Cognition(@cognition_labs)
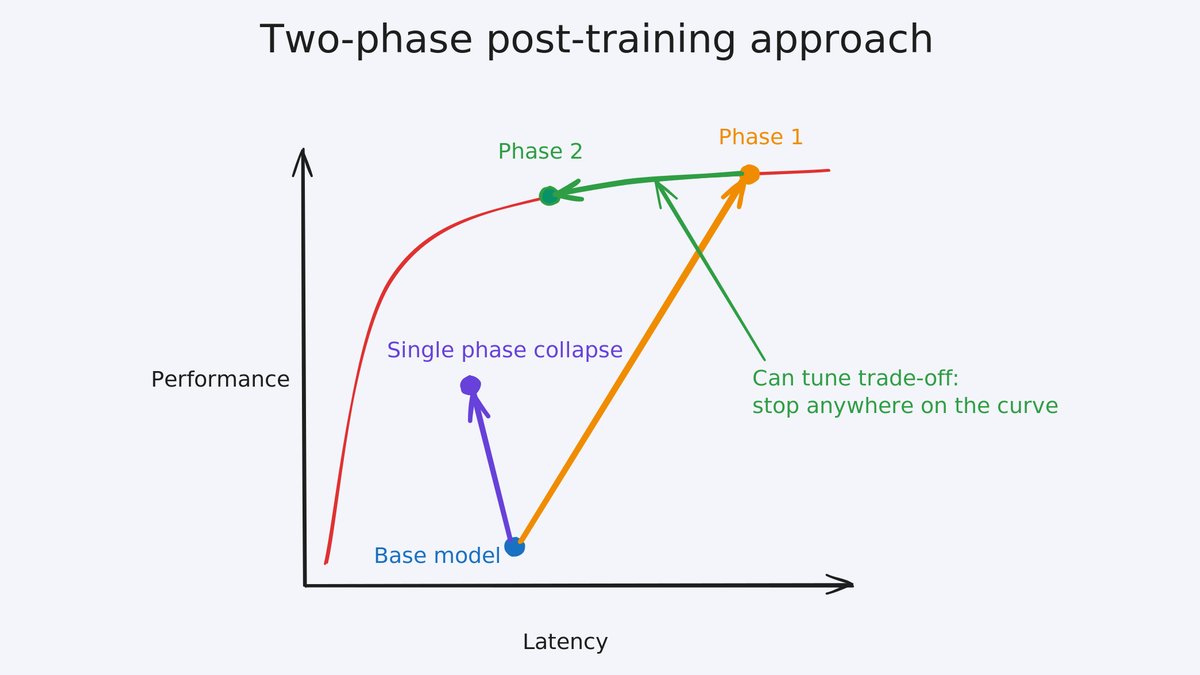
The second technique was two-phase post-training. We first trained purely for capability, then added...
7.5Score
AI 深度提炼
- 两阶段训练先提升能力再优化延迟,效果优于联合训练
- 延迟惩罚基于真实用户在SWE-check上的停留时间CDF校准
- 联合训练易使模型陷入浅层但快速的局部最优
#大模型#后训练#延迟优化#AI工程
打开原文Conversation

The second technique was two-phase post-training. We first trained purely for capability, then added a latency penalty calibrated from real dogfooding data based on the CDF of how long users stay on SWE-check before switching off. Training capability and latency jointly from the start caused the model to collapse into shallow-but-fast local optima; separating the phases let it build real bug-detection skill first and then learn to compress it.
