Rethinking SQL ETL for modern data platforms

- Databricks提出了一种新的SQL ETL方法来适应现代数据平台。
- 文章强调了统一的数据管理和治理的重要性。
- 虽然提到了一些新工具和实践,但缺乏具体的技术实现细节。
Rethinking SQL ETL for modern data platforms | Databricks Blog
[](http://www.databricks.com/)
[](http://www.databricks.com/)
- Why Databricks
- * Discover
- Customers
- Partners
- Product
- * Databricks Platform
- Integrations and Data
- Pricing
- Open Source
- Solutions
- * Databricks for Industries
- Cross Industry Solutions
- Migration & Deployment
- Solution Accelerators
- Resources
- * Learning
- Events
- Blog and Podcasts
- Get Help
- Dive Deep
- About
- * Company
- Careers
- Press
- Security and Trust
- DATA + AI SUMMIT 
1. All blogs 2. / Industries
Table of contents
- Run and operate SQL ETL on one platform
- Support how teams actually build SQL pipelines
- Build SQL pipelines that evolve with your workloads
- Why SQL ETL should shape your data platform strategy
- Conclusion
Table of contents
Table of contents
- Run and operate SQL ETL on one platform
- Support how teams actually build SQL pipelines
- Build SQL pipelines that evolve with your workloads
- Why SQL ETL should shape your data platform strategy
- Conclusion
IndustriesApril 29, 2026
Rethinking SQL ETL for modern data platforms
Reduce cost and complexity by unifying fragmented SQL pipelines on a single platform
by Matt Jones and Shanelle Roman
Summary
- Fragmented SQL ETL drives hidden cost, brittle pipelines, and slow incident resolution
- Running ETL across warehouses, orchestrators, and tools creates operational drag that scales with every pipeline
- A unified platform for all SQL ETL removes coordination overhead and lets teams ship faster on one governed system
SQL is the foundation of modern data work. It’s how analytics engineers define transformations, how data warehouse engineers manage pipelines, and how analysts explore and refine data.
But while SQL itself is standardized, the systems used to run SQL ETL are anything but.
In most organizations, SQL pipelines are spread across a combination of tools: a data warehouse for execution, a transformation framework for modeling, an orchestrator for scheduling, and separate systems for monitoring, lineage, and data quality. Each layer addresses a specific need, but together they create a fragmented environment that is difficult to operate and increasingly difficult to scale.
As data teams scale, this fragmentation starts to show up in day-to-day operations. Pipelines fail across multiple systems, dependencies are difficult to trace, and resolving issues often requires jumping between tools that were never designed to work together. At the same time, expectations increase. Teams are asked to deliver fresher data, support more use cases, and move faster, without adding operational overhead.
This is where many data platform strategies begin to break down. Even as organizations invest in modern infrastructure, SQL ETL often remains distributed across multiple systems, carrying forward the same complexity and constraints.
The challenge isn’t SQL itself - it’s how SQL ETL is implemented.
If SQL ETL were designed from the ground up for how teams actually work today, it would look very different. In practice, it would mean:
- A single platform for ETL
- Support for every SQL practitioner
- Open, future-ready pipelines
Together, these principles define a simpler and more durable approach to SQL ETL - one that reduces fragmentation today while supporting how data workloads evolve over time.
Run and operate SQL ETL on one platform
The challenge in SQL ETL isn’t writing transformations - it’s operating pipelines as they span multiple systems.
In practice, this means coordinating execution in the data warehouse, orchestration in a separate system, and observability layered on afterward. Keeping pipelines running requires stitching these pieces together - tracking dependencies, diagnosing failures, and managing retries across tools that don’t share context.
As pipelines grow in number and importance, this coordination becomes a significant operational burden.
A unified platform simplifies this model by bringing these capabilities together. When execution, orchestration, observability, and governance are part of the same system, pipelines become easier to manage by design. Dependencies are tracked automatically, and issues can be identified and resolved more quickly because the relevant context is available in one place.
On Databricks, SQL ETL is defined and executed within a single platform. Pipelines run with built-in orchestration, while lineage and observability are captured automatically across each stage. Data quality checks and governance controls are integrated directly into pipeline execution rather than managed through separate tools.
This approach is further strengthened by serverless infrastructure and AI-driven optimization. Performance tuning, resource management, and scaling are handled automatically, allowing teams to focus on delivering reliable data rather than operating systems.
After transitioning our Databricks pipelines to serverless compute, HP realized cloud savings of over 32% and decreased the combined runtime of jobs by 36%. The effortless infrastructure management provided by serverless made this decision an obvious and strategic choice. — Luis Alonso, Head of Data Strategy & Engineering at HP Marketing
The result is a more streamlined and dependable foundation for SQL ETL - one that reduces operational overhead while improving performance and reliability at scale.
Support how teams actually build SQL pipelines
SQL ETL is fragmented not just because of tools, but because teams don’t all build pipelines the same way.
Analytics engineers - who focus on defining business logic in SQL - often want a way to build pipelines without managing the underlying infrastructure, with testing, version control, and dependencies handled automatically. Data warehouse engineers tend to rely on SQL scripts and stored procedures, often within tightly controlled execution environments. Analysts may create transformations directly within no-code tools or lightweight SQL interfaces.
Many platforms implicitly favor one of these approaches. As organizations grow, they often introduce additional systems to support other personas, resulting in parallel environments that are difficult to standardize and maintain.
A more effective approach is to standardize the platform rather than the interface.
Databricks supports a range of SQL ETL workflows within the same environment. Teams can run existing dbt workflows directly on the platform, lift and shift warehouse-style SQL into scripts and stored procedures, accelerate BI workloads with Materialized Views in Databricks SQL, define declarative pipelines that simplify production workflows, or use no-code tools for business analysts built on the same platform. Although these approaches differ in how pipelines are authored, they share the same execution engine, governance model, and observability framework.

Expand
This consistency allows organizations to support multiple development styles without introducing fragmentation in how pipelines are run. Teams can work at the level of abstraction that fits their needs, while still benefiting from shared lineage, monitoring, and operational controls.
It also ensures that existing warehouse-style SQL scripts and newer approaches can coexist on the same foundation. Teams do not need to choose between maintaining what they have and adopting new patterns—they can do both within a single system.
Each of these workflows is reflected in a dedicated authoring experience.
1. For **data warehouse engineers** running SQL scripts and stored procedures:
**SQL Editor for Stored Procedures & Materialized Views**
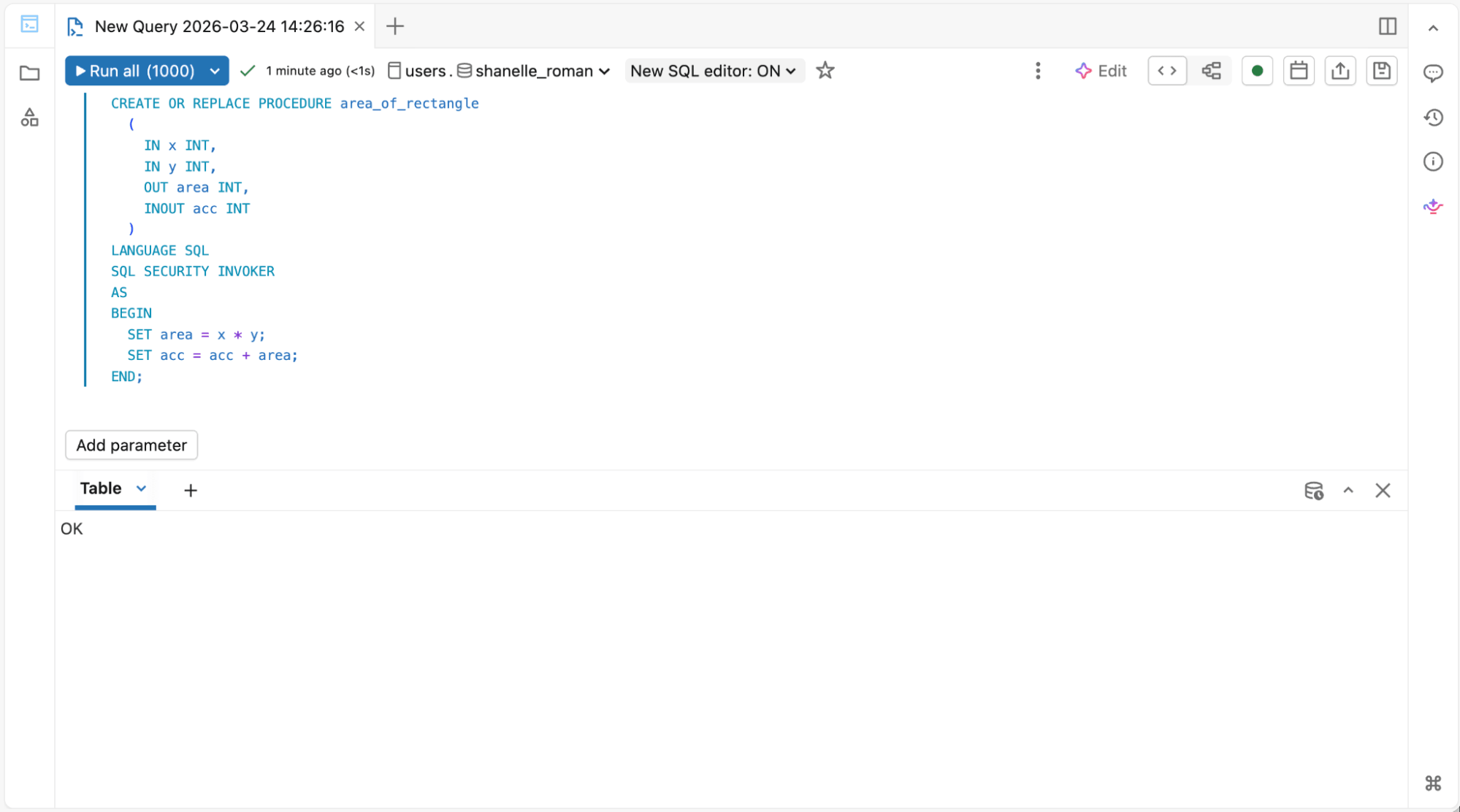
Expand
Simple SQL Editor for warehouse-style ETL
2. For **analytics engineers** building production pipelines with SQL:
**Spark Declarative Pipelines Editor**
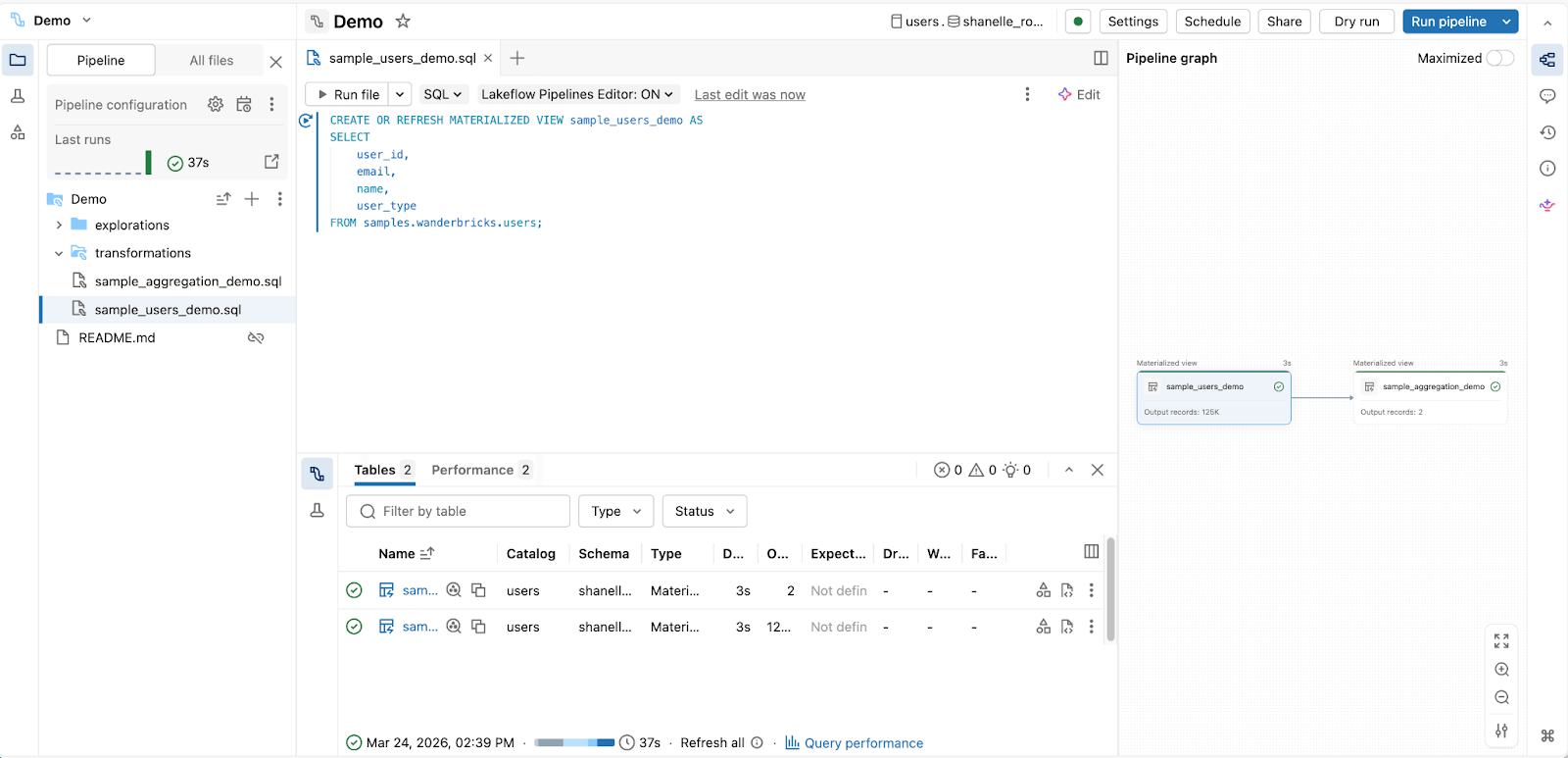
Expand
IDE purpose-built for modernized, declarative SQL ETL
3. For **analysts and business users** preparing data without code:
**Lakeflow Designer**
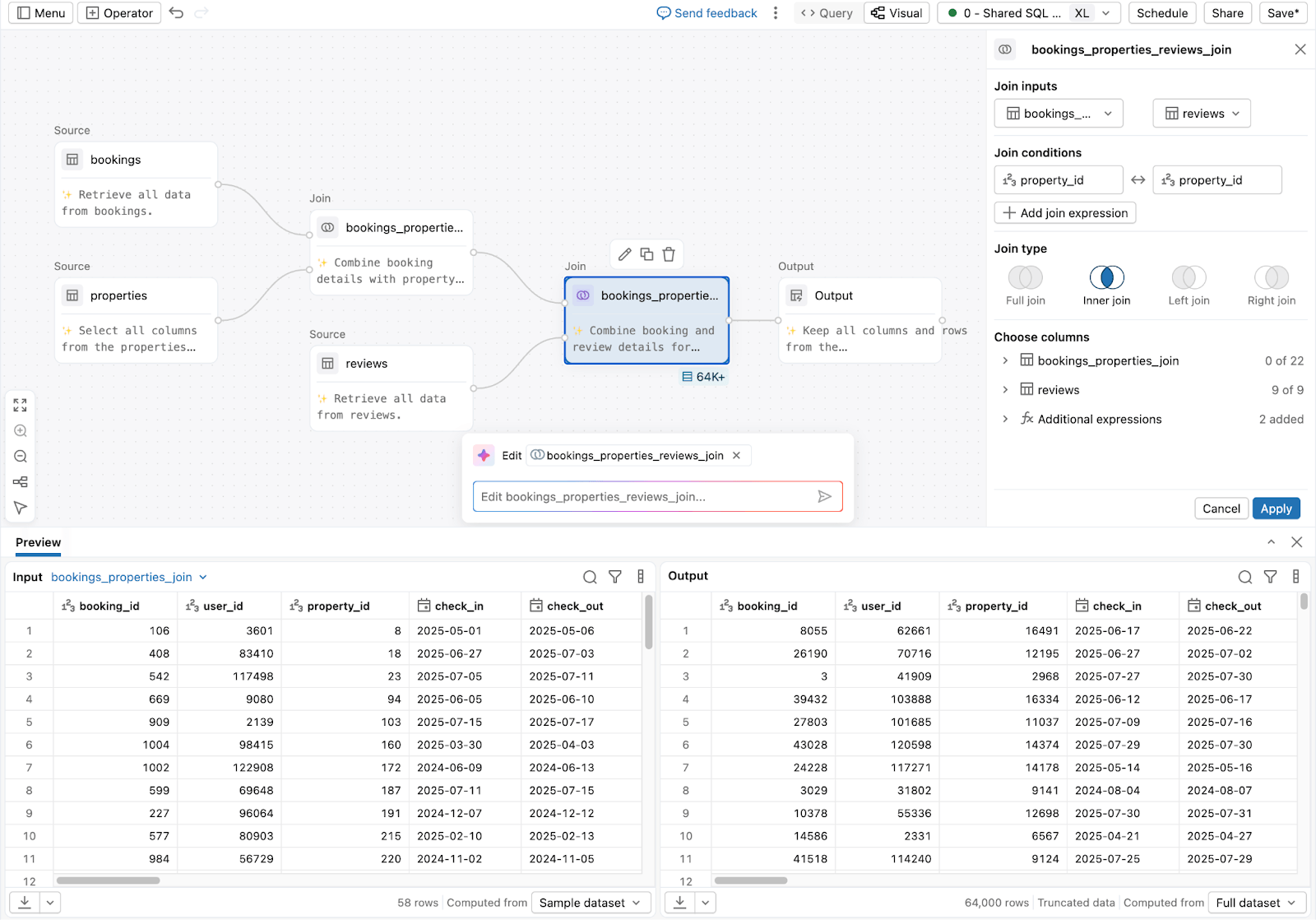
Expand
Natural language or drag-and-drop canvas for no-code data prep
The result is a more cohesive environment for SQL ETL, where collaboration improves and operational complexity does not increase with scale.
Build SQL pipelines that evolve with your workloads
As new data sources, real-time use cases, and AI workloads emerge, teams are often forced to introduce additional systems or rewrite existing pipelines - adding complexity and cost over time.
Many SQL ETL solutions introduce these constraints through proprietary formats, tightly coupled execution models, or assumptions about how data will be processed. These constraints may not be immediately apparent, but they tend to surface as organizations expand into new workloads, require fresher data, or support a broader set of use cases.
A future-ready approach to SQL ETL prioritizes openness and flexibility from the outset.
Databricks builds SQL ETL on open table formats and ANSI SQL, helping ensure that pipelines remain portable and interoperable across systems. This reduces the risk of lock-in and allows organizations to retain control over their data and logic as their architecture evolves.
At the same time, Databricks provides a unified SQL model that supports both batch and real-time analytics use cases. Rather than requiring separate systems for different workloads, the same SQL-based approach can be applied across a wide range of use cases.
This flexibility allows pipelines to evolve alongside the organization. Teams can continue to run existing SQL workflows while adopting more advanced patterns - such as incremental processing or declarative pipelines - when they are needed.
The conversion to Materialized Views has resulted in a drastic improvement in query performance, with the execution time decreasing from 8 minutes to just 3 seconds. This enables our team to work more efficiently and make quicker decisions based on the insights gained from the data. Plus, the added cost savings have really helped. — Karthik Venkatesan, Security Software Engineering Sr. Manager, Adobe
By avoiding rigid architectural constraints, this approach provides a stable foundation that can support both current requirements and future demands without requiring disruptive changes.
Why SQL ETL should shape your data platform strategy
Data platform discussions often focus on where data is stored and how queries are executed. In practice, however, the effectiveness of a platform depends just as much on how data pipelines are built and maintained, and whether they are defined in open, interoperable ways that avoid long-term lock-in.
If SQL ETL remains fragmented across multiple systems, organizations are likely to carry forward the same operational complexity and inefficiencies, even after adopting a new platform. Over time, this limits the value of the platform and makes it more difficult to scale data operations.
A more effective approach is to evaluate how well a platform supports SQL ETL across its full lifecycle - from development and execution to monitoring and governance. This includes the ability to support different working styles, reduce operational overhead, and adapt to evolving requirements without introducing additional systems.
Databricks addresses these needs by combining SQL execution, pipeline management, governance, and optimization within a single platform. This unified approach allows teams to build and operate SQL pipelines more efficiently while maintaining the flexibility to support a wide range of workloads.
Conclusion
SQL will continue to play a central role in how organizations work with data.
As a result, the way SQL ETL is implemented has a direct impact on the effectiveness of the overall data platform. Fragmented approaches introduce complexity and slow teams down, while unified approaches simplify operations and improve scalability.
For organizations evaluating how to evolve their data platforms, SQL ETL is a core consideration. Databricks provides a model for unified, future-proof SQL ETL that brings together execution, pipeline management, and governance within a single platform, while remaining open and adaptable as requirements evolve.
In practice, most organizations aren’t starting from scratch. SQL ETL modernization often stalls because the cost and risk of rewriting production pipelines are too high. Rather than forcing a disruptive rebuild, a more effective approach is to evolve incrementally - running existing pipelines first, consolidating systems over time, and modernizing step by step.
This is how teams can reduce fragmentation today while building toward a more unified, future-proof data platform over time. We’ll dive into this approach in more detail in a future post. In the meantime, you can read more about building, running, and scaling SQL pipelines on a unified lakehouse platform in this ebook, _A Guide to Building ETL Pipelines with SQL_.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.
Sign up
*
Work Email
*
Country Country*
By clicking “Subscribe” I understand that I will receive Databricks communications, and I agree to Databricks processing my personal data in accordance with its Privacy Policy.
Subscribe

Why Databricks
Discover
Customers
Partners
Why Databricks
Discover
Customers
Partners
Product
Databricks Platform
- Platform Overview
- Sharing
- Governance
- Artificial Intelligence
- Business Intelligence
- Database
- Data Management
- Data Warehousing
- Data Engineering
- Data Science
- Application Development
- Security
Pricing
Integrations and Data
Product
Databricks Platform
- Platform Overview
- Sharing
- Governance
- Artificial Intelligence
- Business Intelligence
- Database
- Data Management
- Data Warehousing
- Data Engineering
- Data Science
- Application Development
- Security
Pricing
Open Source
Integrations and Data
Solutions
Databricks For Industries
- Communications
- Financial Services
- Healthcare and Life Sciences
- Manufacturing
- Media and Entertainment
- Public Sector
- Retail
- View All
Cross Industry Solutions
Solutions
Databricks For Industries
- Communications
- Financial Services
- Healthcare and Life Sciences
- Manufacturing
- Media and Entertainment
- Public Sector
- Retail
- View All
Cross Industry Solutions
Data Migration
Professional Services
Solution Accelerators
Resources
Learning
Events
Blog and Podcasts
Resources
Documentation
Customer Support
Community
Learning
Events
Blog and Podcasts
About
Company
Careers
Press
About
Company
Careers
Press
Security and Trust

Databricks Inc.
160 Spear Street, 15th Floor
San Francisco, CA 94105
1-866-330-0121
- [](https://www.linkedin.com/company/databricks)
- [](https://www.facebook.com/pages/Databricks/560203607379694)
- [](https://twitter.com/databricks)
- [](https://www.databricks.com/feed)
- [](https://www.glassdoor.com/Overview/Working-at-Databricks-EI_IE954734.11,21.htm)
- [](https://www.youtube.com/@Databricks)
- [](https://www.linkedin.com/company/databricks)
- [](https://www.facebook.com/pages/Databricks/560203607379694)
- [](https://twitter.com/databricks)
- [](https://www.databricks.com/feed)
- [](https://www.glassdoor.com/Overview/Working-at-Databricks-EI_IE954734.11,21.htm)
- [](https://www.youtube.com/@Databricks)
© Databricks 2026. All rights reserved. Apache, Apache Spark, Spark, the Spark Logo, Apache Iceberg, Iceberg, and the Apache Iceberg logo are trademarks of the Apache Software Foundation.
- Privacy Notice
- |Terms of Use
- |Modern Slavery Statement
- |California Privacy
- |Your Privacy Choices
- !Image 14
We Care About Your Privacy
Databricks uses cookies and similar technologies to enhance site navigation, analyze site usage, personalize content and ads, and as further described in our Cookie Notice. To disable non-essential cookies, click “Reject All”. You can also manage your cookie settings by clicking “Manage Preferences.”
Manage Preferences
Reject All Accept All
Privacy Preference Center
Opt-Out Preference Signal Honored
Privacy Preference Center
- ### Your Privacy
- ### Strictly Necessary Cookies
- ### Performance Cookies
- ### Functional Cookies
- ### Targeting Cookies
- ### TOTHR
#### Your Privacy
When you visit any website, it may store or retrieve information on your browser, mostly in the form of cookies. This information might be about you, your preferences or your device and is mostly used to make the site work as you expect it to. The information does not usually directly identify you, but it can give you a more personalized web experience. Because we respect your right to privacy, you can choose not to allow some types of cookies. Click on the different category headings to find out more and change our default settings. However, blocking some types of cookies may impact your experience of the site and the services we are able to offer.
#### Opting out of sales, sharing, and targeted advertising
Depending on your location, you may have the right to opt out of the “sale” or “sharing” of your personal information or the processing of your personal information for purposes of online “targeted advertising.” You can opt out based on cookies and similar identifiers by disabling optional cookies here. To opt out based on other identifiers (such as your email address), submit a request in our Privacy Request Center.
#### Strictly Necessary Cookies
Always Active
These cookies are necessary for the website to function and cannot be switched off in our systems. They assist with essential site functionality such as setting your privacy preferences, logging in or filling in forms. You can set your browser to block or alert you about these cookies, but some parts of the site will no longer work.
#### Performance Cookies
- [x] Performance Cookies
These cookies allow us to count visits and traffic sources so we can measure and improve the performance of our site. They help us to know which pages are the most and least popular and see how visitors move around the site.
#### Functional Cookies
- [x] Functional Cookies
These cookies enable the website to provide enhanced functionality and personalization. They may be set by us or by third party providers whose services we have added to our pages. If you do not allow these cookies then some or all of these services may not function properly.
#### Targeting Cookies
- [x] Targeting Cookies
These cookies may be set through our site by our advertising partners. They may be used by those companies to build a profile of your interests and show you relevant advertisements on other sites. If you do not allow these cookies, you will experience less targeted advertising.
#### TOTHR
- [x] TOTHR
Cookie List
Consent Leg.Interest
- [x] checkbox label label
- [x] checkbox label label
- [x] checkbox label label
Clear
- - [x] checkbox label label
Apply Cancel
Confirm My Choices
Allow All

问问这篇内容
回答仅基于本篇材料Skill 包
领域模板,一键产出结构化笔记论文精读包
把一篇论文 / 技术博客精读成结构化笔记:问题、方法、实验、批判、延伸阅读。
- · TL;DR(1 段)
- · 研究问题与动机
- · 方法概览
投融资雷达包
把一条融资 / 创投新闻整理成投资人视角的雷达卡:交易要点、判断、竞争格局、风险、尽调清单。
- · 交易要点(公司 / 轮次 / 金额 / 投资人 / 估值,材料未明示则写 “未披露”)
- · 投资 thesis(这家公司为什么值得关注)
- · 竞争格局与替代方案