[AINews] GPT 5.5 and OpenAI Codex Superapp
![[AINews] GPT 5.5 and OpenAI Codex Superapp](https://substackcdn.com/image/fetch/$s_!0uGP!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F2f9f5845-e1e6-497a-9bed-f6457169247c_2048x684.png)
A week after Opus 4.7, it was OpenAI’s turn to fire back with very similar Pareto frontier improvement charts for GPT 5.5 (as Noam Brown prefers —raw 1 dimensional intelligence measures are giving way to 2D intelligence per dollar charts). In the 4.7 vs 5.5 bakeoff, you have to read between the lines to see what was NOT mentioned (coding), but in terms of overall intelligence, AA crowns this the top independently validated model in the world, AND…
… intelligence per dollar (“_**GPT-5.5 (medium)** scores the same as **Claude Opus 4.7 (max)** on our Intelligence Index at **one quarter of the cost (~$1,200 vs $4,800)** - although Gemini 3.1 Pro Preview scores the same at a cost of **~$900**._”
There are some training hardware tidbits and positiveRSI vibes and coolalternativebenchmarks.
But if you just treated today as a mere point update model launch (some would prefer to call it 5.9), you’d be mistaken - it’s also bundlinga big Codex launch day:
With built in browser control and the other features in this mega-update, as well as folding in the now defunct Prism (RIP), OpenAI seems to have made the critical and retoractively obvious choice to turn Codex into the base of its superapp strategy.
AI News for 4/22/2026-4/23/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
**OpenAI’s GPT-5.5 launch: stronger agentic coding, broader computer use, and a push on token-efficiency**
- **GPT-5.5 is the day’s dominant release**: OpenAI launched GPT-5.5, positioned as “a new class of intelligence for real work,” with rollout across ChatGPT and Codex and API access delayed pending additional safeguards. OpenAI and community benchmark posts converged on a profile of **better long-horizon execution, stronger computer-use behavior, and materially improved token efficiency** rather than a pure across-the-board benchmark blowout. Reported numbers include **82.7% Terminal-Bench 2.0**, **58.6% SWE-Bench Pro**, **84.9% GDPval**, **78.7% OSWorld-Verified**, **81.8% CyberGym**, **84.4% BrowseComp**, and **51.7% FrontierMath Tier 1–3** via @reach_vb, with Artificial Analysis saying GPT-5.5 now leads or ties several headline evals and sits on a new cost/performance frontier despite higher per-token pricing @ArtificialAnlys, @scaling01. OpenAI also emphasized that in ChatGPT, stack-level inference gains made **GPT-5.5 Pro more practical** for demanding tasks @OpenAI.
- **Pricing, context, infra, and practical behavior**: API pricing was reported at **$5/$30 per 1M input/output tokens** for GPT-5.5 and **$30/$180** for Pro @scaling01, with Sam Altman noting a **1M context window** in API and lower token use per task than 5.4. Multiple early users described the model as more “human,” less formal, and better suited to persistent agent workflows than prior GPTs, especially inside Codex @MatthewBerman, @danshipper, @omarsar0. OpenAI claimed the model was **co-designed for NVIDIA GB200/300 systems** and that the model itself helped improve its own inference stack @scaling01, while @sama framed the company increasingly as an **AI inference company**. A recurrent theme from users: GPT-5.5 often feels like a **step-function upgrade in autonomy**, but can also be exploratory and require tighter instruction to stay on track @theo.
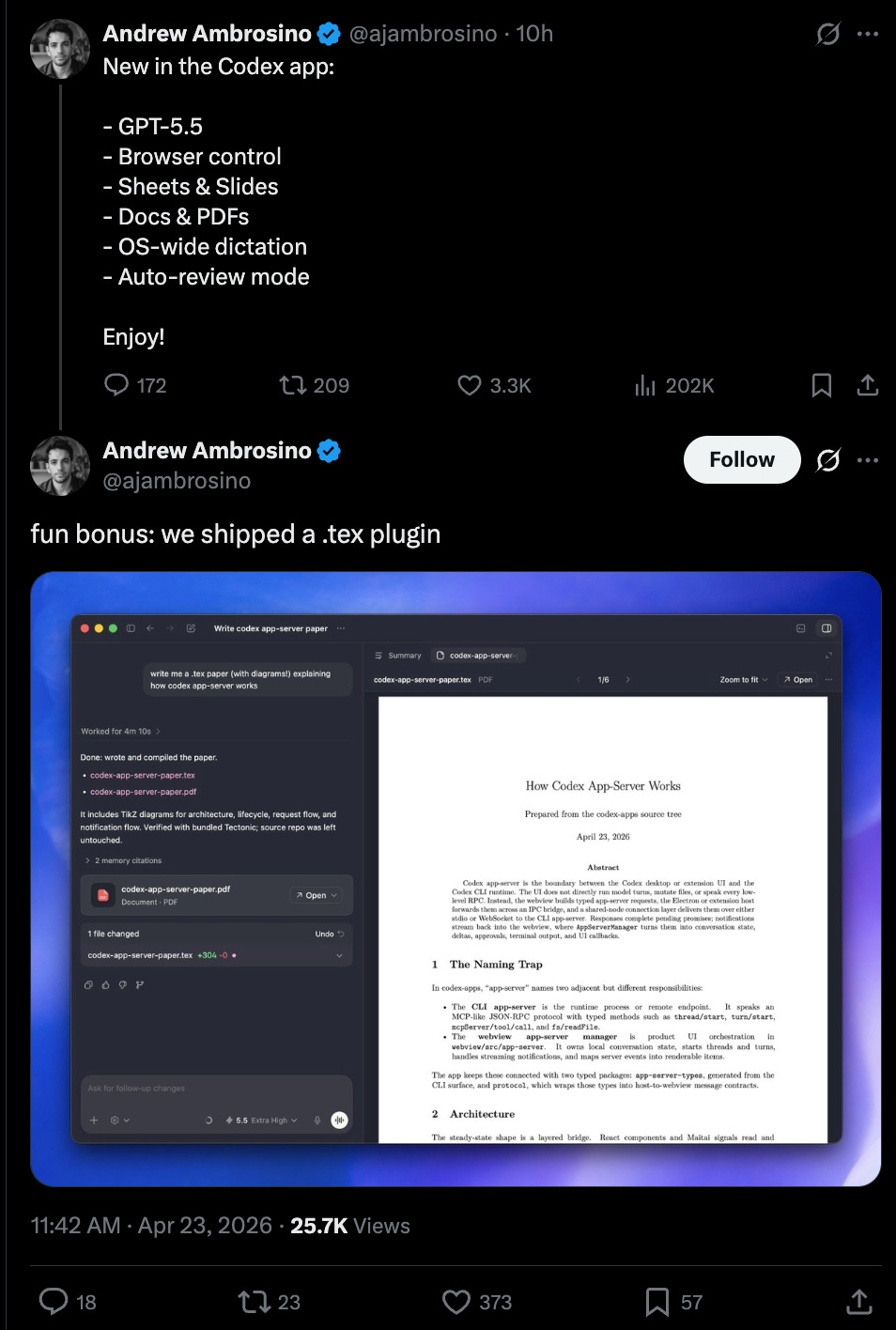
- **Codex becomes a fuller agent workspace**: In parallel, OpenAI shipped substantial Codex upgrades: **browser control**, **Sheets/Slides**, **Docs/PDFs**, **OS-wide dictation**, and **auto-review mode**@ajambrosino. OpenAI says Codex can now interact with web apps, click through flows, capture screenshots, and iterate until task completion @OpenAIDevs, while **Auto-review** uses a secondary “guardian” agent to reduce approvals on longer runs @OpenAIDevs, @gdb. User reports suggest this is expanding Codex from a coding tool into a broader **computer-work agent**, spanning QA, spreadsheets, presentations, app building, research loops, and overnight experimental runs @gdb, @tszzl, @aidan_mclau.
**DeepSeek-V4 Preview: 1.6T MIT-licensed open model, 1M context, and aggressive pricing**
- **DeepSeek answered GPT-5.5 within hours**: DeepSeek released DeepSeek-V4 Preview, open-sourcing **V4-Pro** and **V4-Flash** under an **MIT license**. The headline specs are unusually aggressive: **V4-Pro: 1.6T total params / 49B active**, **V4-Flash: 284B / 13B active**, both with **1M token context** and support for thinking/non-thinking modes @deepseek_ai, @Yuchenj_UW. Community reactions quickly framed it as the new **open-model flagship**, competitive with top closed models from the prior generation and a major leap over DeepSeek V3.x @arena, @scaling01, @kimmonismus.
- **Technical report highlights: long-context efficiency, hybrid attention, and Muon**: The launch was notable not just for weights but for a same-day tech report @scaling01. Community summaries point to **two new compressed/hybrid attention mechanisms**, **mHC**, **Muon-based training**, **FP4 quantization-aware training**, and pretraining on roughly **32T tokens**@scaling01, @iScienceLuvr, @eliebakouch. The strongest technical discussion centered on making **1M context practical**, with reported **~4x compute efficiency improvements** and **order-of-magnitude KV-cache reductions** relative to earlier DeepSeek-style stacks @Hangsiin. The rapid infra response was also notable: **vLLM** announced day-0 support and detailed how it implemented the new attention stack; **SGLang** shipped day-0 optimizations and RL pipeline support.
- **Pricing may be as important as the model**: DeepSeek’s posted pricing is exceptionally aggressive: **V4-Flash at $0.14/$0.28** and **V4-Pro at $1.74/$3.48 per 1M input/output tokens**@scaling01, @teortaxesTex. Several commenters highlighted Flash as potentially the more disruptive SKU if serving quality holds, given the combination of **very low cost**, **1M context**, and open weights @Hangsiin, @arena. The main caveat from DeepSeek: **V4-Pro throughput is currently limited by high-end compute constraints**, with the company explicitly pointing to future **Ascend 950** availability for price drops @teortaxesTex.
**Agent infrastructure and tooling: memory, orchestration, browsers, and enterprise plumbing**
- **Agents are becoming systems problems, not just model problems**: Several posts emphasized that production agent work is increasingly about **harnesses, evals, memory, and orchestration**. A useful example was the writeup on **stateless decision memory** for enterprise agents, which replaces mutable per-agent state with immutable decision logs/event sourcing to improve **horizontal scalability, auditability, and fault tolerance**@omarsar0. In a similar vein, @Vtrivedy10 argued that **trace data → evals/environments → harness engineering/SFT-RL** is the core flywheel for improving production agents, and later used Anthropic’s Claude Code regression as a case study for why **open harnesses and open evals** matter @Vtrivedy10.
- **New tooling around control surfaces**: Cua open-sourced Cua Driver, a macOS driver for letting agents control arbitrary apps in the background with multi-player/multi-cursor support. Cognition published a post on what it takes to build cloud agent infrastructure, naming the practical stack: **VM isolation, session persistence, environment provisioning, orchestration, and integrations**. LangChain continued expanding **LangSmith Fleet** with file editing, webpage/presentation generation, and slash-command skills @LangChain, while multiple users highlighted Fleet’s **presentation renderer/viewer** as a surprisingly useful agent-native artifact format @BraceSproul.
- **Multi-agent orchestration is moving into products**: Sakana AI launched the beta of **Fugu**, a multi-agent orchestration API that dynamically selects and coordinates frontier models, with claims of SOTA on **SWE-Pro, GPQA-D, and ALE-Bench** and even **recursive test-time scaling** via self-invocation @SakanaAILabs, @hardmaru. Hermes Agent shipped v0.11.0 with a large contributor release, expanded providers, image generation support, and effectively immediate GPT-5.5 support @Teknium. The direction is consistent: **agents are becoming orchestration layers over heterogeneous tools and models**, not single-model loops.
**Vision, video, and multimodal systems: Vision Banana, Sapiens2, HDR video, and omni models**
- **Google DeepMind’s Vision Banana reframes CV as generation**: One of the more technically interesting research launches was Vision Banana, a **unified vision model** that treats **2D/3D vision tasks as image generation**, reportedly outperforming specialist SOTA systems across multiple vision tasks. The reaction from computer-vision researchers was that it signals a broader shift in how segmentation, depth, normals, and related tasks may be approached going forward @sainingxie. On the open side, Meta also released **Sapiens2**, a set of high-resolution vision transformers trained on **1B human images** for human-centric perception tasks @HuggingPapers.
- **Video stack updates are moving past raw resolution into production formats**: Kling’s “native 4K” rollout spread across multiple platforms, but the technically more novel launch may be **LTX HDR beta**, which argues the real bottleneck for AI video in production has been **dynamic range**, not just resolution, by moving beyond 8-bit SDR toward footage that can survive grading and compositing @ltx_model. That’s a more substantive improvement than the usual “4K” marketing alone. Separately, World Labs launched **World Jam** around **Marble 1.1 + Spark LoD** for interactive 3D creation @theworldlabs.
- **Broader multimodal trend: unified models with explicit cross-modal reasoning**: The newly shared **Context Unrolling in Omni Models** proposes a unified model trained across text, images, video, 3D geometry, and hidden representations, explicitly unrolling reasoning across modalities before producing outputs @arankomatsuzaki. Together with Vision Banana, this points to a recurring motif: **fold disparate perception/generation tasks into fewer general multimodal backbones**, then let inference-time reasoning bridge modalities.
**Training, scaling, and research methods: globally distributed pretraining, self-play, and long-context internals**
- **Google’s Decoupled DiLoCo tackles resilient global pretraining**: Google DeepMind and Google Research introduced Decoupled DiLoCo, which decouples distributed low-communication training to enable **worldwide datacenter training**, **heterogeneous hardware**, and tolerance to hardware failures without halting the job. This is a meaningful systems result because it targets a real frontier training bottleneck: keeping giant training runs alive and efficient across **faulty, geographically distributed infrastructure**, rather than assuming clean homogeneous clusters.
- **Algorithmic scaling beyond brute-force sampling**: A self-play paper highlighted by @LukeBailey181 studies why long-run self-play plateaus for LLMs and proposes an algorithm that lets a **7B model solve as many problems as pass@4 of a model 100x larger**. Another recurring theme was **token/computation efficiency** as the real frontier metric; several posts argued that single-number intelligence comparisons are increasingly obsolete in a world where effort level and inference budget materially reshape capability @polynoamial. Relatedly, a thread on **Neural Garbage Collection** described training models to manage their own KV cache via RL rather than fixed heuristics, a potentially important direction for long-horizon agents @cwolferesearch.
- **Infra adoption signals**: Together AI reported growth from **30B to 300T tokens/month YoY**@vipulved, a large-scale indicator of inference demand expansion. Epoch AI, meanwhile, revised down estimates for operational power at **Stargate Abilene** to **~0.3 GW** currently and pushed the full **1.2 GW** milestone to **Q4 2026**, underscoring continued uncertainty in tracking frontier compute deployment @EpochAIResearch.
**Top tweets (by engagement)**
- **OpenAI GPT-5.5 launch**: The highest-engagement technical post was OpenAI’s GPT-5.5 announcement, followed by @sama’s launch post and OpenAI DevRel’s framing of GPT-5.5 as its smartest frontier model yet @OpenAIDevs.
- **Claude Code regression post-mortem**: Anthropic’s acknowledgment that Claude Code quality had slipped due to three issues and was fixed in v2.1.116+ was one of the most engaged engineering-product posts of the day, and sparked substantial discussion about harness sensitivity and regression testing.
- **DeepSeek-V4 Preview release**: DeepSeek’s official V4 Preview launch quickly became the other major high-engagement technical event, especially given the combination of **MIT license**, **1M context**, and aggressive pricing.
- **Vision Banana**: Google DeepMind’s Vision Banana announcement was the standout pure-research vision post.
- **ML-Intern and autonomous research workflows**: The Hugging Face-adjacent ml-intern passing an internship-style test in 15 minutes and subsequent reports of very high token consumption suggest strong interest in autonomous coding/research harnesses as distinct products, not just demos.