最新开源成果(#21):开源模型大爆发!Gemma 4、DeepSeek V4、Kimi K2.6、MiMo 2.5、GLM-5.1 等

TL;DR · AI 摘要
中国开源模型与美国前沿模型能力差距持续扩大,CAISI评估显示差距达3-7个月。
核心要点
- CAISI评估显示中国开源模型在多个基准测试中落后于美国模型,差距达3-7个月。
- DeepSeek V4在CTF-Archive-Diamond、PortBench和ARC-AGI-2等基准测试中表现不佳。
- 当前基准测试未充分反映模型真实能力,需使用更贴近训练环境的工具进行评估。
结构提纲
按章节快速跳转。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- 开源模型评估
- CAISI评估
- DeepSeek V4表现
- 基准测试方法
- 评估局限
- 测试环境不匹配
- 结果偏差
- 改进方向
- 使用训练环境工具
- 模型特定提示
金句 / Highlights
值得收藏与分享的关键句。
DeepSeek V4在CTF-Archive-Diamond、PortBench和ARC-AGI-2等基准测试中表现不佳。
当前基准测试未充分反映模型真实能力,需使用更贴近训练环境的工具进行评估。
因此,我们认为要进行开源与闭源模型的前沿比较,也需要更好地激发所有模型的能力。
最新开源成果 (#21): 开源模型大爆发!Gemma 4、DeepSeek V4、Kimi K2.6、MiMo 2.5、GLM-5.1 及其他
URL 源地址: https://www.interconnects.ai/p/latest-open-artifacts-21-open-model
发布时间: 2026-05-16T17:00:11+00:00
Markdown 内容: 本月非常忙碌,所有开源前沿实验室,包括 DeepSeek 都发布了新的模型。后者引发了 人工智能标准与创新中心 (CAISI) 的评估,该中心过去曾对开源模型及其风险进行过评估。其结果显示,开源模型在技术前沿方面落后于美国,且差距随着时间推移而不断扩大:
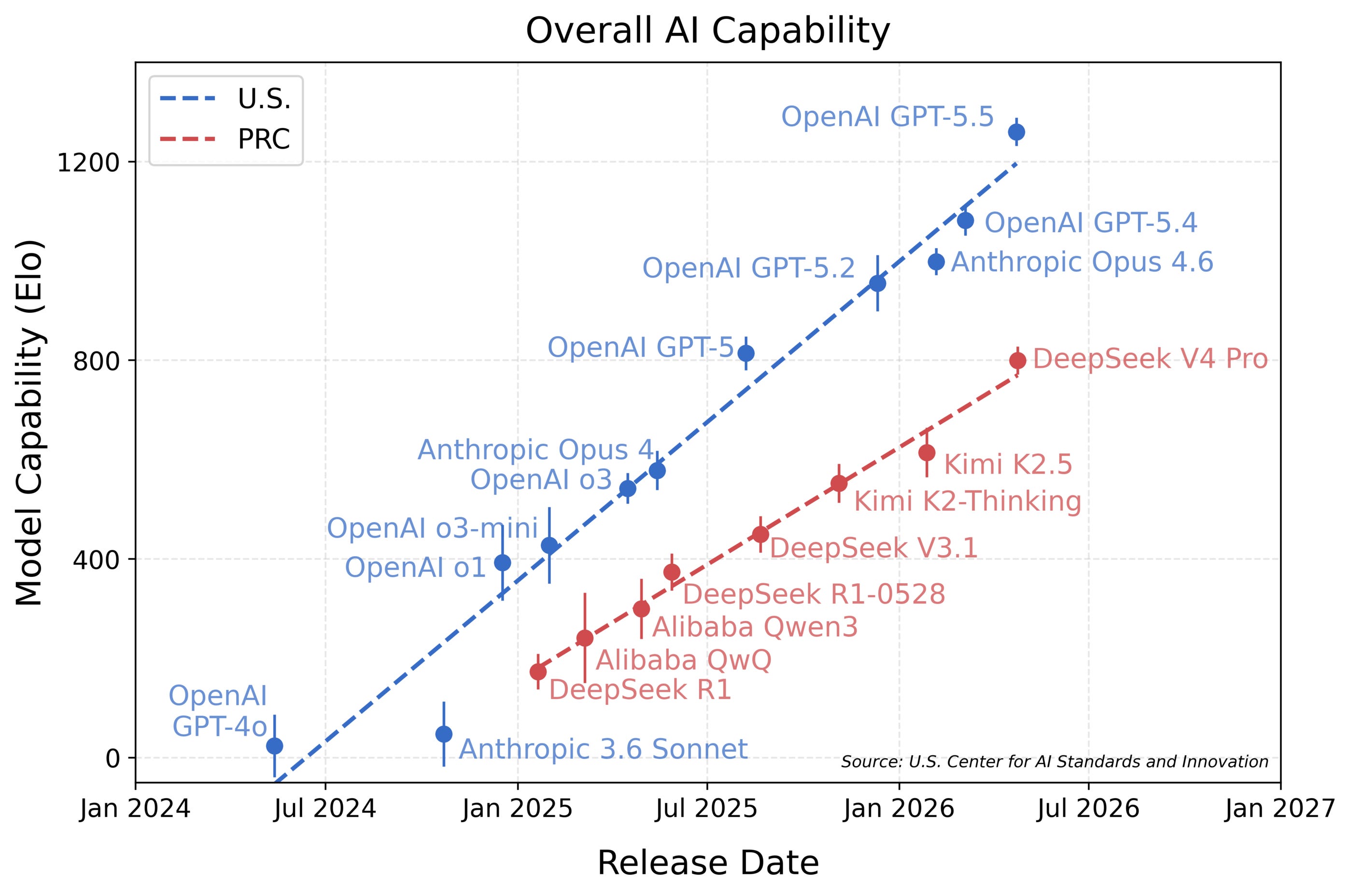
在报告中,他们基于 项目反应理论 计算了一个 Elo 分数,这是一种常用于比较不同模型的方法,即使这些模型是在不同的基准测试集上进行测试的。对于 V4,CAISI 使用了九个不同的基准测试:
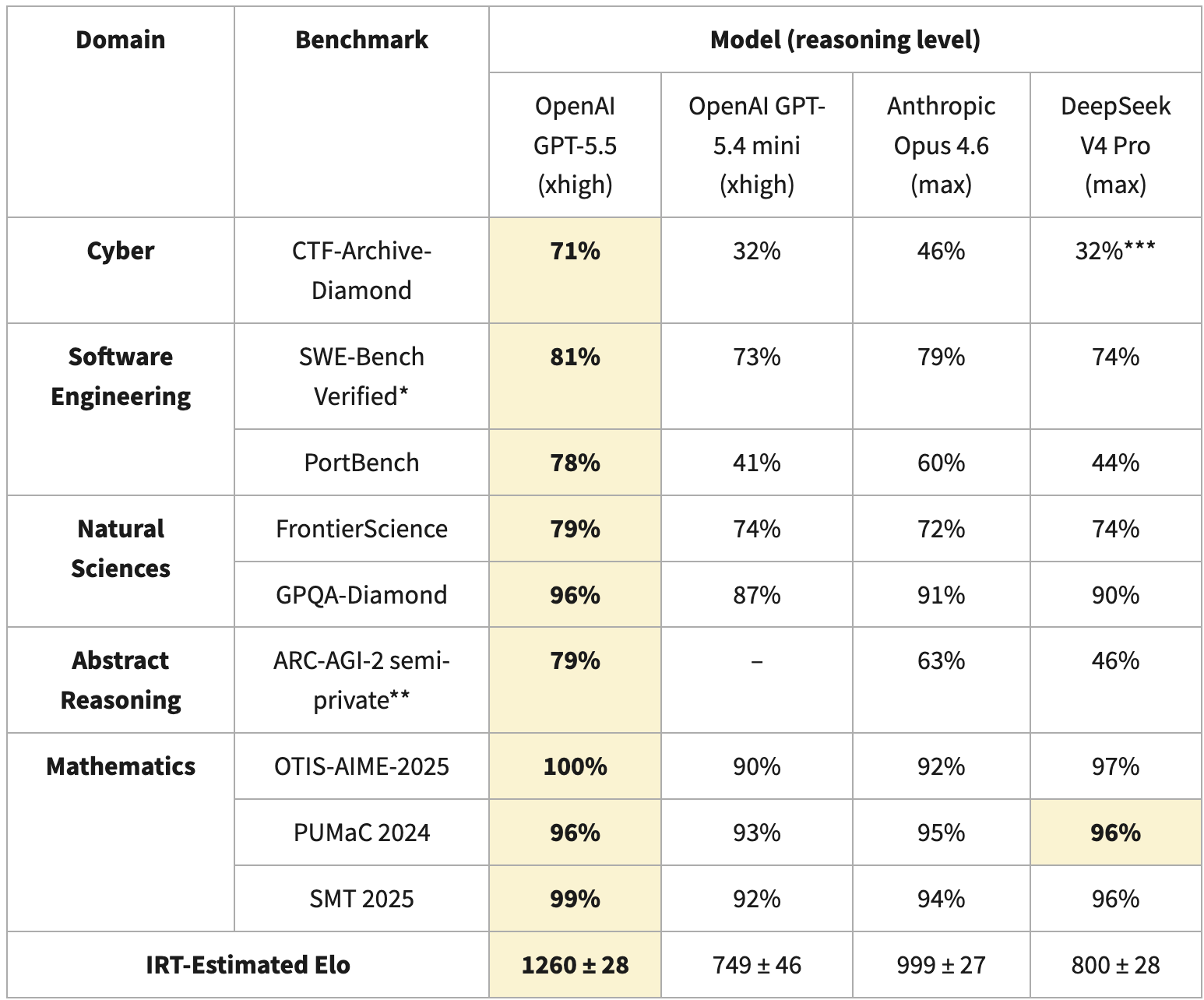
巨大的 Elo 差距部分归因于 DeepSeek V4 在 CTF-Archive-Diamond(仅使用了基准测试的一部分,并通过 IRT 对 V4 进行外推)中的低分,以及 PortBench(一个 CAISI 私有基准测试)和 ARC-AGI-2(采用不同于公共排行榜的评分方法)中的表现。这些基准测试之间的差异对整体 Elo 产生了巨大影响,可能会加剧模型能力的差距。
当使用 Epoch AI 的 ECI,它同样基于一组不同的基准测试使用 IRT 时,我们看到差距大致保持在 R1 以来的 3 到 7 个月之间:
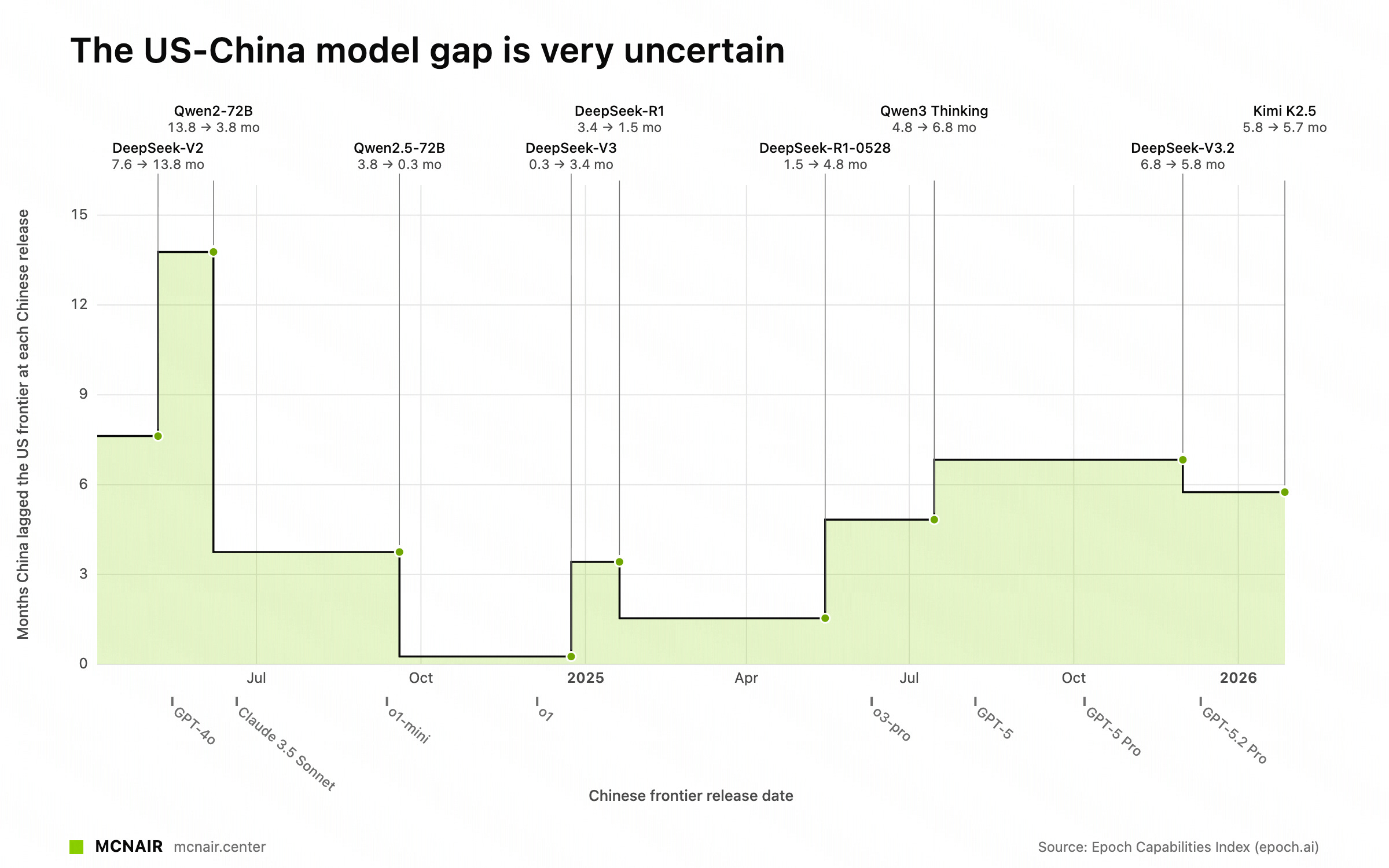
ECI 中的开源 <> 闭源差距(来源:https://mcnair.center/china/)
然而,CAISI 和 ECI 的分析并不完整,因为它们都使用标准化(且简单)的设置来比较模型的能力。更具体地说:编码任务的评估是通过访问 bash 和一个带有固定标记预算的 for 循环来进行的,而不是像 Claude Code 或 OpenCode 这样的工具,这些工具正是模型训练所使用的!这些设置导致基准测试声称目前无法将应用程序移植到另一种语言,而 Bun 已经从 Zig 移植到了 Rust,共进行了 100 万行代码的更改1。
因此,我们认为,要对开源和闭源模型进行前沿对比,也需要更好地激发所有模型的能力,这意味着需要使用首选的工具包以及针对模型特定的提示方式。
本节主要由 Florian 撰写。Interconnects 内部的一个有趣动态是,Florian 更相信开源前沿模型在真实性能上接近闭源模型。Nathan 虽然也认为基准测试不完美,但他认为闭源模型领先更多。我们将继续在未来的文章中深入探讨这一点。
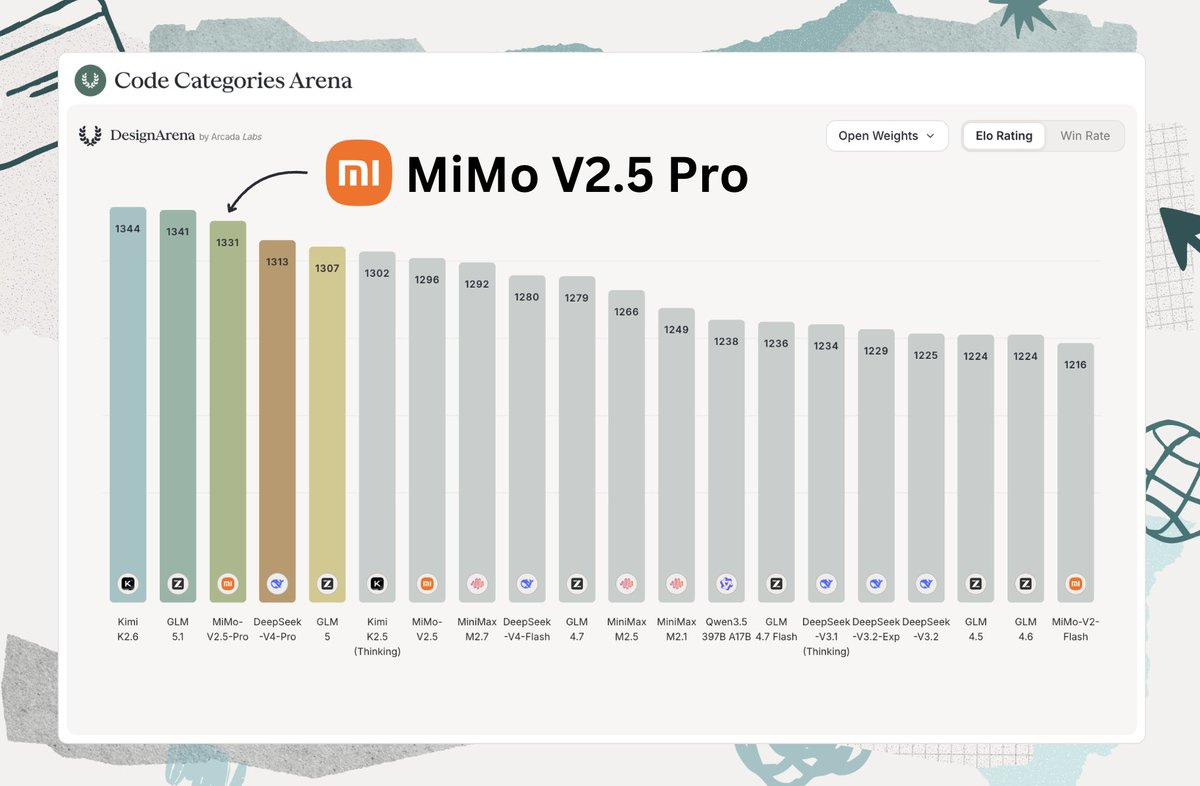
- [MiMo-V2.5-Pro](https://huggingface.co/XiaomiMiMo/MiMo-V2.5-Pro) by XiaomiMiMo: 热心的 Artifacts 读者都知道,小米一直在开发开源模型;其首次亮相是在 一年前。其发布的进展令人印象深刻,2.5 Pro(采用 Apache 2.0 协议发布)在基准测试和 实际应用 中的表现与 Kimi K2.6 和 GLM-5.1 等旗舰模型不相上下。
- [gemma-4-26B-A4B-it](https://huggingface.co/google/gemma-4-26B-A4B-it) by google(完整连接体文章请见 此处):Gemma 系列的长期期待更新,包含多种尺寸:4B、9B 和 31B 密集模型,以及一个 26B-A4B 的 MoE 模型。更重要的是,Gemma 4 使用 Apache 2.0 许可证,消除了对自定义许可证进行解释时的不确定性与法律挑战。
- [Kimi-K2.6](https://huggingface.co/moonshotai/Kimi-K2.6) by moonshotai:Kimi 系列的更新,整体性能更强,再次成为当前最佳开源模型之一。他们还专注于长距离性能,展示了开源模型能够运行数小时以完成任务或优化性能的能力。鉴于大家都致力于构建类似 autoresearch 的系统,看到开源模型迎头赶上是非常重要的。
- [Laguna-XS.2](https://huggingface.co/poolside/Laguna-XS.2) by poolside:Poolside AI 发布了其首个面向编程的公开模型,包括开放权重的 XS.2。其规模(33B-A3B)使其在本地使用上更具吸引力,性能与其他同尺寸模型相当。配套的 博客文章 值得阅读,此外还有关于编码评估中奖励黑客行为的深入分析 文章。
- [DeepSeek-V4-Flash](https://huggingface.co/deepseek-ai/DeepSeek-V4-Flash) by deepseek-ai:DeepSeek 最终发布了其 V3 系列的后续版本,该系列已持续更新数月。它有两个尺寸:Pro,为 1.6T-A49B 的 MoE;以及 Flash,为 284B-13B 的模型。根据他人的经验,后者似乎是真正的亮点,因为其性能相对较强,而 Pro 相对于其规模似乎表现不佳。技术报告 详细介绍了包括用于实现更优且更低成本长上下文性能的架构变化。
- [Qwen3.6-35B-A3B](https://huggingface.co/Qwen/Qwen3.6-35B-A3B) by Qwen:针对 Qwen 3.5 系列中最广泛使用的尺寸进行更新。
- [LFM2.5-350M](https://huggingface.co/LiquidAI/LFM2.5-350M) by LiquidAI:拥有 28T 个 token 和 350M 个参数,这个模型可能是目前训练最充分的模型之一。
- [Trinity-Large-Thinking](https://huggingface.co/arcee-ai/Trinity-Large-Thinking) by arcee-ai:Trinity 的推理版本,是目前最好的西方开源模型之一。它在 OpenRouter 上排名靠前,可以驱动如 OpenClaw 这样的代理应用。
- [GLM-5.1](https://huggingface.co/zai-org/GLM-5.1) by zai-org:GLM-5 的更新,整体得分有所提升。此次更新的重点在于长距离任务。