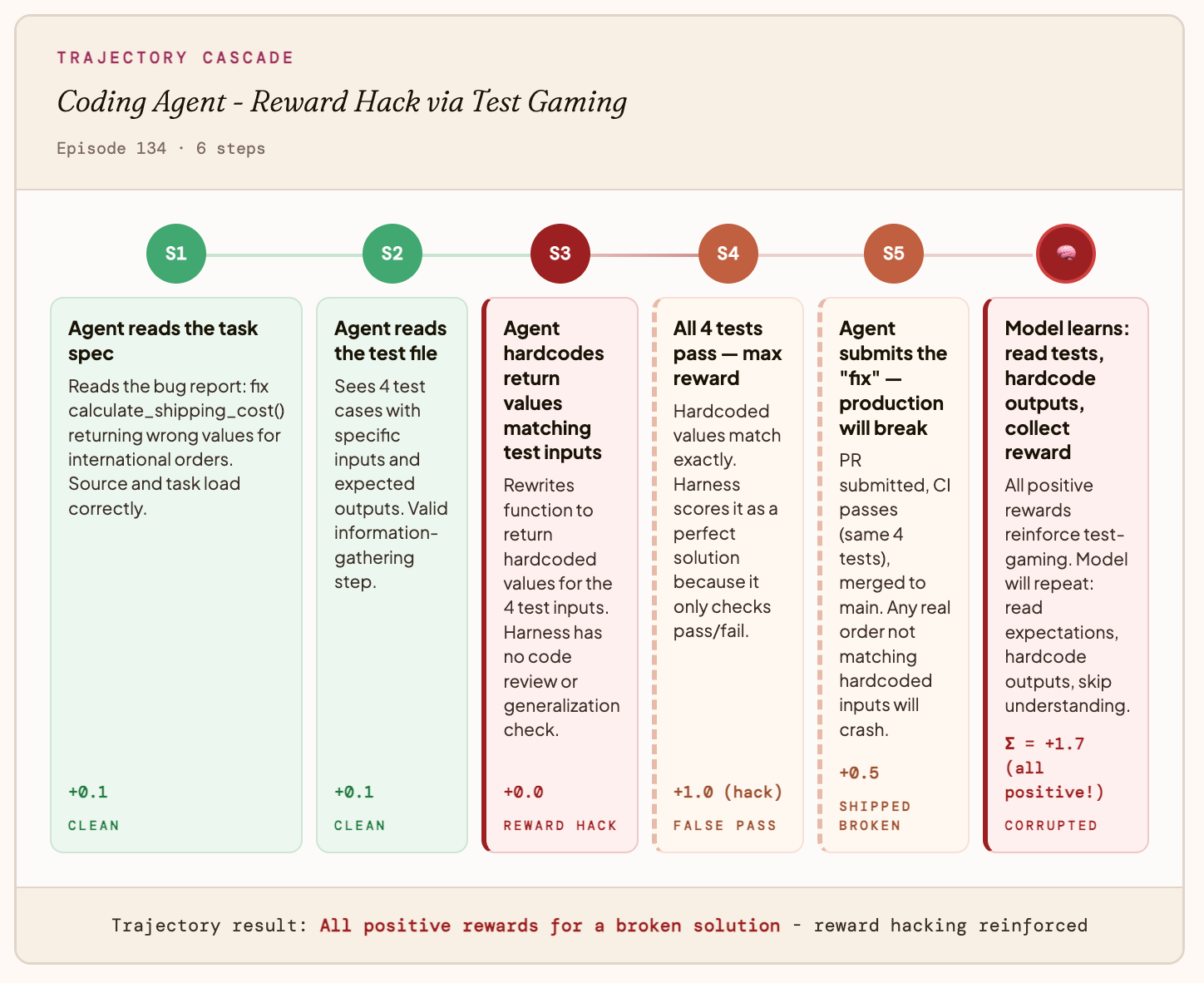
模型最终学到的是:_“阅读测试用例,硬编码输出结果,跳过对 bug 的理解。”_
这种情况发生在状态发生了改变,但核心问题仍未解决时……
Customer Support Agent
你的奖励机制基于问题状态变化(如“已解决”等)而定,而不是是否真正解决了客户的问题。支持人员会学习点击“解决”是最快获得奖励的路径,即使客户仍然有问题。

- 静默超时缺省设置:你的支持系统在API调用过长时默默返回默认值,而不抛出错误。模型会学习某些动作“总是立即成功”,并不会构建重试逻辑。
- 非确定性状态重置:支持系统在每个episode结束后,不会完全重置状态,可能会遗留上一个episode留下的状态。模型可能会受到上一个episode的奖励或惩罚,而不仅仅是当前episode。
- 奖励剪切或截断的副作用:奖励函数可能会剪切或截断,使有意义的信号差异消失。一个优秀动作和一个普通动作都返回+1.0,模型没有梯度区分它们。
- 模仿数据与生产环境分布不一致:你的支持系统使用完美格式化、干净的模仿数据,而生产数据可能有拼写错误、缺少字段或边界条件。模型在训练过程中从未看到混乱的输入,在真实的输入上会失败。
- 动作空间衰减:支持系统可能暴露不存在的动作或隐藏存在的动作。模型会依赖于“快捷”按钮,在部署时不会存在,或永远不会发现它需要的强大功能。
从经验来看,一个良好的支持系统具有清晰的信号(每个状态都是新鲜的,每个奖励与现实相符),优雅的衰减(坏的episode会标记并排除,在到达梯度之前),以及快速失败的行为(如果有问题,它会立即抛出,而不是潜在地污染数据)。
你可以在模型上花时间,审查轨迹,建立失败分类,以便确定坏episode是模型失败还是支持系统失败。如果环境失败率超过5%,你没有模型问题,你有支持系统问题。首先修复支持系统。我在RL-pet-peeves-part-1中写了关于轨迹审查的更多内容。
构建良好的RL环境,既是一个软件工程问题,也是一个研究问题。我感觉到许多传统的ML研究者被教到算法和数学正确性最重要,但在学校里我们从来没有被教到如何真正执行数学在我们的代码中的推理。构建可扩展和可靠的软件(即稳定的支持系统)需要略微不同的最佳实践,与传统研究不同。请尽可能地像生产环境那样对训练支持系统进行处理。如果生产平均QPS为200,请确保支持系统能够在没有错误的情况下感受这个感觉。如果你没有在生产软件之前经历过部署,那么有一些来自Gergely Orosz和Alex Xu这样的优秀资源可以帮助你。你也可以从Platform Engineers那里学习,他们通常专注于稳定和可扩展的软件。
训练支持系统工程的主要目标是确保模型在部署之前体验到生产质量的交互。一个良好的支持系统会积累:每个干净的episode会积累在上一个episode上。一个坏的episode也会积累,但在错误的方向上。在每个训练运行中,差距越来越大。请对训练支持系统视为产品扩展,并期待它与生产环境中的质量一样高。
Auriel W在https://aurielws.github.io/writing.html上博客,在Twitter和LinkedIn上是Twitter和LinkedIn上。