深度拆解 Hermes Agent 的记忆系统:它如何修正 OpenClaw 的误区
- Hermes Agent采用四层记忆系统以优化提示词缓存。
- 核心逻辑是保持提示词稳定,将繁杂信息交给工具处理。
- Hermes与OpenClaw的主要区别在于对缓存效率的关注。
结构提纲
AI 替你读一遍后整理出的核心层级。
- §引言
介绍Hermes Agent及其开源特性,概述其记忆系统的独特之处。
详细描述Hermes如何构建系统提示词,并解释其优化策略。
介绍`MEMORY.md`和`USER.md`文件的作用及限制,强调其精简性。
说明如何使用SQLite数据库存储历史会话并进行搜索。
解释在长对话压缩前如何保存重要信息。
介绍Hermes如何存储和管理技能。
描述Honcho层如何实现跨设备、跨平台的记忆连续性。
对比Hermes和OpenClaw的记忆系统,突出Hermes的高效设计。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- Hermes Agent的记忆系统
金句 / Highlights
值得收藏与分享的关键句。
深度拆解 Hermes Agent 的记忆系统:它如何修正 OpenClaw 的误区
作者:Manthan Gupta
原文:I Read Hermes Agent's Memory System, and It Fixes What OpenClaw Got Wrong
如果你读过我之前关于 ChatGPT、Claude 以及 Clawdbot 记忆系统的文章,你就会知道我一直在钻研同一个问题:这些 AI 智能体(AI Agent)到底是怎么记事的?
Hermes Agent 对我来说格外有趣,因为这次我不需要只靠观察它的行为来搞“逆向工程”。Hermes 是开源的,它的代码库和文档都是公开的。所以,我没有通过提示词(Prompt)去盲测这个黑盒,而是直接翻看了它的代码路径——从它如何构建提示词状态、持久化会话,到如何清理记忆和查询历史对话。
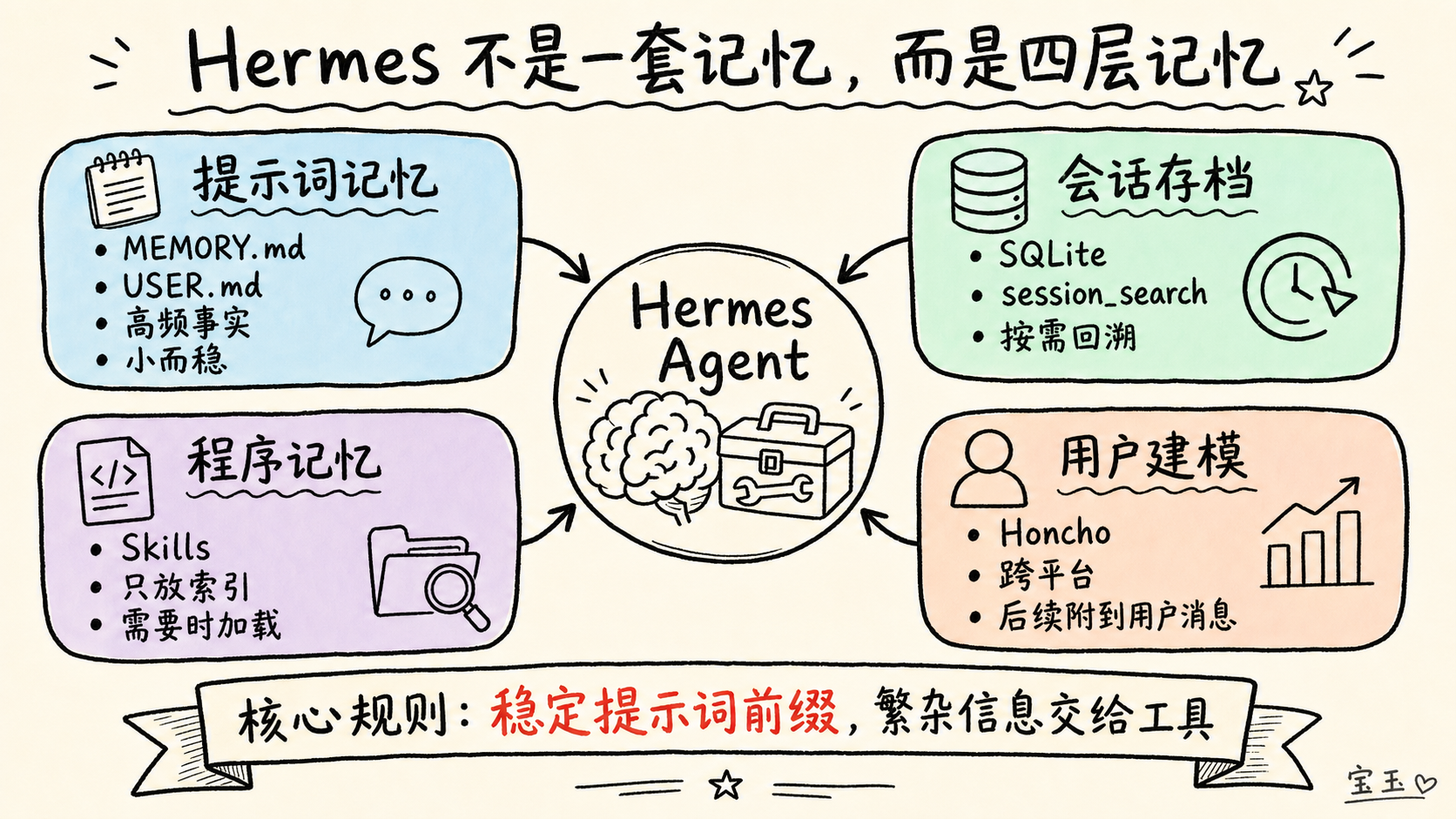
**简而言之:Hermes 拥有的不是一套记忆系统,而是四套。**
1. 存储在 `MEMORY.md` 和 `USER.md` 中、经过高度浓缩的**提示词记忆**。 2. 通过 `session_search` 调用的 **SQLite 历史会话存档**(可搜索)。 3. 像**程序记忆**(Procedural Memory)一样运作的**智能体技能管理**。 4. 可选的 **Honcho** 层,用于更深层的**用户建模**(User Modeling)。
把这些设计联系在一起的核心逻辑非常简单:**保持提示词稳定以便利用缓存(Caching),其他一切繁杂信息都交给工具。**
让我们深入聊聊。
- * *
Hermes 的上下文结构
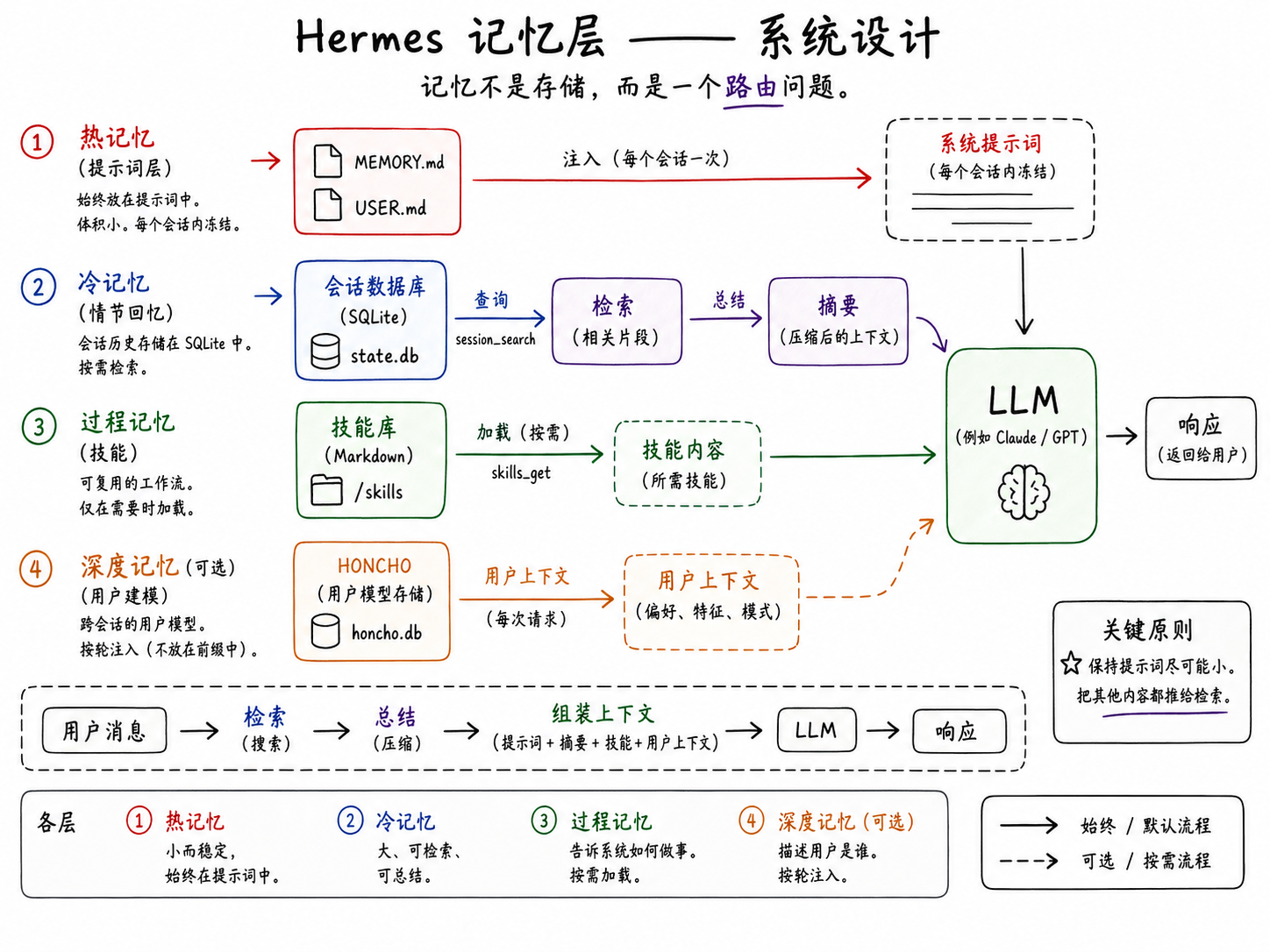
在理解记忆之前,我们先看看 Hermes 到底给模型发送了什么。
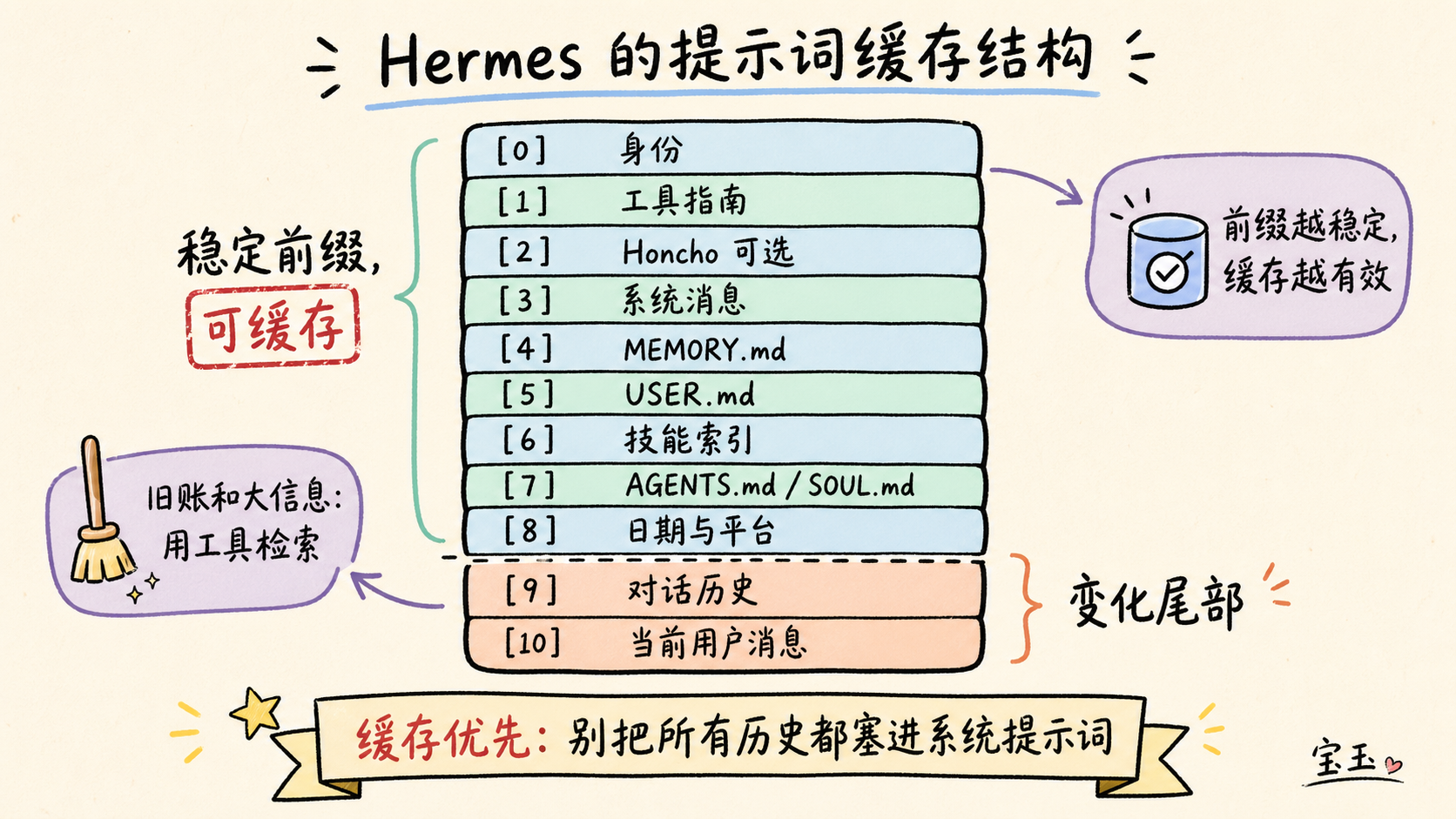
系统提示词(System Prompt)大致是按以下顺序组装的:
[0] 默认智能体身份
[1] 工具使用行为指南
[2] Honcho 集成模块(可选)
[3] 可选系统消息
[4] 固化的 MEMORY.md 快照
[5] 固化的 USER.md 快照
[6] 技能索引
[7] 上下文文件(AGENTS.md, SOUL.md 等规则文件)
[8] 日期/时间 + 平台信息
[9] 对话历史
[10] 当前用户消息这非常关键,因为 Hermes 正在针对大模型供应商的**提示词缓存(Prompt Caching)**机制进行优化。代码显示,提示词构建器的目标非常明确:**让稳定的前缀部分尽可能长时间地保持不变。**
这一个决定就解释了 Hermes 大部分的记忆架构。
如果某条信息每一轮对话都要用到,Hermes 会尽量把它缩得很小并注入进去;如果信息量很大、属于历史旧账或者偶尔才有用,Hermes 就会把它踢出提示词,改用“按需检索”的方式。
第一层:固化的提示词记忆
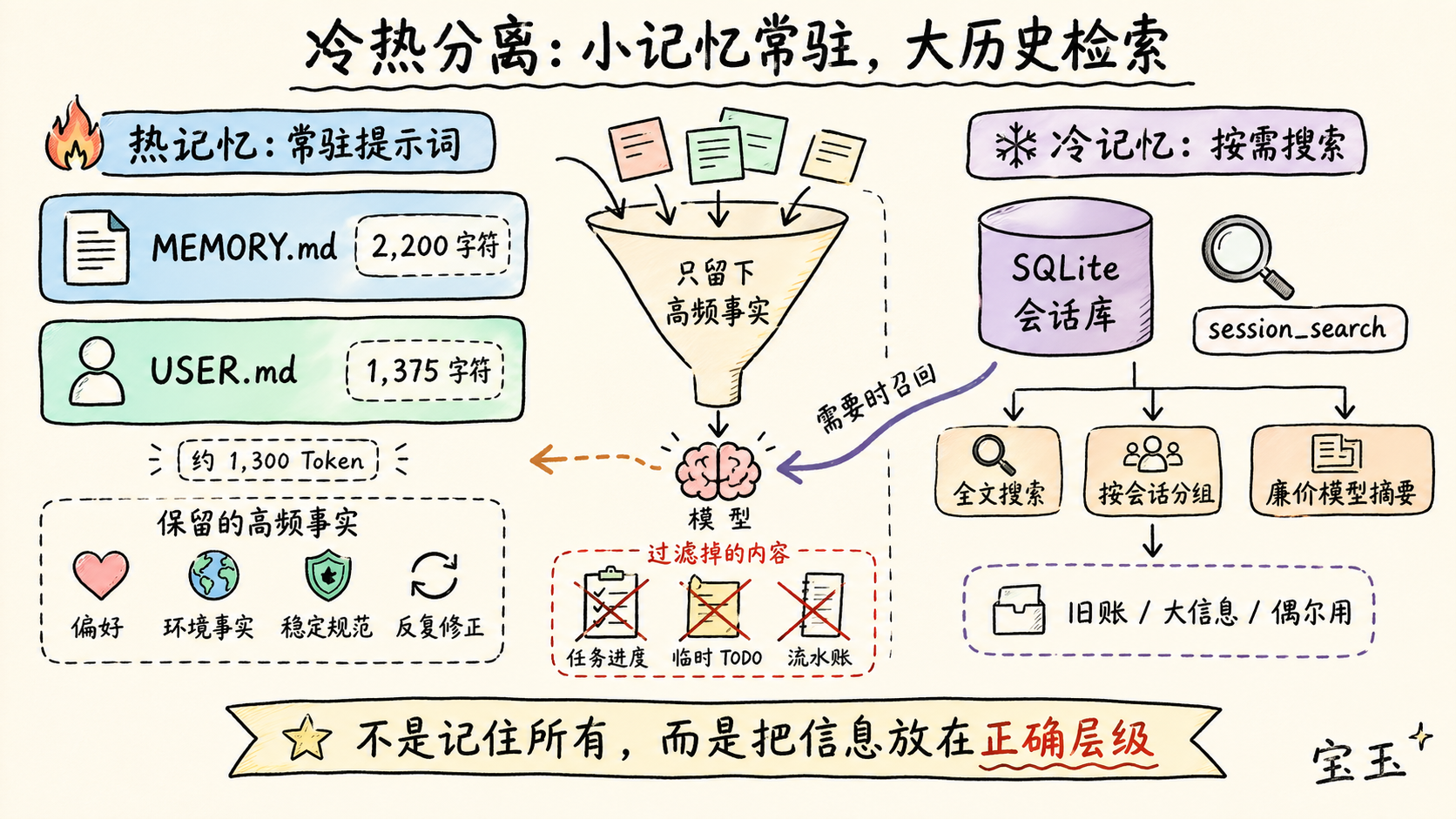
其内置的记忆系统小得令人惊讶。
Hermes 将持久记忆存储在 `~/.hermes/memories/` 下的两个文件中:
| 文件 | 用途 | 限制 | | --- | --- | --- | | `MEMORY.md` | 智能体笔记:环境、规范、工具怪癖、教训 | 2,200 字符 | | `USER.md` | 用户画像:偏好、沟通风格、身份信息 | 1,375 字符 |
这容量真不大。加起来大约只有 1,300 个 **Token(模型理解文本的最小单位)**。
**而这正是刻意为之。**
在会话开始时,Hermes 加载这两个文件,把它们渲染进提示词区块,然后**在整个会话期间固化这个快照**。会话中途写入的记忆会立即存入硬盘,但不会改变已经生成的系统提示词。这些改动只有在开启新会话,或者触发了“压缩(Compression)”导致的提示词重建时才会生效。
渲染后的格式如下:
══════════════════════════════════════════════
MEMORY (你的个人笔记) [67% — 1,474/2,200 字符]
══════════════════════════════════════════════
用户的项目是一个位于 ~/code/myapi 的 Rust Web 服务,使用 Axum + SQLx
§
这台机器运行 Ubuntu 22.04,安装了 Docker 和 Podman
§
用户喜欢简洁的回复,讨厌冗长的解释这里有几个我非常欣赏的细节设计:
1. **使用字符限制而非 Token 限制**:这让记忆逻辑与模型无关。Hermes 不需要调用特定模型的计算工具就能判断记忆是否存满。 2. **简单的分隔符文件格式**:条目之间用 `§` 分隔。没有复杂的向量数据库(Vector DB),没有自定义二进制存储,就是纯文本。 3. **刻意保持极小的系统提示词空间**:这是整个设计的重中之重。Hermes 不想把所有历史都塞进提示词,它只想要最有价值的事实。 4. **记忆是“精选状态”,而不是“日记”**:这是 Hermes 与 OpenClaw 最大的区别。
OpenClaw 的日志更像是“流水账”。而 Hermes 则反其道而行。它的工具架构和测试逻辑强调:
- 保存用户偏好。
- 保存环境事实。
- 保存反复出现的错误修正。
- 保存稳定的规范。
- **不保存**任务进度。
- **不保存**会话结果。
- **不保存**临时的待办事项(TODO)。
**真相是:Hermes 希望 `MEMORY.md` 和 `USER.md` 保持精简、高频且对缓存友好。**
`memory` 工具
Hermes 通过一个拥有三种操作的 `memory` 工具来管理这些文件:`add`(添加)、`replace`(替换)、`remove`(移除)。
一个好用的细节是:`replace` 和 `remove` 使用**子字符串匹配**。你不需要记住条目的内部 ID,只需要传入现有条目中一段唯一的文字即可。
此外,系统会拒绝完全重复的内容,并拦截危险信息。源代码会扫描记忆条目,防止**提示词注入(Prompt Injection,即通过输入恶意指令误导 AI)**、凭证泄露或隐藏的 Unicode 字符。
- * *
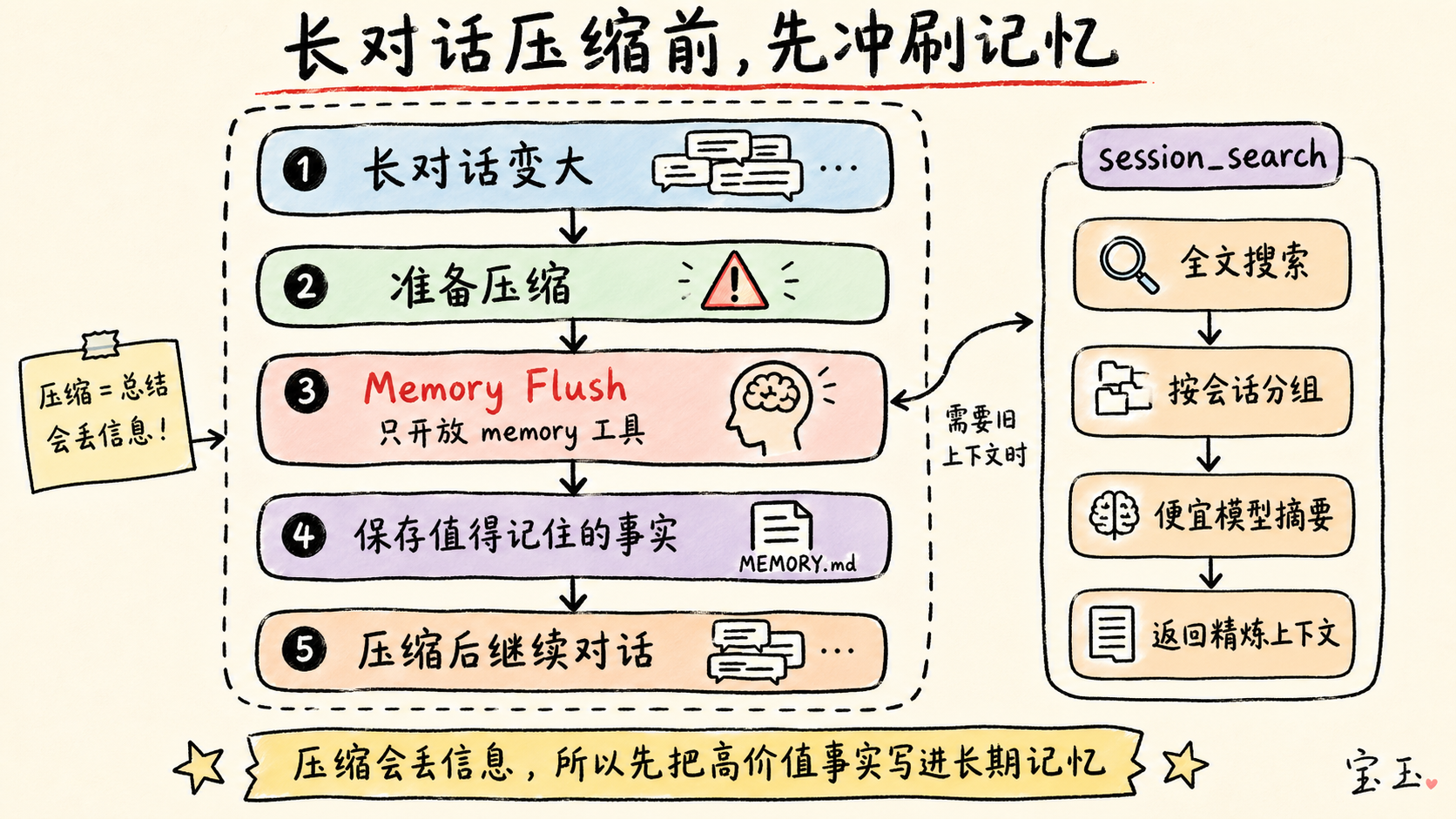
第二层:用于情景回溯的 `session_search`
如果说 `MEMORY.md` 是 Hermes 的“短期热记忆”,那么 `session_search` 就是它的“长尾回溯系统”。
所有过去的会话都存储在 SQLite 数据库中,拥有完整的索引和搜索功能。当模型需要想起以前聊过的内容时,它不去翻 `MEMORY.md`,而是搜索这个会话数据库。
其工作流程是:
1. 在过去的消息中进行全文搜索。 2. 按会话分组结果。 3. 加载匹配度最高的会话。 4. **使用一个便宜的辅助模型对这些会话进行摘要总结。** 5. 将精炼后的回顾内容返回给主模型。
这是一种非常务实的设计。它比盲目地把长篇累牍的历史塞进每一个提示词要便宜且高效得多。
- * *
第三层:压缩与记忆冲刷(Memory Flush)
Hermes 另一个聪明之处在于它处理长对话“压缩”的方式。
当会话变得太长,Hermes 会压缩对话中间的部分以节省空间。但摘要是有损的,重要事实可能会丢失。
**于是,Hermes 会先进行一次“记忆冲刷”。**
在压缩之前,它会发送一条指令告诉模型:
“会话即将压缩,请保存任何值得记住的东西。优先保存用户偏好、修正建议和重复模式,而非具体的任务细节。”
然后它运行一次额外的模型调用,只开启 `memory` 工具。如果模型觉得有什么东西该留下来,就会在对话被“洗掉”之前把它写入 `MEMORY.md`。
- * *
第四层:作为程序记忆的技能(Skills)
Hermes 不仅能记住事实,还能记住**技能**。
技能(Skills)存储在 `~/.hermes/skills/` 下。当 Hermes 发现了一个复杂的流程、修复了一个棘手的问题或学会了更好的方法时,它可以将其保存为“技能”。
大多数记忆系统只关注“语义回溯”(名字、偏好、事实),但智能体还需要记住**如何做事**。
为了效率,Hermes 不会把所有技能都塞进提示词,而是只放一个**技能索引**,只有在需要时才加载具体的技能内容。
- * *
第五层:用于深层建模的 Honcho
最后是可选的 Honcho 层。如果说本地记忆是 Hermes 的笔记本,Honcho 就是它尝试构建的复杂用户模型。它能实现跨设备、跨平台的记忆连续性。
最精妙的是它如何在不破坏提示词缓存的前提下实现集成:
- 在会话的第一轮,Honcho 的上下文会被织入系统提示词。
- 在之后的对话中,为了保持提示词稳定,Honcho 的回溯内容会附加在**当前用户的提问**后面,而不是修改系统提示词。
**这确保了缓存依然有效,同时 AI 依然能读到最新的背景信息。**
- * *
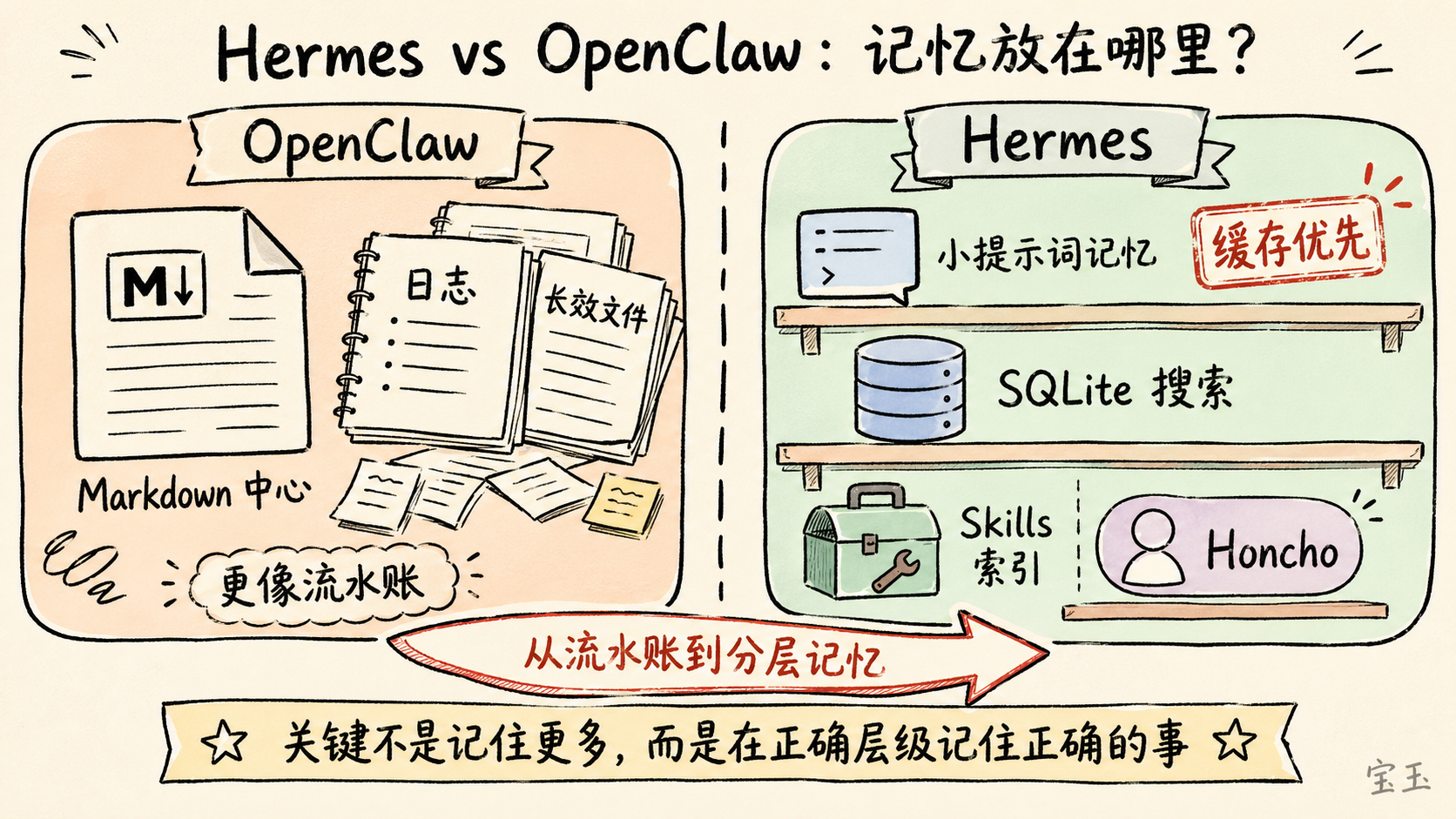
Hermes 与 OpenClaw 的区别
- **OpenClaw**:记忆更接近“以 Markdown 为中心的存储”,日志和长效文件是主要事实来源。
- **Hermes**:提示词记忆被严格限制,历史记录存在 SQLite 里,只有需要时才搜索。
**Hermes 更加关注缓存效率。** 它认为:不是所有东西都配住在“系统提示词”这个黄金地段。
- * *
总结:Hermes 做对了什么?
1. **冷热分离**:小规模提示词记忆负责常驻信息,搜索负责偶尔用到的信息。 2. **缓存优先**:它意识到频繁改动提示词会导致延迟增加和成本上升。 3. **记忆的多样性**:它承认记忆是分层的——包括个人画像、情景回溯、操作技能和深层建模。
Hermes 的核心设计原则最令我折服:**记忆应该让智能体变得更好用,而不是通过摧毁提示词的稳定性来换取博闻强识。**
真正的诀窍不是记住更多,而是在正确的层级、以正确的成本,记住正确的事情。
问问这篇内容
回答仅基于本篇材料Skill 包
领域模板,一键产出结构化笔记论文精读包
把一篇论文 / 技术博客精读成结构化笔记:问题、方法、实验、批判、延伸阅读。
- · TL;DR(1 段)
- · 研究问题与动机
- · 方法概览
投融资雷达包
把一条融资 / 创投新闻整理成投资人视角的雷达卡:交易要点、判断、竞争格局、风险、尽调清单。
- · 交易要点(公司 / 轮次 / 金额 / 投资人 / 估值,材料未明示则写 “未披露”)
- · 投资 thesis(这家公司为什么值得关注)
- · 竞争格局与替代方案