Together AI 如何构建全球最快的语音转文字堆栈

TL;DR · AI 摘要
Together AI 通过使用基于 profiles 的 TensorRT 优化其语音转文字堆栈,通过优化解码器循环和改进 CPU 路径,实现了更快的转录速度。他们提供的两个最低延迟模型中,最快的模型可以在不到 10 秒内转录 20 小时的语音。
核心要点
- Together AI 建立了全球最快的语音转文字堆栈。
- 他们使用基于 profiles 的 TensorRT 优化编码器。
- 解码器循环通过移除 CPU 进行了优化。
结构提纲
按章节快速跳转。
- §引言
Together AI 优化其语音转文字堆栈以实现更快的转录速度。
文本和语音输入之间的处理差异影响模型和数据路径,使 ASR 服务成为涉及 GPU 执行、CPU 预处理、内存移动、传输、连接调度和运行时行为的全路径系统问题。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- Together AI's Speech-to-Text Stack Optimization
- Profile-aware TensorRT
- Encoder optimization
金句 / Highlights
值得收藏与分享的关键句。
Together AI 提供了两个最低延迟语音转文字模型:NVIDIA 的 Parakeet-TDT 0.6B v3 和 OpenAI 的 Whisper Large v3。
标题:如何 Together AI 建立了全球最快的语音转文字堆栈
来源:https://www.together.ai/blog/how-together-ai-built-the-worlds-fastest-speech-to-text-stack
发布时间:2026-05-29
Markdown 内容:
Artificial Analysis 报告了速度因素(输入音频秒数每秒转录的秒数)-- 越高越好
**模态很重要**
100 万个标记的文本提示可以容纳整个《哈利·波特》系列,但自身仅重约 5 MB。这个规模听起来很大,但输入本身是紧凑的。文本几乎准备好进行推理:分词、批处理、通过模型。
音频改变了问题的形状。《哈利·波特》系列作为有声书的总大小为 5 到 10 GB,比文本大三个数量级。在任何数据到达 GPU 之前,服务器需要解码容器、重采样、过滤噪声、运行 VAD、分割语音并计算音频特征。
模型方面也翻转了。当前的 LLM 拥有数十亿甚至数万亿个参数,所以服务工作自然集中在 GPU 内:量化、KV 缓存、注意力核、批处理和并行性。语音转文字模型要小得多,通常在数百万到低数十亿参数,因此周围的数据路径变得更加重要。
这使得 ASR 服务成为一个涉及 GPU 执行、CPU 预处理、内存移动、传输、连接调度和运行时行为的全路径系统问题。同一堆栈还需要服务两种不同的 regime:离线转录,吞吐量最重要,和流式转录,延迟和抖动为主。
Together 的 ASR 堆栈服务于两个最低延迟的语音转文字模型,由 Artificial Analysis 排名:NVIDIA 的 Parakeet-TDT 0.6B v3 和 OpenAI 的 Whisper Large v3。更快的是 NVIDIA Parakeet-TDT 0.6B v3,可以在不到 10 秒内转录大约 20 小时的语音,相当于《哈利·波特》电影系列的运行时间。
本文的其余部分将分解这一结果背后的变化:TensorRT 预 prof 文件,GPU 侧解码器控制流,低复制 CPU 路径,事件流 I/O,以及运行时 GC 控制。
**为实际音频形状编译编码器**
Parakeet 使用编码器-解码器架构,其约 95% 的权重位于编码器中。编码器接收可变长度的语音片段并为解码器生成声学帧,使其成为优化的首要目标。
音频输入跨越广泛的长度,从 200 毫秒的流式数据包到 30 秒的不间断语音。为一个输入形状优化的内核计划在另一个形状上可能慢得多,因此引擎需要在编译时知道它将看到的形状分布。
在 TensorRT 之前,我们已经使用了优化的 PyTorch 路径,使用 torch.compile 和 CUDA 图形,针对相同的形状配置进行了调整。这为我们提供了一个强大的基线:在 PyTorch 堆栈内进行 prof 文件感知执行。
TensorRT 为生产提供了更快的编码器路径。它提前构建优化的执行计划,可能在内核之间融合,调整内存布局,并针对我们预期服务的形状范围基准测试内核变体。
重要细节是 prof 文件调整。仅针对最大输入形状调整的单一 prof 文件迫使较短的音频片段进入填充路径,这对流式数据包和短发音尤其 costly。多 prof 文件的 TensorRT prof 文件让我们可以在内存中保留编码器权重的同时为每个请求选择合适的优化 prof 文件。
内存节省 modest,从约 6 GB 降低到 5 GB。更大的 wins 是避免不良形状匹配,并从优化的 PyTorch 转到 prof 文件调整的 TensorRT。在小输入 regime 中,prof 文件感知的 TensorRT 可以比通过大型填充 prof 文件发送这些请求快几倍。
编码器优化后,解码器循环成为下一个瓶颈。
**从解码器循环中移除 CPU**
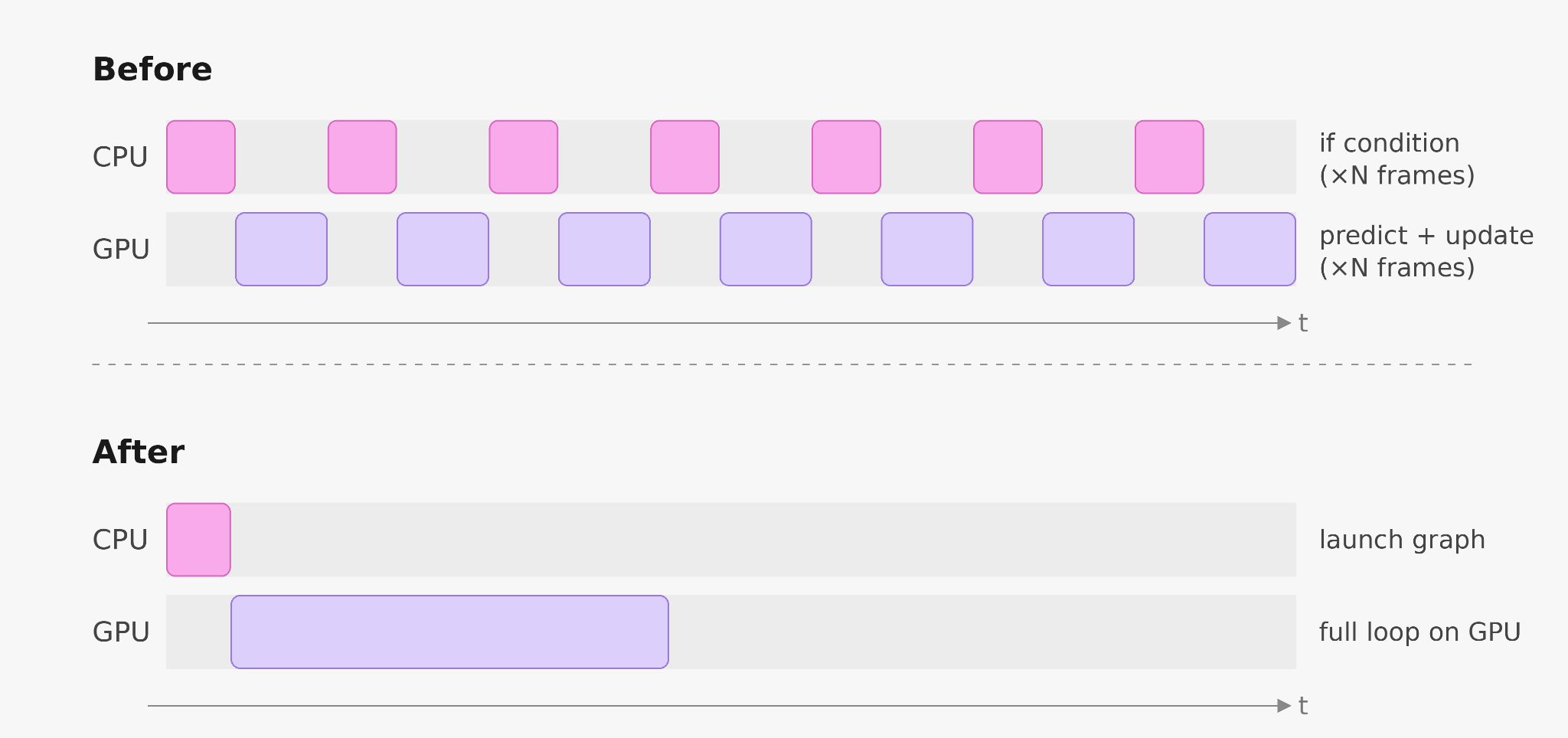
Parakeet 的解码器迭代编码器的声学帧并发射一个标记或 BLANK,对于不推进转录的帧。代码大致如下:
for frame in encoder_output:
token = predict(frame, state)
if token != BLANK:
emit(token)
state = update(state, token)```
在 prof 文件中,我们发现 `predict` 和 `update` 都很快。每次迭代的 GPU 工作 measured 在微秒级。
昂贵的行是分支:
`if token != BLANK:`
该分支要求 CPU 从 GPU 内存中读取标记,以决定采取哪条路径。这个 host 同步阻止了解码循环被捕捉为单个 CUDA 图形,并且每一次迭代都需要通过 Python 进行 round-trip。GPU 做几微秒的工作,等待 CPU,启动下一个内核,重复这个模式数千次每请求。
条件 CUDA 图形节点将这个分支移动到 GPU。一个小型设备侧内核评估条件并告诉 CUDA 运行时是否进入标记发射和状态更新子图。分支在不离开 GPU 的情况下解决,因此整个解码循环、计数器、条件、发射和状态更新可以被捕捉并作为单个 CUDA 图形启动。
CPU 离开了解码器的内循环,结果是解码器速度提高 2 到 3 倍。
## **停止复制音频字节**
一旦编码器和解码器运行良好,剩余的延迟来自于 CPU 路径。这通常是我们在审核的大多数 ASR 代码花费的延迟预算:不必要的进程边界、热路径上的冗余复制和单线程函数,这些函数可以受益于更高的并行性。
第一个杠杆是折叠不必要的进程边界。
音频预处理,无论是文件解码、采样率转换、声活动检测(VAD)、特征提取还是分块处理,大部分都是 I/O 或者原生 C/C++ 工作,这些工作会释放 Python 全局解释器锁(GIL)。典型的微服务架构将预处理划分为三到四个单独的过程,为不需要的隔离支付额外的代价。将这些工作合并到更少的过程中,可以消除内核复制和序列化/反序列化操作,这些操作在处理大文件时可能会花费数百毫秒。
当需要进程间通信时,常见的选项如 ZeroMQ 也会带来显著的开销。在我们的工作负载中,通过持久化 Unix 域套接字携带原始音频字节的简单自定义协议在高并发下表现最佳,因为这种协议将 framing 保持在最小,避免了重复的连接设置。
对于大文件,套接字仍然需要两次复制:生产者用户空间到内核缓冲区,然后内核缓冲区到消费者用户空间。为了避免这条路径,我们使用了共享内存。使用共享内存时,两个进程映射相同的物理区域,因此生产者写入的数据无需内核往返即可被消费者看到。这为我们提供了零复制数据路径。
复杂性成本是真实的,因此只有当数据量 justify 时,才值得使用共享内存。
## **使用事件 I/O 进行流式传输**
流式 ASR 添加了另一个问题:连接生命周期。
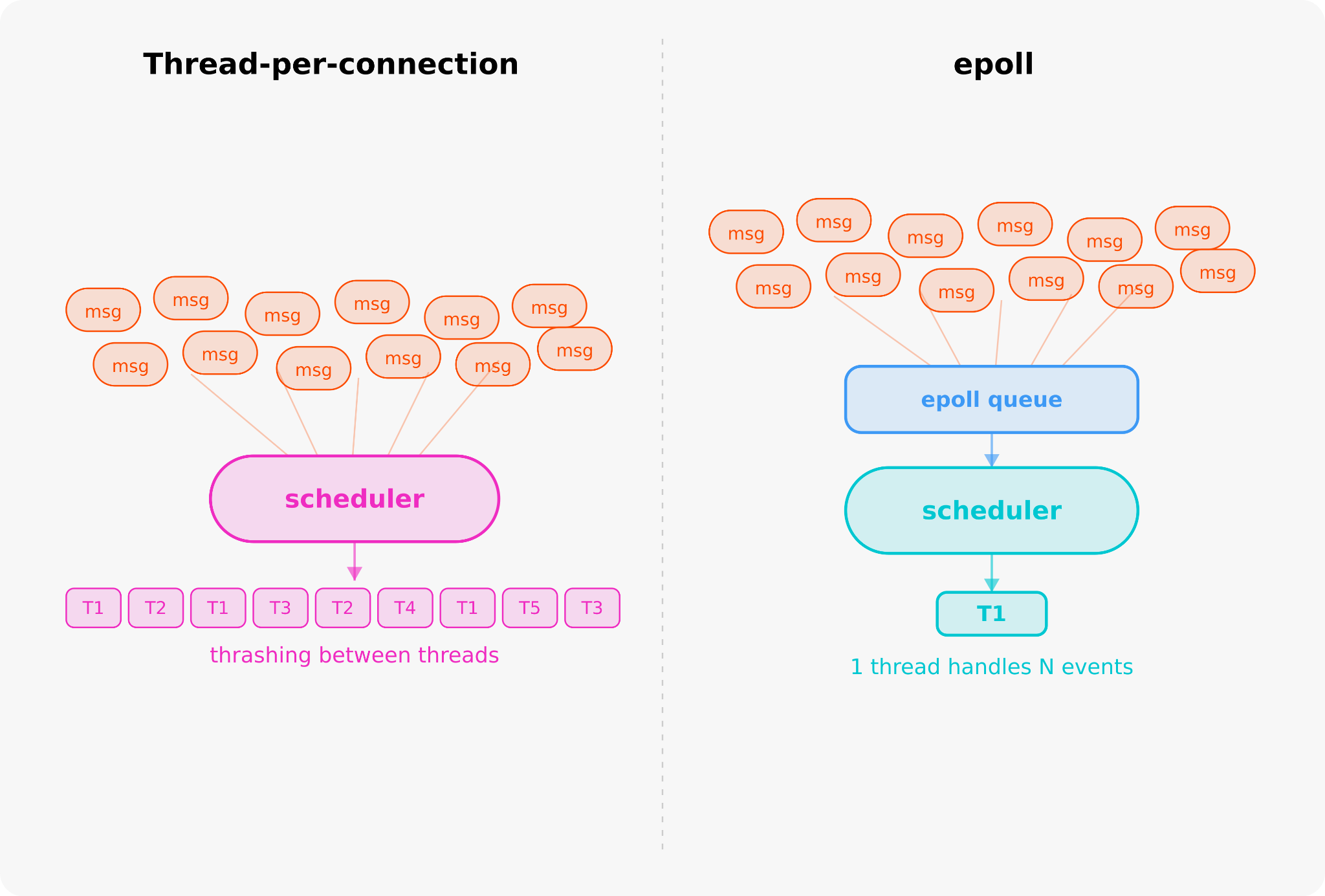
我们的第一个流式实现使用了每连接一个线程。当数百个流同时发送分块时,数百个线程同时唤醒,GIL 争用激增,尾延迟激增。
我们改用了一个线程阻塞在 `epoll`。
`epoll` 允许一个线程注册数千个连接,并在单个系统调用中询问内核:“当这些连接中有数据时唤醒我。”当消息到达时,内核返回完整的就绪集合,然后该线程处理活动套接字,处理完毕后再次进入等待状态。
相同的工作负载,调度压力小得多。对于流式 ASR,这种可预测性非常重要,因为延迟的 partial 脚本会使语音系统感觉缓慢,即使平均延迟看起来很正常。
## **冻结启动状态以消除 GC 尾延迟**
我们差点错过了这一点。
在流式工作流的高负载下,p50 和 p90 延迟看起来健康,但 p95 会周期性地增加约 200 毫秒。日志显示队列深度很小,GPU 时间正常,但 CPU 函数通常在 5 毫秒内运行,现在却需要超过 100 毫秒。
背景中的某项工作在占用请求循环的时间。
分析指向 Python 的垃圾收集器(GC)。Python 使用引用计数作为大多数内存管理的手段,有一个用于捕获引用环的周期检测收集器。这个收集器分代运行。最老的一代包含长寿命对象,全收集可能遍历一个大的对象图。
我们 startup 时预分配了一个大池子的缓冲区、模型状态和查找表,以避免稳定状态下的分配延迟。这些长寿命对象落在最老的一代中,因此全 GC 扫描遍历了数十万的引用。这就是 200 毫秒的停顿。
解决方法是在启动预分配后的一行代码:
`gc.freeze()`
`gc.freeze()` 告诉 Python 将预分配的状态排除在未来的 GC 扫描之外,因此正常请求作用域的对象仍然可以被收集,而巨大的初始状态则被单独留下。
p95 峰值消失了,p50 也有所改善,因为系统可以保持更平滑的流量模式。
教训是保持分析,不仅仅是模型。GPU 时间、队列深度和模型执行看起来都很正常,延迟尖峰出现在 Python 运行时。
## **语音延迟是一个端到端的系统问题**
语音代理通常运行在一个级联:ASR 生成转录,LLM 生成响应,TTS 生成音频。ASR 是这个路径中的第一阶段,所以它的延迟和抖动决定了用户可见的响应时间的最早界限。
上面的优化针对路径的不同部分。TensorRT 多配置引擎调整了编码器执行以适应实际的音频形状。条件CUDA图消除了解码循环中的 CPU 往返。持久化 Unix 域套接字、共享内存和 `epoll` 减少了 CPU 路径开销。`gc.freeze()` 消除了运行时层面的 p95 失败模式。
同样的约束适用于堆栈的其他部分:每个阶段都要控制模型执行、预处理、传输、调度和运行时行为的中位数延迟和尾延迟。
[NVIDIA Parakeet-TDT 0.6B v3](https://www.together.ai/models/parakeet-tdt-0-6b-v3) 和 [OpenAI Whisper Large v3](https://www.together.ai/models/openai-whisper-large-v3) 在 Together 上可用。如果您在生产中扩展语音 AI,请联系我们。
_Parakeet v3 是 v2 的继承者,v2 是一个仅支持英语的模型,它在 Hugging Face 开放 ASR 领先榜上单语言吞吐量方面遥遥领先。v3 大幅扩展了这一基础,将语言支持从英语扩展到 25 种欧洲语言,添加了自动语言检测功能,无需语言提示,并且是在 1.7 万小时的音频数据上训练的,包括 NVIDIA 的 Granary 多语言语料库。_