开放模型生态系统的复合效应

TL;DR · AI 摘要
中国开放的AI生态系统通过减少重复研发计算成本,提高了模型开发的效率和可持续性。
核心要点
- 中国AI生态系统的开放性减少了重复的研发计算成本,使实验室能够持续更长时间。
- 研究表明,80%的计算资源用于研发而非最终模型训练。
- 开放源代码AI模型的发布虽然不能立即降低成本,但有助于未来开发和部署成本的减少。
结构提纲
按章节快速跳转。
- §引言
介绍中国高参与度、开放优先的AI生态系统。
大部分计算资源用于研发而非最终模型训练。
开放性减少了重复研发计算成本,提高了可持续性。
开源AI模型的发布虽然不能立即降低成本,但有助于未来开发和部署成本的减少。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- 中国开放的AI生态系统
- 引言
- 研发计算成本
- 中国AI生态系统的成本优势
- 开源AI的挑战
金句 / Highlights
值得收藏与分享的关键句。
构建领先前沿模型的大部分计算资源来自研发成本,而不是端到端训练最终的大模型。
在一个研发计算占主导的世界中,中国的系统设计为快速从同行那里学习并避免重复花费研发计算资源或基础设施努力。
开放的AI模型、工具、基础设施等都是开发成本的降低,而不是即插即用的成本降低。
How open model ecosystems compound - by Nathan Lambert

How open model ecosystems compound
Further reflections on China's high-participation, open-first AI ecosystem.
May 12, 2026
Upgrade to paid to play voiceover
##### Note: Voice-overs for paywalled posts are available for paid subscribes in podcast apps if you click on settings on Interconnects, then manage your description. Thanks for listening!
Most of the compute to build a leading frontier model comes from R&D costs, rather than the compute to train the final, big model end-to-end. In an ecosystem like China, where all the leading players are open, this creates a potential meaningful advantage in cost structures that’ll let labs keep building longer than outside observers would expect.
There are two recent pieces of research, one from Ai2 documenting the development of Olmo 3 and one from Epoch AI studying public documentation of costs from various frontier labs, that put the estimate of compute spent on R&D rather than the final model at about 80% (with meaningful error bars).
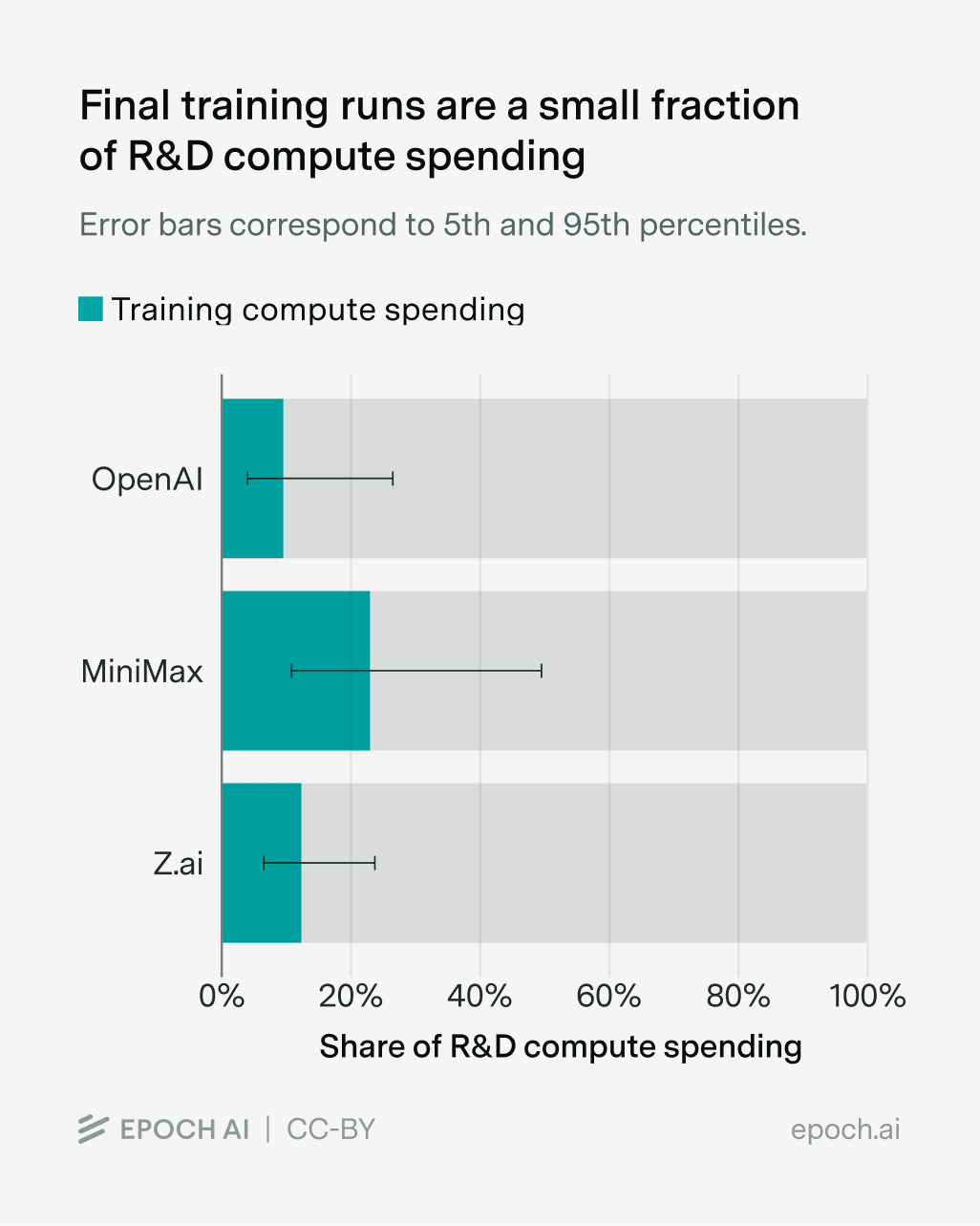
In a world where research and development is most of the compute, the Chinese system is designed around quickly learning from your peers and avoiding double-spending research compute — or infra effort. It’s far from perfect, but it’s the closest analog to the OSS ecosystem that one can get for building LLMs. The public discussion of AI has always emphasized that the _models_ are expensive in a way that naturally lets passive readers think this is compute just dedicated to the artifact — as we saw with DeepSeek V3.
This had me revisiting the core issue of open-source AI, and how it doesn’t have the feedback loops akin to open-source software (OSS) users back to the creation itself, that creates immense value following Linus’s law of “given enough eyeballs, all bugs are shallow”. This self-reinforcement of OSS makes deployment at scale the cheapest possible outcome — all the users together share the costs of fixing bugs and adding features.
Within open-source AI, almost all the cost falls on the model developer. At the same time, there are huge benefits to releasing the model openly that do reduce costs, but they only help reduce _future_ development and deployment costs for the creator themselves, but more importantly the ecosystem widely.
Open AI models, tools, infrastructure, and everything in between are a cost reduction in development, not plug and play cost reduction on apples to apples solutions or products. If someone is going to be just using AI off-the-shelf with minimal iteration or internal development, using open models will almost always be more expensive. Using closed, integrated, hosted solutions achieves low price points by economies of scale across general usage.
The open-source ecosystem can only try to mirror the OSS-style financial and performance gain in continued performance. The Chinese labs, through incredibly thorough technical reports and intentional knowledge sharing across labs effectively are de-risking ideas for their peer companies to not necessarily need to invest as many resources in.
For this to work, the current norm where AI companies _fork_ open-source tools, to evolve them into internal-only versions, will likely need to fade out. It’s too common of a trope for open-source AI companies to have their selling point being better performance via enterprise agreements or internal tools, as the fully open tools that people start with are falling behind in accessibility. A prime example is at-scale RL training of MoE models — no truly open recipe exists. It’s unclear if the open-supporting, but partially closed tools like Thinking Machine’s Tinker and Prime Intellect’s Lab can be open enough for the advantages of an open ecosystem to sustain themselves. The more open the stack is, and the more information is shared, the more costs are reduced in future iterations.
The same reasoning that causes companies to fork open-source tools to make internal versions applies to why there isn’t a shared, single foundation model that everyone builds on. Building the best model today becomes an art of integrating your hardware, data, and infrastructure, while evolving all of them at a relatively high rate that lets you keep up with the frontier of performance. Given that all signs point to LLMs continuing their steady march in performance improvements for years, it seems unlikely to expect this equilibrium to change in the near term. This is exactly why I wrote my post on the inevitable need for an open model consortium – this shared resource is far more efficient and may become the only financially viable way to compete at the future frontier scale with open models.
It’s worth noting that, of course, the closed labs also see the investigations of the open frontier model companies and can benefit from them, but with the assumption that the closed labs are some months ahead in the development tree, they often naturally stand to benefit less from the shared insights. The stronger the open-source community is, the more cost incentive there is for the various companies to be relatively close together on the same Pareto curve of performance.
This realization of the difference between _development_ costs, or a process-focused technology, rather than some shared foundation that all the labs build on directly was downstream of a question I got in feedback to my recent China trip summary. The question was: “Was there any chance of the Chinese ecosystem converging on a single base model to save costs?” The follow-up to this question was on if any of the open-weight companies in China are using open-source in strategically meaningful ways. There are many more useful questions to ask here, especially when trying to understand the different operational patterns of the ecosystems.
China’s foundation model development model
I found the following interview conducted by Bill Gurley with Dan Wang, author of Breakneck, and Patrick McGee, author of Apple in China, (both books I strongly recommend – must reads) very thought provoking on the biggest differences between technology cultures in the U.S. and China.
I get a lot of exposure to these differences at this point in my open-source AI arc. There’s a deep yearning to influence Western audiences and thinking that has bubbled up out of the Chinese AI ecosystem in the last year. This was obviously a strong pretext for why the SAIL group got such access in our recent trip – it’s not a given that anyone in the AI ecosystem will talk to senior leadership at so many companies.
This post is for paid subscribers
Already a paid subscriber? **Sign in**
Previous