Why Your Agents Can’t Read Enterprise Documents — and How to Fix It

- 传统OCR和纯文本模型无法有效处理含表格、图表的企业PDF文档
- 需融合文档视觉布局与语言语义以提升智能体理解能力
- Databricks正开发支持结构化文档理解的AI代理基础设施
Why Your Agents Can’t Read Enterprise Documents — and How to Fix It | Databricks Blog
[](http://www.databricks.com/)
[](http://www.databricks.com/)
- Why Databricks
- * Discover
- Customers
- Partners
- Product
- * Databricks Platform
- Integrations and Data
- Pricing
- Open Source
- Solutions
- * Databricks for Industries
- Cross Industry Solutions
- Migration & Deployment
- Solution Accelerators
- Resources
- * Learning
- Events
- Blog and Podcasts
- Get Help
- Dive Deep
- About
- * Company
- Careers
- Press
- Security and Trust
- DATA + AI SUMMIT 
- * *
Contents in this story
Improving agent quality on real-world, enterprise documents
- Improving agent quality on real-world, enterprise documents
- Unlocking document intelligence at enterprise scale
- From fragmented pipelines to a unified workflow
- Your agents are only as good as your document processing layer
Why Your Agents Can’t Read Enterprise Documents — and How to Fix It
Introducing Document Intelligence on Databricks

Published: April 16, 2026
AI6 min read
by Archika Dogra, Sergei Tsarev and Erich Elsen
Share this post
- [](https://www.linkedin.com/shareArticle?mini=true&url=https://www.databricks.com/blog/why-frontier-agents-cant-read-documents-and-how-were-fixing-it&summary=&source=)
- [](https://twitter.com/intent/tweet?text=https://www.databricks.com/blog/why-frontier-agents-cant-read-documents-and-how-were-fixing-it)
- [](https://www.facebook.com/sharer/sharer.php?u=https://www.databricks.com/blog/why-frontier-agents-cant-read-documents-and-how-were-fixing-it)
Keep up with us
Subscribe
#### Summary
- Frontier agents still score below 50% on real enterprise document tasks. The bottleneck isn't reasoning, it's reading.
- Document processing is the accuracy ceiling for every agentic workflow.
- We’re announcing Document Intelligence to close this gap: delivering research-backed accuracy, enterprise scale, and end-to-end simplicity.
The most important business intelligence isn't just stored in warehouses — it lives in the millions of documents that power core enterprise workflows every day: contracts, claims, invoices and more. For a decade, Intelligent Document Processing (IDP) was treated as a narrow, back-office automation problem. In the agentic era, the stakes are fundamentally different: IDP is the critical foundation that determines whether your agents make decisions you'd actually trust.
Take insurance claims processing. On paper, it's an ideal agentic workflow: ingest a claim, extract details, flag anomalies, and route it. Today's frontier agents handle the reasoning easily. Where they break down is reading the documents: scanned PDFs with inconsistent layouts, nested tables, handwritten notes, and format variation across every vendor. A "$10,000" gets hallucinated as "$3,000," the agent makes a misinformed decision, and the wrong amount gets silently paid out.
We're seeing this pattern across the board: agents reason well over clean text but fall apart when faced with real enterprise documents. A few months ago, Databricks AI Research released OfficeQA, a benchmark based on real-world enterprise document workflows. We found that even highly capable frontier agents scored below 50% accuracy on document reasoning tasks. The bottleneck wasn't reasoning — it was reading.
**That's why we’re excited to announce Document Intelligence**, built on three core pillars: research-backed accuracy, enterprise scale, and end-to-end simplicity.
At Intercontinental Exchange, we process millions of complex, highly variable financial documents every month. Document Intelligence helps us turn that complexity into structured market intelligence, enabling us to move faster, deliver greater value to our clients, and unlock agentic workflows that accelerate analysis and decision-making at scale."— Anand Pradhan, CTO and Head of AI, Mortgage Data at Intercontinental Exchange (NYSE)
Improving agent quality on real-world, enterprise documents
Document processing is the accuracy ceiling for every agent. To get this right, the Databricks AI Research team set out to build specialized systems designed for the messy reality of what enterprises actually deal with: inconsistent layouts, nested tables, images, and handwriting.
This research powers a set of chainable AI Functions that break document processing into composable steps: `ai_parse_document` (now Generally Available) converts raw scans into layout-enriched structured text, while downstream, `ai_classify` routes documents correctly, and `ai_extract` pulls the key structured insights that matter most. Together, they form a document intelligence pipeline you can assemble with ease: parse once, then classify, extract, and re-extract without reprocessing the original document.
So does better document processing actually make agents more accurate? When we benchmarked real-world treasury bond documents through OfficeQA, pre-processing with `ai_parse_document` delivered a 16% average performance gain across every agent framework we tested. The agent's reasoning harness didn't change at all, but the document data layer beneath it did.
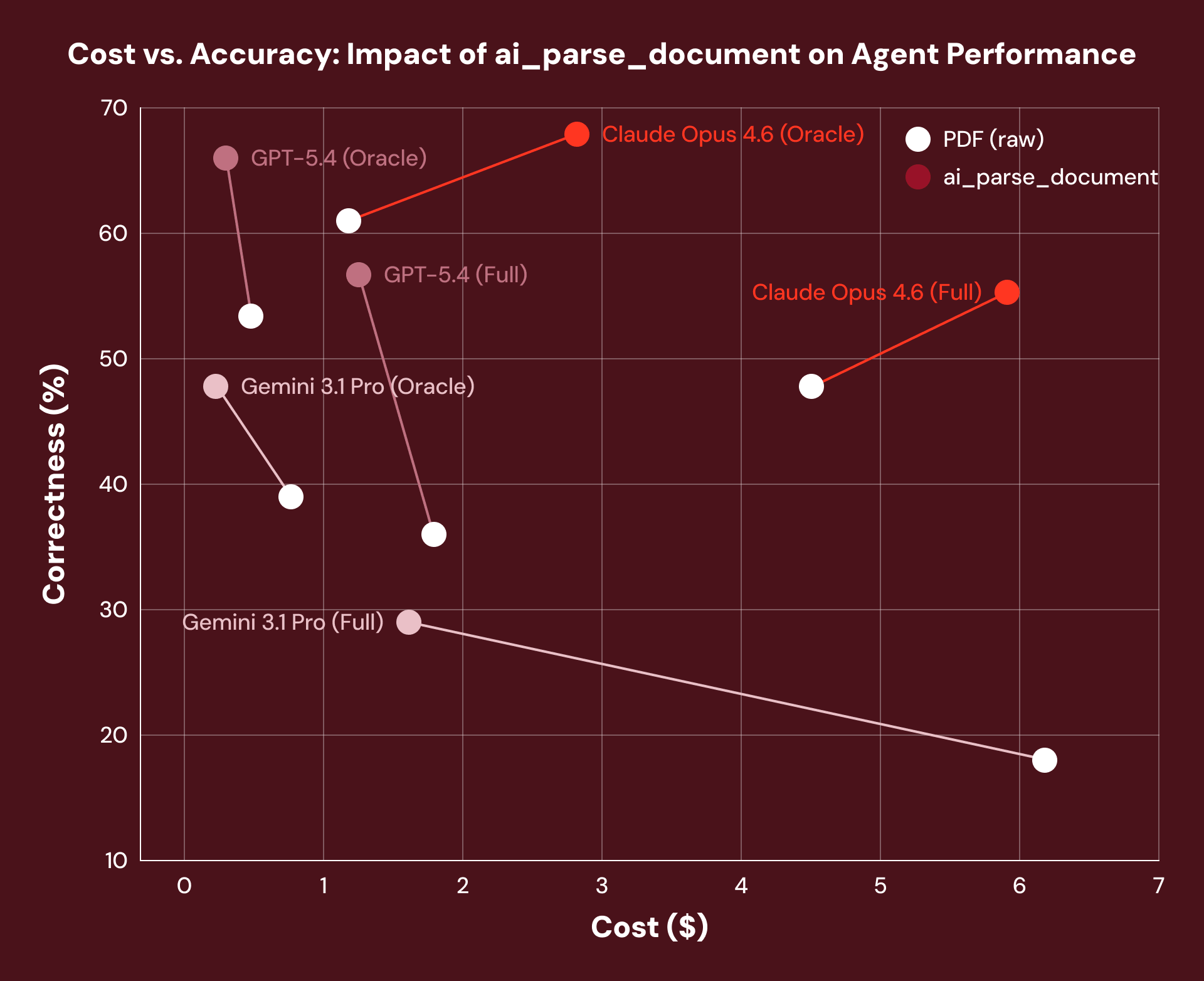
_Note: We observed an increase in Claude Opus 4.6 costs due to the model’s tendency to retrieve more tokens when provided the structured layout text of a document._
That’s exactly why we build Document Intelligence as the foundation of your agentic workflows: the quality and cost gains of document processing compound through everything built on top of it.
With Document Intelligence, we’re laying the groundwork for an intelligent document processing pipeline that unlocks key structured insights from millions of unstructured technical PDFs each year, sourced from thousands of organizations and spanning highly inconsistent formats.— Graham Lammers, Executive Director of Data Intelligence, Accuris
Unlocking document intelligence at enterprise scale
Even when quality is solved, the graveyard of enterprise IDP is full of projects that nailed the pilot but couldn't survive the economics of production. This is thanks to costs that balloon to six figures and batch jobs that take days instead of hours.
We designed Document Intelligence for production-scale economics from the start, not as an afterthought. Because AI Functions like `ai_parse_document` are research-specialized, they achieve state-of-the-art accuracy without the computational overhead of general-purpose models.
Across various solutions, we benchmarked accuracy and cost on structured document extraction tasks identifying key entities from enterprise invoices, contracts, medical notes, and financial filings. Document Intelligence consistently achieved the highest accuracy at 5–7x lower cost than comparable pipelines.

_Note: Offerings marked (parse + extract) use a two-step pipeline architecture — parse once into a reusable silver layer, then extract and re-extract without re-parsing. VLM-based offerings reprocess the full document on every extraction call._
Importantly, to support this scale, every AI Function runs on serverless batch infrastructure built for high-volume workloads: the same one-line SQL call that processes 100 invoices processes 100,000 without rearchitecting your pipeline.
With Document Intelligence, we achieved the same high-quality entity extraction at nearly 90% lower cost within weeks. That price-performance breakthrough now powers our production pipelines, enabling us to expand into new disease areas faster, process hundreds of millions of clinical notes efficiently, and deliver insights to our customers at scale. — Jerry Dennany, CTO Loopback Analytics
Importantly, for at-scale processing, every AI Function runs on serverless batch infrastructure built for high-volume workloads: the same one-line SQL call that processes 100 invoices processes 100,000 without rearchitecting your pipeline.
REPORT
The agentic AI playbook for the enterprise

From fragmented pipelines to a unified workflow
For most enterprises today, document intelligence isn't a platform capability. It's a collection of one-off pipelines. For just a single use case, a team stitches together an OCR service, bolts on a distinct extraction API, and wires in a classification model from yet another provider. Before long, they're managing three to five disconnected APIs held together by fragile custom glue code — a pipeline that's brittle, expensive to maintain, and nearly impossible to debug when it breaks at 3 AM. And when another team needs to process a different document type, there's nothing reusable to build on. They start from scratch.
This is the cycle that keeps document intelligence trapped as a series of one-off projects instead of an enterprise-wide capability. Document Intelligence breaks that cycle. Instead of stitching together disconnected services, every step runs natively inside your existing Databricks orchestration and governance layer:
- **Ingest**documents (e.g., from SharePoint) using Lakeflow Connect.
- **Orchestrate** the full pipeline using Lakeflow Jobs or Spark Declarative Pipelines, with built-in error handling, observability, and automatic handling of new documents.
- **Govern** the end-to-end lineage, security, and access controls of your pipelines and data—from the raw document to the structured table output—with Unity Catalog.
- **Build** agents on the new, enriched document data layer using the Agent Bricks platform.
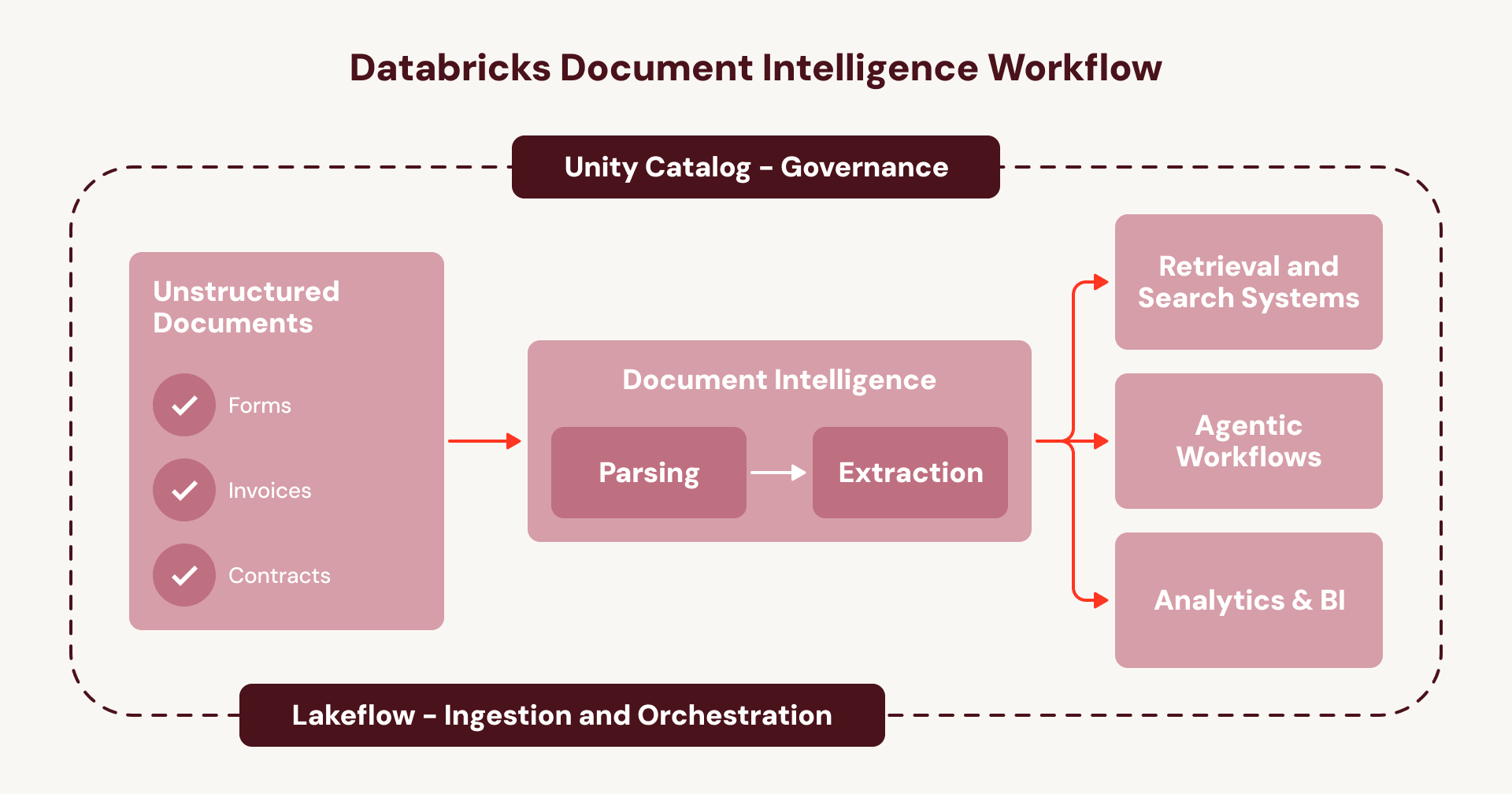
For enterprises, this means document intelligence runs on one unified and governed workflow instead of a web of opaque, fragmented services- a repeatable playbook to scale agentic use cases across all of your documents.
With Databricks, we’ve gone from manual, fragmented processes to automated, scalable intelligence. What used to take weeks, we now do in days - unlocking insights our clients can’t get anywhere else. — Tony Qui, EY-Parthenon Global Innovation Leader, Strategy and Transactions
Your agents are only as good as your document processing layer
The promise of enterprise agents rests on a question most organizations haven't yet answered: can your agents actually understand the millions of documents in your business?
That’s why we’re excited to announce Document Intelligence to close that gap: accurate enough for business-critical workflows, governed end to end so your compliance team isn't chasing data across vendors, and built to scale from your first pilot to production without changing a line of code.
Your documents are the richest source of intelligence in your enterprise. It's time your agents could read them.
- Read our how-to blog on building with Document Intelligence and Lakeflow.
- Sign up for the Databricks Trial.
Keep up with us
Subscribe
Contents in this story
Improving agent quality on real-world, enterprise documents
- Improving agent quality on real-world, enterprise documents
- Unlocking document intelligence at enterprise scale
- From fragmented pipelines to a unified workflow
- Your agents are only as good as your document processing layer
Recommended for you
Product
April 16, 2026/6 min read
#### Building with Databricks Document Intelligence and Lakeflow

Product
April 14, 2026/6 min read
#### Agent Bricks: The Governed Enterprise Agent Platform
Product
April 15, 2026/5 min read
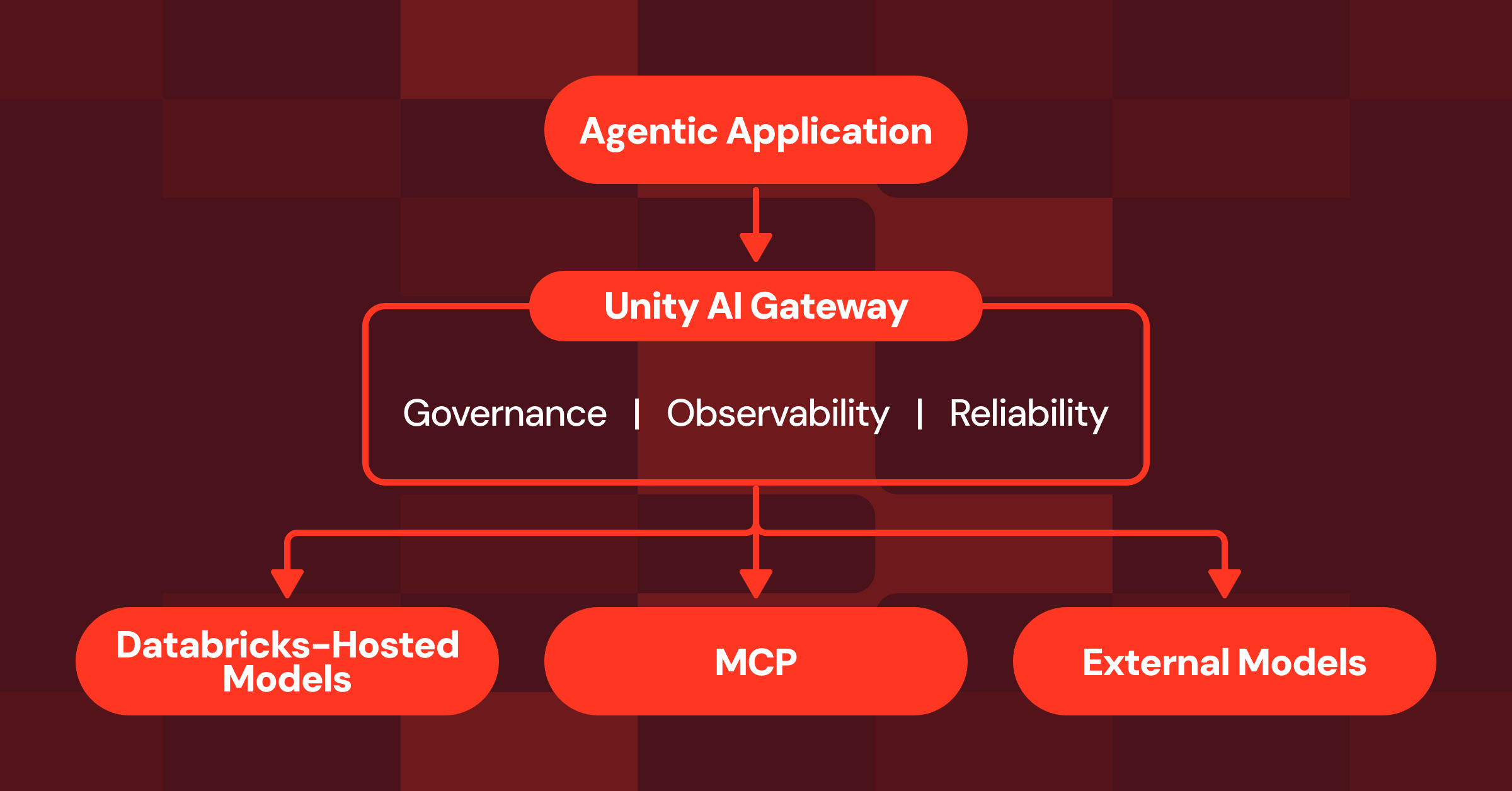
#### Expanding Agent Governance with Unity AI Gateway
Share this post
- [](https://www.linkedin.com/shareArticle?mini=true&url=https://www.databricks.com/blog/why-frontier-agents-cant-read-documents-and-how-were-fixing-it&summary=&source=)
- [](https://twitter.com/intent/tweet?text=https://www.databricks.com/blog/why-frontier-agents-cant-read-documents-and-how-were-fixing-it)
- [](https://www.facebook.com/sharer/sharer.php?u=https://www.databricks.com/blog/why-frontier-agents-cant-read-documents-and-how-were-fixing-it)
Never miss a Databricks post
Subscribe to our blog and get the latest posts delivered to your inbox
Sign up
*
Work Email
*
Country:
By clicking “Subscribe” I understand that I will receive Databricks communications, and I agree to Databricks processing my personal data in accordance with its Privacy Policy.
Subscribe
What's next?
More from the Authors
- Introducing Databricks Vector Search Public Preview
- Announcing Mosaic AI Vector Search General Availability in Databricks
- Announcing Hybrid Search General Availability in Mosaic AI Vector Search

AI Research
December 9, 2025/12 min read
#### Introducing OfficeQA: A Benchmark for End-to-End Grounded Reasoning
AI Research
March 5, 2026/3 min read
#### Meet KARL: A Faster Agent for Enterprise Knowledge, powered by custom RL

Why Databricks
Discover
Customers
Partners
Why Databricks
Discover
Customers
Partners
Product
Databricks Platform
- Platform Overview
- Sharing
- Governance
- Artificial Intelligence
- Business Intelligence
- Database
- Data Management
- Data Warehousing
- Data Engineering
- Data Science
- Application Development
- Security
Pricing
Integrations and Data
Product
Databricks Platform
- Platform Overview
- Sharing
- Governance
- Artificial Intelligence
- Business Intelligence
- Database
- Data Management
- Data Warehousing
- Data Engineering
- Data Science
- Application Development
- Security
Pricing
Open Source
Integrations and Data
Solutions
Databricks For Industries
- Communications
- Financial Services
- Healthcare and Life Sciences
- Manufacturing
- Media and Entertainment
- Public Sector
- Retail
- View All
Cross Industry Solutions
Solutions
Databricks For Industries
- Communications
- Financial Services
- Healthcare and Life Sciences
- Manufacturing
- Media and Entertainment
- Public Sector
- Retail
- View All
Cross Industry Solutions
Data Migration
Professional Services
Solution Accelerators
Resources
Learning
Events
Blog and Podcasts
Resources
Documentation
Customer Support
Community
Learning
Events
Blog and Podcasts
About
Company
Careers
Press
About
Company
Careers
Press
Security and Trust

Databricks Inc.
160 Spear Street, 15th Floor
San Francisco, CA 94105
1-866-330-0121
- [](https://www.linkedin.com/company/databricks)
- [](https://www.facebook.com/pages/Databricks/560203607379694)
- [](https://twitter.com/databricks)
- [](https://www.databricks.com/feed)
- [](https://www.glassdoor.com/Overview/Working-at-Databricks-EI_IE954734.11,21.htm)
- [](https://www.youtube.com/@Databricks)
- [](https://www.linkedin.com/company/databricks)
- [](https://www.facebook.com/pages/Databricks/560203607379694)
- [](https://twitter.com/databricks)
- [](https://www.databricks.com/feed)
- [](https://www.glassdoor.com/Overview/Working-at-Databricks-EI_IE954734.11,21.htm)
- [](https://www.youtube.com/@Databricks)
© Databricks 2026. All rights reserved. Apache, Apache Spark, Spark, the Spark Logo, Apache Iceberg, Iceberg, and the Apache Iceberg logo are trademarks of the Apache Software Foundation.
- Privacy Notice
- |Terms of Use
- |Modern Slavery Statement
- |California Privacy
- |Your Privacy Choices
- !Image 30
We Care About Your Privacy
Databricks uses cookies and similar technologies to enhance site navigation, analyze site usage, personalize content and ads, and as further described in our Cookie Notice. To disable non-essential cookies, click “Reject All”. You can also manage your cookie settings by clicking “Manage Preferences.”
Manage Preferences
Reject All Accept All
Privacy Preference Center
Opt-Out Preference Signal Honored
Privacy Preference Center
- ### Your Privacy
- ### Strictly Necessary Cookies
- ### Performance Cookies
- ### Functional Cookies
- ### Targeting Cookies
- ### TOTHR
#### Your Privacy
When you visit any website, it may store or retrieve information on your browser, mostly in the form of cookies. This information might be about you, your preferences or your device and is mostly used to make the site work as you expect it to. The information does not usually directly identify you, but it can give you a more personalized web experience. Because we respect your right to privacy, you can choose not to allow some types of cookies. Click on the different category headings to find out more and change our default settings. However, blocking some types of cookies may impact your experience of the site and the services we are able to offer.
#### Opting out of sales, sharing, and targeted advertising
Depending on your location, you may have the right to opt out of the “sale” or “sharing” of your personal information or the processing of your personal information for purposes of online “targeted advertising.” You can opt out based on cookies and similar identifiers by disabling optional cookies here. To opt out based on other identifiers (such as your email address), submit a request in our Privacy Request Center.
#### Strictly Necessary Cookies
Always Active
These cookies are necessary for the website to function and cannot be switched off in our systems. They assist with essential site functionality such as setting your privacy preferences, logging in or filling in forms. You can set your browser to block or alert you about these cookies, but some parts of the site will no longer work.
#### Performance Cookies
- [x] Performance Cookies
These cookies allow us to count visits and traffic sources so we can measure and improve the performance of our site. They help us to know which pages are the most and least popular and see how visitors move around the site.
#### Functional Cookies
- [x] Functional Cookies
These cookies enable the website to provide enhanced functionality and personalization. They may be set by us or by third party providers whose services we have added to our pages. If you do not allow these cookies then some or all of these services may not function properly.
#### Targeting Cookies
- [x] Targeting Cookies
These cookies may be set through our site by our advertising partners. They may be used by those companies to build a profile of your interests and show you relevant advertisements on other sites. If you do not allow these cookies, you will experience less targeted advertising.
#### TOTHR
- [x] TOTHR
Cookie List
Consent Leg.Interest
- [x] checkbox label label
- [x] checkbox label label
- [x] checkbox label label
Clear
- - [x] checkbox label label
Apply Cancel
Confirm My Choices
Allow All
