Reinforcement fine-tuning with LLM-as-a-judge
- RFT利用自动化奖励信号精调LLMs,解决准确性、政策对齐和表达问题。
- LLM-as-a-judge通过综合评估(如正确性、语气、安全、相关性)提供更灵活强大的模型对齐。
- 相比传统RFT,RLAIF无需手动精细设计奖励信号,提高了对齐效率和适应性。
Large language models (LLMs) now drive the most advanced conversational agents, creative tools, and decision-support systems. However, their raw output often contains inaccuracies, policy misalignments, or unhelpful phrasing—issues that undermine trust and limit real-world utility. _Reinforcement Fine‑Tuning (RFT)_ has emerged as the preferred method to align these models efficiently, using _automated reward signals_ to replace costly manual labeling.
At the heart of modern RFT is reward functions. They’re built for each domain through verifiable reward functions that can score LLM generations through a piece of code (Reinforcement Learning with Verifiable Rewards or RLVR) or with LLM-as-a-judge, where a separate language model evaluates candidate responses to guide alignment (Reinforcement Learning with AI Feedback or RLAIF). Both these methods provide scores to the RL algorithm to nudge the model to solve the problem at hand. In this post, we take a deeper look at how RLAIF or RL with LLM-as-a-judge works with Amazon Nova models effectively.
**Why RFT with LLM‑as‑a-judge compared to generic RFT?**
Reinforcement Fine-Tuning can use any reward signal, straightforward hand‑crafted rules (RLVR), or an LLM that evaluates model outputs (LLM-as-a-judge or RLAIF). RLAIF makes alignment far more flexible and powerful, especially when reward signals are vague and hard to craft manually. Unlike generic RFT rewards that rely on blunt numeric scoring like substring matching, an LLM judge reasons across multiple dimensions—correctness, tone, safety, relevance—providing context-aware feedback that captures subtleties and domain-specific nuances without task-specific retraining. Additionally, LLM judges offer built-in explainability through rationales (for example, “Response A cites peer-reviewed studies”), providing diagnostics that accelerate iteration, pinpoint failure modes directly, and reduce hidden misalignments, something static reward functions can’t do.
**Implementing LLM-as-a-judge: Six critical steps**
This section covers the key steps involved in designing and deploying LLM-as-a-judge reward functions.
**Select the judge architecture**
The first critical decision is selecting your judge architecture. LLM-as-a-judge offers two primary evaluation modes: _Rubric-based (point- based) judging_ and _Preference-based judging_, each suited to different alignment scenarios.
**Criteria****Rubric-based judging****Preference-based judging** Evaluation method Assigns a numeric score to a single response using predefined criteria Compares two candidate responses side-by-side and selects the superior one Quality measurement Absolute quality measurements Relative quality through direct comparison Preferred used when Clear, quantifiable evaluation dimensions exist (accuracy, completeness, safety compliance)Policy model should explore freely without reference data restrictions Data requirements Only requires careful prompt engineering to align the model to reward specifications Requires at least one response sample for preference comparison Generalizability Better for out-of-distribution data, avoids data bias Depends on quality of reference responses Evaluation style Mirrors absolute scoring systems Mirrors natural human evaluation through comparison Recommended starting point Start here if preference data is unavailable and RLVR unsuitable Use when comparative data is available
**Define your evaluation criteria**
After you’ve selected your judge type, articulate the specific dimensions that you want to improve. Clear evaluation criteria are the foundation of effective RLAIF training.
**For Preference-based judges:**
Write clear prompts explaining what makes one response better than another. Be explicit about quality preferences with concrete examples. Example:_“Prefer responses that cite authoritative sources, use accessible language, and directly address the user’s question.”_
**For Rubric-based judges:**
We recommend using Boolean (pass/fail) scoring for rubric-based judges. Boolean scoring is more reliable and reduces judge variability compared to fine-grained 1–10 scales. Define clear pass/fail criteria for each evaluation dimension with specific, observable characteristics.
**Select and configure your judge model**
Choose an LLM with sufficient reasoning capability to evaluate your target domain, configured through Amazon Bedrock and called using a reward AWS Lambda function. For common domains like math, coding, and conversational capabilities, smaller models can work well with careful prompt engineering.
**Model tier****Preferred for****Cost****Reliability****Amazon****Bedrock model** Large/Heavyweight Complex reasoning, nuanced evaluation, multi-dimensional scoring High Very High Amazon Nova Pro, Claude Opus, Claude Sonnet Medium/Lightweight General domains like math or coding, balanced cost-performance Low-Medium Moderate-High Amazon Nova 2 Lite, Claude Haiku
**Refine your judge model prompt**
Your judge prompt is the foundation of alignment quality. Design it to produce structured, parseable outputs with clear scoring dimensions:
- **Structured output format**– Specify JSON or parseable format for straightforward extraction
- **Clear scoring rules**– Define exactly how each dimension should be calculated
- **Edge case handling**– Address ambiguous scenarios (for example, “If response is empty, assign score 0”)
- **Desired behaviors**– Explicitly state behaviors to encourage or discourage
**Align judge criteria with production evaluation metrics**
Your reward function should mirror the metrics that you will use to evaluate the final model in production. Align your reward function with production success criteria to enable models designed for the correct objectives.
**Alignment workflow:**
1. **Define**production success criteria (for example, accuracy, safety) with acceptable thresholds 2. **Map** each criterion to specific judge scoring dimensions 3. **Validate** that judge scores correlate with your evaluation metrics 4. **Test** the judge on representative samples and edge cases
**Building**a robust reward Lambda function
Production RFT systems process thousands of reward evaluations per training step. Build a resilient reward Lambda function to help provide training stability, efficient compute usage, and reliable model behavior. This section covers how to build a reward Lambda function that’s resilient, efficient, and production ready.
**Composite reward score structuring**
Don’t rely solely on LLM judges. Combine them with fast, deterministic reward components that catch obvious failures before expensive judge evals:
**Core components**
**Component****Purpose****When to use** Format correctness Verify JSON structure, required fields, schema compliance Always – catches malformed outputs immediately. Cheap and instant feedback. Length penalties Discourage overly verbose or terse responses When output length matters (for example, summaries) Language consistency Verify responses match input language Critical for multilingual applications Safety filters Rule-based checks for prohibited content Always – prevents unsafe content from reaching production
**Infrastructure readiness**
1. **Implement exponential backoff:** Handles Amazon Bedrock API rate limits and transient failures gracefully 2. **Parallelization strategy**: Use ThreadPoolExecutor or async patterns to parallelize judge calls across rollouts to reduce latency 3. **Avoid Lambda cold start delays:** Set an appropriate Lambda timeout (15 minutes recommended) and provisioned concurrency (~100 for typical setups) 4. **Error handling:** Add comprehensive error handling that returns neutral/noisy rewards (0.5) rather than failing the entire training step
**Test your reward Lambda function for resilience**
Validate judge consistency and calibration:
- **Consistency**: Test judge on the same samples multiple times to measure score variance (should be low for deterministic evaluation)
- **Cross-judge comparison:**Compare scores across different judge models to identify evaluation blind spots
- **Human calibration:** Periodically sample rollouts for human review to catch judge drift or systematic errors
- **Regression testing:**Create a “judge test suite” with known good/bad examples to regression test judge behavior
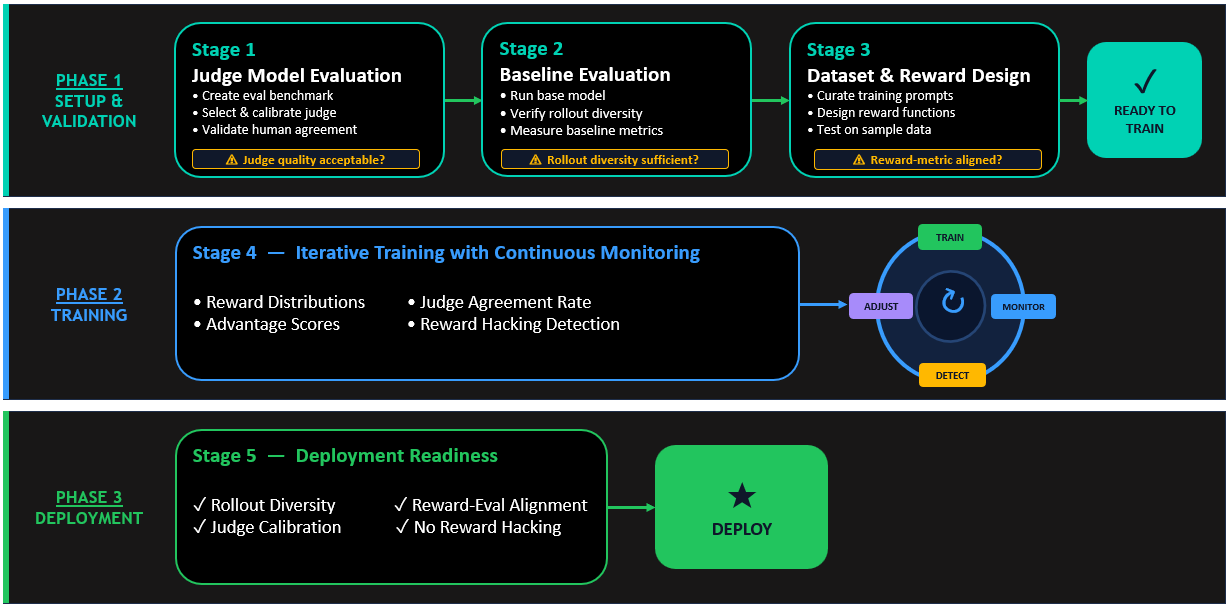
**RFT with LLM-as-a-judge – Training workflow**
The following diagram illustrates the complete end-to-end training process, from baseline evaluation through judge validation to production deployment. Each step builds upon the previous one, creating a resilient pipeline that balances alignment quality with computational efficiency while actively preventing reward hacking and supporting production-ready model behavior.
**Real-world case study: Automating legal contract review**
In this section, we refer to a real-world use case with a leading legal industry partner. The task is to generate comments on risks, assessments, and actions on legal documentation with respect to the policies and previous contracts as reference documents.
**Challenge**
Partner was interested in solving the problem of automating the process of reviewing, assessing, and flagging risks in legal contract documents. Specifically, they wanted to evaluate potential new contracts against internal guidelines and regulations, past contracts, and laws of the country pertaining to the contract.
**Solution**
We formulated this problem as one where we are providing a target document (the “contract” that needs evaluation), and a reference document (the grounding document and context) and expect the LLM to generate a JSON with multiple comments, comment types, and recommended actions to take based on the assessment. The original dataset available for this use case was relatively small that included complete contracts along with annotations and comments from legal experts. We used LLM as a judge using GPT OSS 120b model as the judge and a custom system prompt during RFT.
**RFT workflow**
In the following section we cover details of the key aspects in the RFT workflow for this use case.
#### **Reward Lambda function for LLM-as-a-judge**
The following code snippets present the key components of the reward Lambda function.
**Note**: name of Lambda function should have “SageMaker”, for example, `"arn:aws:lambda:us-east-1:123456789012:function:MyRewardFunctionSageMaker"`
**a) Start with defining a high-level objective**
# Contract Review Evaluation - Unweighted Scoring
You are an expert contract reviewer evaluating AI-generated comments. Your PRIMARY objective is to assess how well each predicted comment identifies issues in the TargetDocument contract clauses and whether those issues are justified by the Reference guidelines.JSON
**b) Define the evaluation approach**
## Evaluation Approach
For each sample, you receive:
- **TargetDocument**: The contract text being reviewed (the document under evaluation)
- **Reference**: Reference guidelines/standards used for the review (the evaluation criteria)
- **Prediction**: One or more comments from the AI model
**Important**: The SystemPrompt shows what instructions the model received. Consider whether the model followed these instructions when evaluating the prediction quality.
**CRITICAL**: Each comment must identify a specific issue, gap, or concern IN THE TARGETDOCUMENT CONTRACT TEXT ITSELF. The comment's text_excerpt field should quote problematic contract language from the TargetDocument, NOT quote text from the Reference guidelines. The Reference justifies WHY the contract clause is problematic, but the issue must exist IN the contract.
Evaluate EACH predicted comment independently. Comments should flag problems in the contract clauses, not merely cite Reference requirements.Plain text
**c) Describe the scoring dimensions with clear specifications on how a particular score should be calculated**
## Scoring Dimensions (Per Comment)
**EVALUATION ORDER**: Evaluate in this sequence: (1) TargetDocument_Grounding, (2) Reference_Consistency, (3) Actionability
### 1. TargetDocument_Grounding
**Evaluates**: (a) Whether text_excerpt quotes from TargetDocument contract text, and (b) Whether the comment is relevant to the quoted text_excerpt
**MANDATORY**: text_excerpt must quote from TargetDocument contract text. If text_excerpt quotes from Reference instead, score MUST be 1.
- **5**: text_excerpt correctly quotes TargetDocument contract text AND comment identifies a highly relevant, valid, and notable issue in that quoted text
- **4**: text_excerpt correctly quotes TargetDocument contract text AND comment identifies a valid and relevant issue in that quoted text
- **3**: text_excerpt correctly quotes TargetDocument contract text AND comment is somewhat relevant to that quoted text, but concern has moderate validity
- **2**: text_excerpt correctly quotes TargetDocument contract text BUT comment has weak relevance to that quoted text, or concern is questionable
- **1**: text_excerpt does NOT quote TargetDocument contract text (quotes Reference instead, or no actual quote), OR comment is irrelevant to the quoted text
### 2. Reference_Consistency
...
...Plain text
**d) Clearly define the final output format to parse**
## Scoring Calculation
**Comment_Score** = Simple average of the three dimensions:
- Comment_Score = (TargetDocument_Grounding + Reference_Consistency + Actionability) / 3
**Aggregate_Score** = Average of all Comment_Score values for the sample
## Output Format
For each sample, evaluate ALL predicted comments and provide:{ "comments": [ { "comment_id": "...", "TargetDocument_Grounding": {"score": X, "justification": "...", "supporting_evidence": "Verify text_excerpt quotes actual TargetDocument contract text and comment is relevant to it"}, "Reference_Consistency": {"score": X, "justification": "...", "supporting_reference": "Quote from Reference that justifies the concern OR explain meaningful reasoning"}, "Actionability": {"score": X, "justification": "Assess if action is clear, grounded in TargetDocument and Reference, and relevant to comment"}, "Comment_Score": X.XX } ], "Aggregate_Score": { "score": X.XX, "total_comments": N, "rationale": "..." } } ``` ```
Plain text
**e) Create a high-level Lambda handler, providing sufficient multithreading for faster inference**
def lambda_handler(event, context):
scores: List[RewardOutput] = []
samples = event
max_workers = len(samples)
print(f"Evaluating {len(samples)} items with {max_workers} threads...")
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = [executor.submit(judge_answer, sample) for sample in samples]
scores = [future.result() for future in futures]
print(f"Completed {len(scores)} evaluations")
return [asdict(score) for score in scores]Python
#### **Deployment of the Lambda function**
We used the following AWS Identity and Access Management (IAM) permissions and settings in the Lambda function. The following configurations are required for reward Lambda functions. RFT training can fail if any of them are missing.
**a) Permissions for Amazon SageMaker AI execution role**
Your Amazon SageMaker AI execution role must have permission to invoke your Lambda function. Add this policy to your Amazon SageMaker AI execution role:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"lambda:InvokeFunction"
],
"Resource": "arn:aws:lambda:region:account-id:function:function-name"
}
]
}Code
**b) Permissions for Lambda function execution role**
Your Lambda function’s execution role needs basic Lambda execution permissions and the permissions to Invoke the judge Amazon Bedrock model.
**Note:** This solution follows the AWS shared responsibility model. AWS is responsible for securing the infrastructure that runs AWS services in the cloud. You are responsible for securing your Lambda function code, configuring IAM permissions, implementing encryption and access controls, managing data security and privacy, configuring monitoring and logging, and verifying compliance with applicable regulations. Follow the principle of least privilege by scoping permissions to specific resource ARNs. For more information, see Security in AWS Lambda and Amazon SageMaker AI Security in the AWS documentation.
**c) Add provisioned concurrency**
Publish a version of the Lambda and to enable the function to scale without fluctuations in latency, we added some provisioned concurrency.100 was sufficient in this case, however, there’s more room for cost improvements here.

**d) Set Lambda timeout to 15 mins**

#### **Customizing the training configuration**
We launched Nova Forge SDK that can be used for the entire model customization lifecycle—from data preparation to deployment and monitoring. Nova Forge SDK removes the need to search for the appropriate recipes or container URI for specific techniques.
You can use the Nova Forge SDK to customize training parameters in two ways: provide a full recipe YAML using recipe_path or pass specific fields using overrides for selective changes. For this use case, we use overrides to tune the rollout and trainer settings as shown in the following section.
# Launch training with recipe overrides
result = customizer.train(
job_name="my-rft-run",
rft_lambda_arn="<your-lambda-arn>",
overrides={
# Training config
"max_length": 64000,
"global_batch_size": 64,
"reasoning_effort": None,
# Data
"shuffle": False,
# Rollout
"type": "off_policy_async",
"age_tolerance": 2,
"proc_num": 6,
"number_generation": 8,
"max_new_tokens": 16000,
"set_random_seed": True,
"temperature": 1,
"top_k": 0,
"lambda_concurrency_limit": 100,
# Trainer
"max_steps": 516,
"save_steps": 32,
"save_top_k": 17,
"refit_freq": 4,
"clip_ratio_high": 0.28,
"ent_coeff": 0.0,
"loss_scale": 1,
},
)Python
#### **Results**
RFT with Amazon Nova 2 Lite achieved a 4.33 aggregate score—the highest performance across all evaluated models—while maintaining perfect JSON schema validation. This represents a significant improvement, demonstrating that RFT can produce production-ready, specialized models that outperform larger general-purpose alternatives.
We evaluated models using a **“best of k” single-comment setting,** where each model generated multiple comments per sample and we scored the highest-quality output. This approach establishes an upper bound on performance and enables a fair comparison between models that produce single versus multiple outputs.
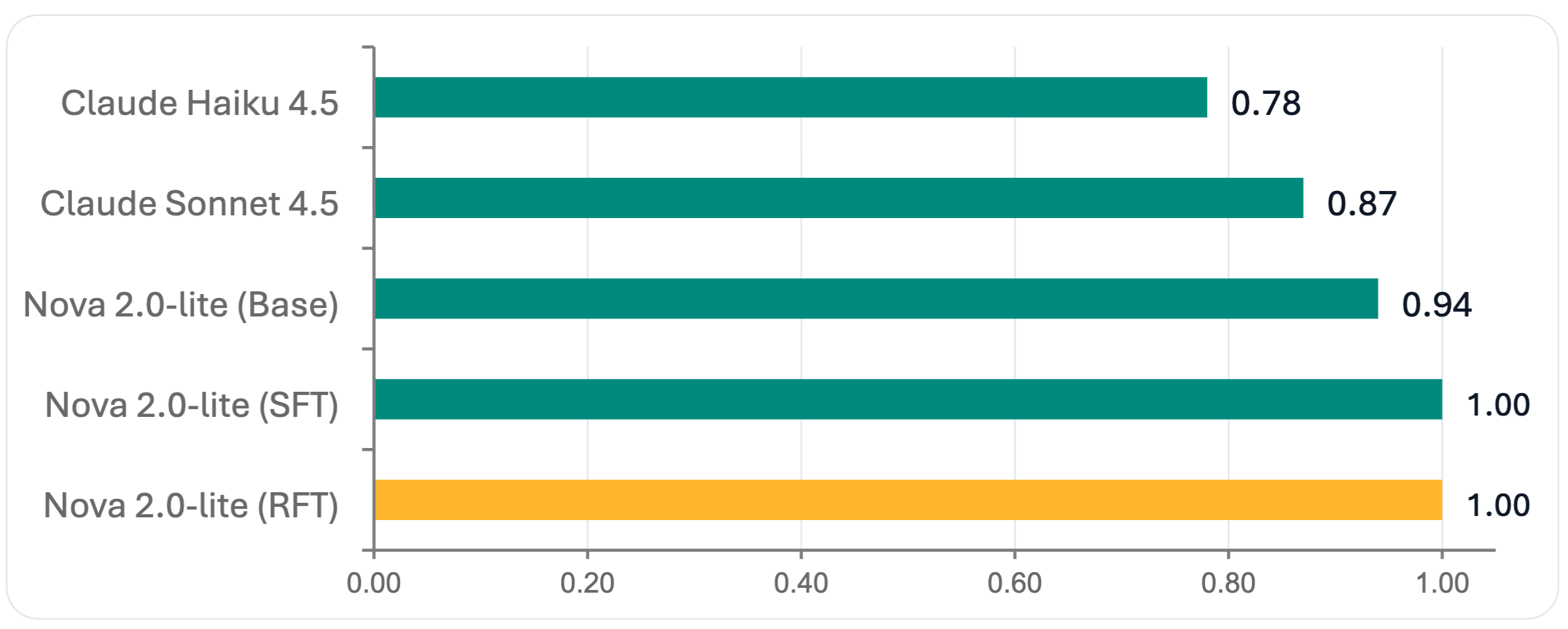
Figure 1 — JSON Schema Validation Scores (0–1 scale, higher is better)
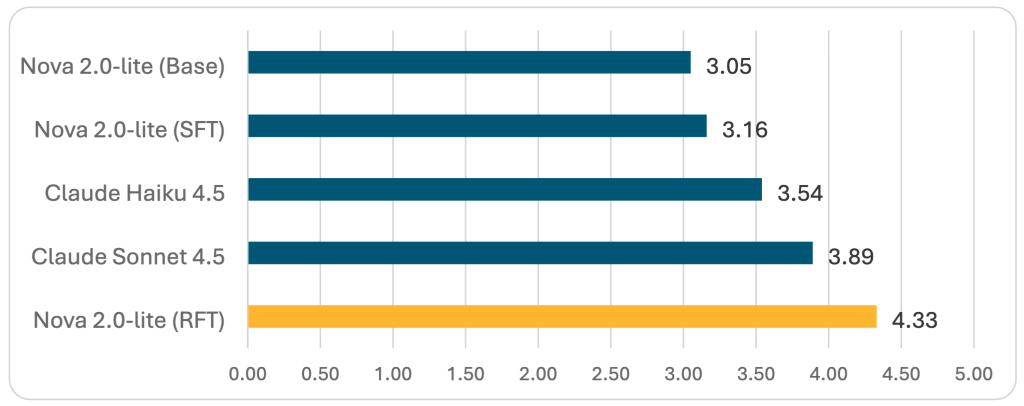
Figure 2 — Aggregate LLM judge scores (1–5 scale, higher is better)
**Key takeaways:**
1. **RFT achieved the highest performance among evaluated models in this study.**
Amazon Nova 2 Lite with RFT achieved a **4.33 aggregate** score, outperforming both Claude Sonnet 4.5 and Claude Haiku 4.5, while also achieving perfect **JSON schema validation.**
1. **Removes unnecessary training artifacts**
During SFT iterations, we observed problematic behaviors including repetitive comment generation and unnatural Unicode character predictions. These issues, likely caused by overfitting or dataset imbalances, didn’t appear in RFT checkpoints. RFT’s reward-based improvements naturally discourages such artifacts, **producing more robust and reliable outputs**.
1. **Strong generalization to new judge criteria**
When we evaluated RFT models using a modified judge prompt (aligned but not identical to the training reward function), performance remained strong. This demonstrates that RFT learns generalizable quality patterns rather than overfitting specific evaluation criteria. This is a critical advantage for real-world deployment where requirements evolve.
1. **Compute considerations**
RFT required 4–8 rollouts per training sample, increasing compute costs compared to SFT. This overhead is amplified when using non-zero reasoning effort settings. However, for mission-critical applications where alignment quality directly impacts business outcomes—such as legal contract review, financial compliance, or healthcare documentation, the performance gains justify the additional compute costs.
**Conclusion**
Reinforcement Fine-Tuning (RFT) with LLM-as-a-judge represents a powerful approach to aligning LLMs for domain-specific applications. As demonstrated in our legal contract review case study, this methodology delivers significant improvements over both base models and traditional supervised fine-tuning (SFT) approaches, with RFT achieving the highest aggregate scores across all evaluation dimensions.For teams building mission-critical AI systems where alignment quality directly impacts business outcomes, RFT with LLM-as-a-judge offers a compelling path forward. The methodology’s explainability, flexibility, and superior performance make it particularly valuable for complex domains like legal review (or Financial Services or Healthcare) where subtle nuances matter.
Organizations considering this approach should start small—validate their judge design on curated benchmarks, verify infrastructure resilience, and scale gradually while monitoring for reward hacking. With proper implementation, RFT can transform capable base models into highly specialized, production-ready systems that consistently deliver aligned, trustworthy outputs.
**_References_**:
1. Amazon Nova Developer Guide for Amazon Nova 2 2. Nova Forge SDK- GitHub 3. Reinforcement Fine-Tuning (RFT) with Amazon Nova models
**_Disclaimer:_**
The legal contract review use case described in this post is for technical demonstration purposes only. AI-generated contract analysis is not a substitute for professional legal advice. Consult qualified legal counsel for legal matters.
- * *
About the authors
问问这篇内容
回答仅基于本篇材料Skill 包
领域模板,一键产出结构化笔记论文精读包
把一篇论文 / 技术博客精读成结构化笔记:问题、方法、实验、批判、延伸阅读。
- · TL;DR(1 段)
- · 研究问题与动机
- · 方法概览
投融资雷达包
把一条融资 / 创投新闻整理成投资人视角的雷达卡:交易要点、判断、竞争格局、风险、尽调清单。
- · 交易要点(公司 / 轮次 / 金额 / 投资人 / 估值,材料未明示则写 “未披露”)
- · 投资 thesis(这家公司为什么值得关注)
- · 竞争格局与替代方案