How Stripe Detects Fraudulent Transactions Within 100 ms

TL;DR · AI 摘要
Stripe如何通过全新架构在100毫秒内检测欺诈交易,兼顾性能与准确性。
核心要点
- Wide & Deep架构虽有效,但XGBoost部分导致扩展性瓶颈。
- Stripe采用受ResNeXt启发的多分支神经网络解决性能问题。
- 新架构在保证99.9%准确率的同时支持更高效的实验与扩展。
Most teams pick a search provider by running a few test queries and hoping for the best – a recipe for hallucinations and unpredictable failures. This technical guide from You.com gives you access to an exact framework to evaluate AI search and retrieval.
What you’ll get:
- A four-phase framework for evaluating AI search
- How to build a golden set of queries that predicts real-world performance
- Metrics and code for measuring accuracy
Go from “looks good” to proven quality.
Every time you buy something online from a Stripe-powered business, a machine learning model evaluates over 1,000 signals about your transaction and decides in under 100 milliseconds whether to let it through.
Across billions of legitimate payments, it reaches the correct verdict 99.9% of the time. The system that delivers those numbers, however, looks entirely different from what Stripe originally built.
The architecture has been overhauled multiple times, and one of the most important upgrades required removing a component the team knew was actively improving accuracy, because keeping it was holding back everything else the team wanted to do.
For reference, online payment fraud occurs in roughly 1 out of every 1,000 transactions. That rarity makes fraud detection a difficult machine learning problem because the system has to surface a small number of fraudulent payments from a massive volume of legitimate ones, and it has to do this quickly and cheaply on every single transaction.
In this article, we will look at how Stripe’s Radar does this effectively and the architectural decisions the team took while building it.
_Disclaimer: This post is based on publicly shared details from the Stripe Engineering Team. Please comment if you notice any inaccuracies._
Stripe began with relatively simple ML models like logistic regression (a statistical method that predicts the probability of an outcome based on input variables). Over time, as the Stripe network grew and ML technology advanced, they moved to more complex architectures. Each jump produced an equivalent leap in model performance.
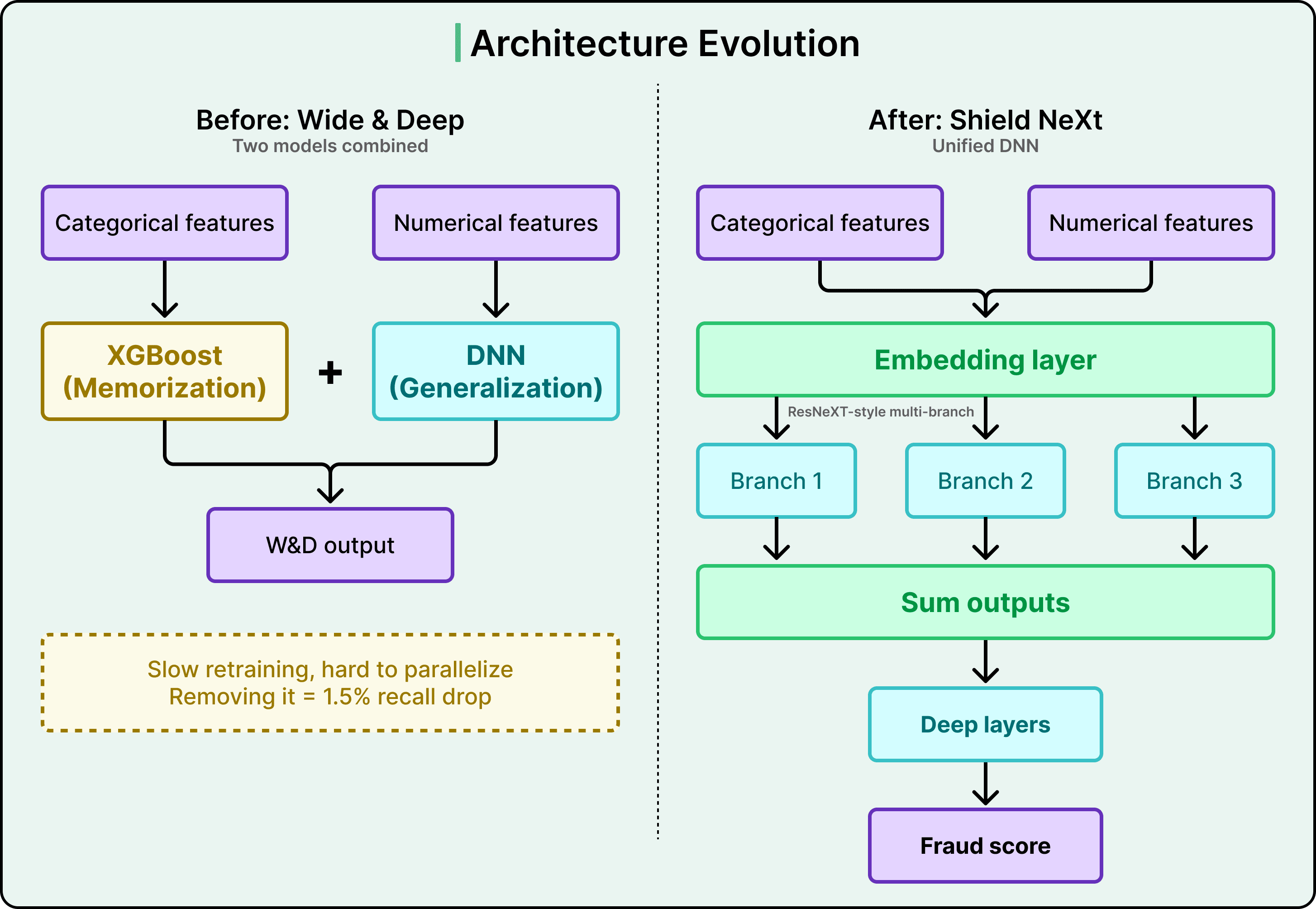
The architecture preceding the current one was called Wide & Deep. It combined two models into an ensemble.
- The “wide” component was XGBoost, a gradient-boosted decision tree that works by combining many small decision trees into one powerful predictor. XGBoost excelled at memorization, meaning it was strong at recognizing specific patterns and feature correlations it had encountered in training data.
- The “deep” component was a deep neural network (DNN) that excelled at generalization, meaning it could learn abstract concepts like “unusual payment velocity on a card” and apply them to entirely new situations it had never seen before.
Together, the two components worked well. But XGBoost was creating operational bottlenecks. It was hard to parallelize, which meant retraining the combined model was slow. It was incompatible with advanced ML techniques Stripe wanted to adopt, like transfer learning that involves using knowledge gained from one task to improve performance on a different but related task, and embeddings. And it was also limiting how quickly the many engineers working on Radar each day could experiment with new ideas.
Simply dropping XGBoost would have caused a 1.5% drop in recall, meaning 1.5% more fraud would go undetected. That was an unacceptably large regression in performance. The value XGBoost provided was real and measurable, so it had to be replicated within a new architecture rather than just discarded.
Stripe’s solution drew inspiration from a research architecture called ResNeXt.
The core idea, sometimes called “Network-in-Neuron,” splits computation into multiple distinct branches, where each branch functions as a small neural network on its own. The outputs from all branches are summed to produce a final result. This multi-branch approach enriches feature representation along a new dimension, and it achieves this more effectively than the brute-force approach of simply making a DNN wider or deeper, which risks overfitting (the model memorizing random noise rather than learning real patterns).
The resulting architecture, internally called Shield NeXt, reduced training time by over 85%, bringing it to under two hours. Experiments that previously required overnight jobs could now run multiple times in a single working day. Stripe is now exploring techniques that this architectural shift made possible, including multi-task learning, where a single model is trained to handle several related objectives simultaneously.

Agents can generate code. Getting it right for your system, team conventions, and past decisions is the hard part. You end up babysitting the agent and watch the token costs climb.
More MCPs, rules, and bigger context windows give agents access to information, but not understanding. The teams pulling ahead have a context engine to give agents only what they need for the task at hand.
Join us live (FREE) on May 6 to see:
- Where teams get stuck on the AI maturity curve and why common fixes fall short
- How a context engine solves for quality, efficiency, and cost
- Live demo: the same coding task with and without a context engine
The model architecture matters, but Radar’s biggest competitive advantage comes from the data flowing through the Stripe network. Stripe has engineered specific mechanisms to convert that scale into model performance.
90% of cards used on the Stripe network have been seen more than once across different merchants. A single business has visibility into only its own transactions. Radar, by contrast, sees patterns across millions of businesses and thousands of partner banks around the world.
There is also a structural advantage in how Radar gets its training labels, the data that tells the model which past transactions were actually fraudulent. Since Radar is built directly into Stripe’s payment flow, it receives these labels automatically when cardholders dispute charges. Most third-party fraud solutions require businesses to build separate data pipelines for sending payment labels back to the fraud provider, or to label payments manually, which is time-consuming and error-prone. Radar sidesteps all of this by ingesting ground truth data straight from the payment flow and card networks.
Stripe uses hundreds of features in its model, and most of them are aggregates computed across the entire network. As the network grows, each feature becomes more informative because the training data better represents the feature’s real-world distribution.
A “feature” in this context is a single signal the model uses to evaluate a transaction. Some are intuitive. For example, does the cardholder’s name match the provided email address? How many different cards have been associated with this IP address? A high count might indicate someone testing stolen cards. Other features are more surprising. The difference between the device’s local time and UTC, or the count of countries where a card has been successfully authorized, both turn out to be meaningful fraud signals.
Finding new features is part forensics and part experimentation. Stripe’s team reviews past fraud attacks in detail, building investigation reports that try to reconstruct how fraudsters operate. They look for patterns in throwaway email addresses used to set up multiple accounts quickly. They monitor dark web activity weekly. From this research, they build a prioritized list of candidate features, implement each one rapidly, and prototype them to measure model impact.
Sometimes the most promising ideas yield little. For example, Stripe once built a feature capturing whether a business was currently under a distributed fraud attack. It barely moved the model performance because the model was already learning that pattern implicitly.
One of the more powerful techniques Stripe uses is embeddings, which are learned numerical representations for categorical data. Things like merchant identity, issuing bank, user country, and day of the week have many possible values, and defining useful numerical representations for them is challenging.
Stripe trains its model to learn an embedding for each value, essentially a set of coordinates that position it relative to others based on transaction patterns. Uber and Lyft, for example, would end up with similar embedding coordinates because their transaction patterns resemble each other, while Slack would be positioned very differently.
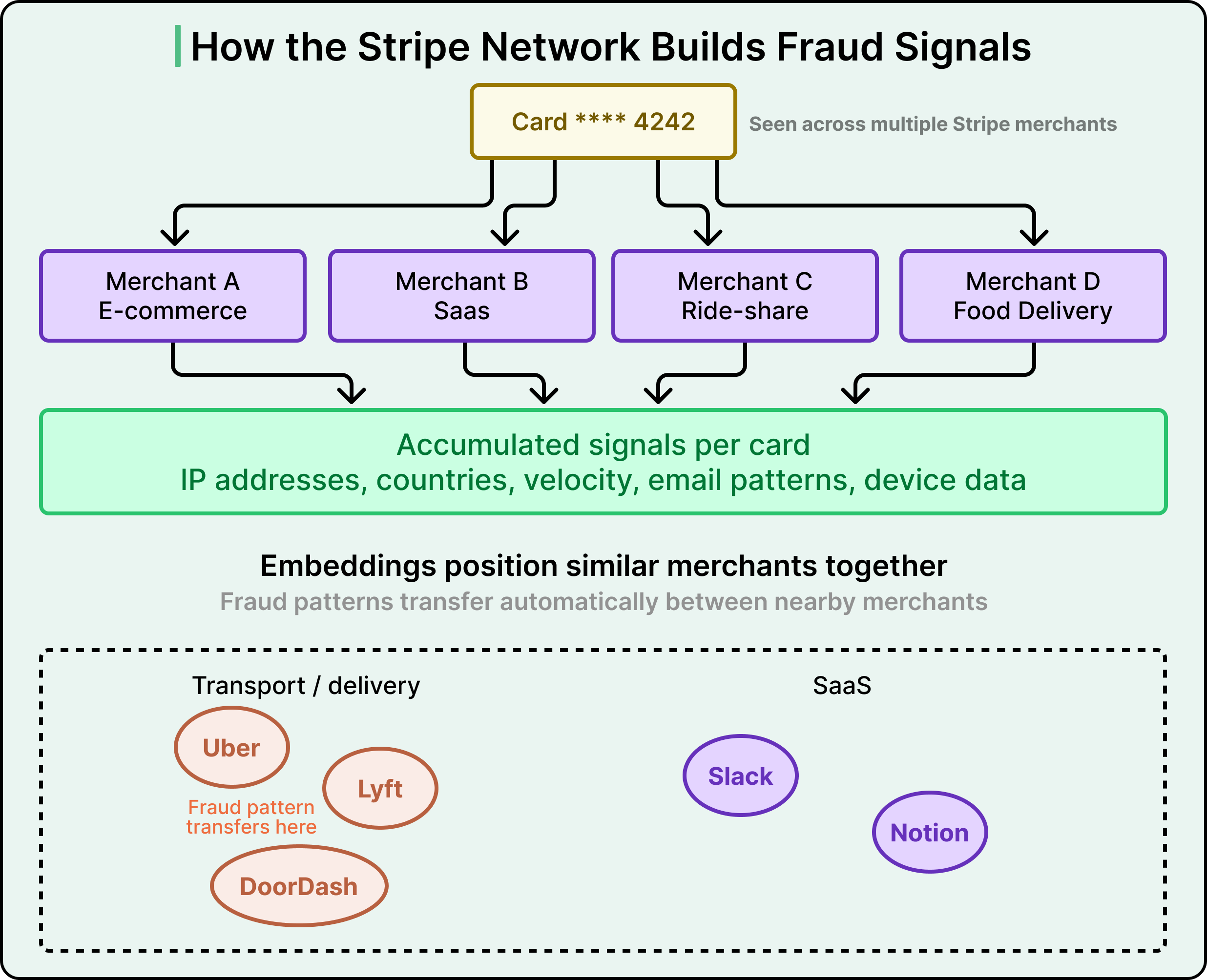
Embeddings enable geographic transfer of fraud knowledge. If Stripe identifies a new fraud pattern in Brazil, the embeddings allow the system to recognize that same pattern in the US automatically, without retraining. The model essentially learns which merchants and regions behave similarly, then applies fraud knowledge across the entire network.
Stripe also found that scaling up training data continued to yield significant gains. A 10x increase in training transaction data still produced meaningful model improvements, and the team was working on a 100x version. This kind of scaling was only feasible because the DNN-only architecture could train fast enough to handle much larger datasets practically.
Having a great model and great data still leaves a fundamental question unanswered.
How much fraud should you actually block?
Every fraud detection system faces an inherent tension between two types of errors:
- A false negative is when fraud slips through undetected, costing the business the product, a chargeback fee, and potential reputational damage with card networks.
- A false positive is when a legitimate customer gets blocked, and the business loses the sale, along with potentially the customer forever. A survey found that 33% of consumers said they would stop shopping at a business after a single false decline.
These two errors exist on a curve.
Precision measures the fraction of blocked transactions that are actually fraudulent. Recall measures the fraction of all actual fraud that gets caught. As you raise the blocking threshold, requiring a higher fraud probability before blocking a payment, precision goes up because you become more selective about what you block. But recall goes down because more marginal fraud slips through. Lowering the threshold pushes things in the opposite direction.
Stripe frames this as two distinct problems:
- The data science problem is about making the model better by adding predictive features, training on more data, and refining the architecture. A better model shifts the entire precision-recall curve upward, meaning that at any given threshold, you get better outcomes on both dimensions.
- The business problem is about choosing where on that curve to operate, and the right answer depends entirely on the economics of each merchant.
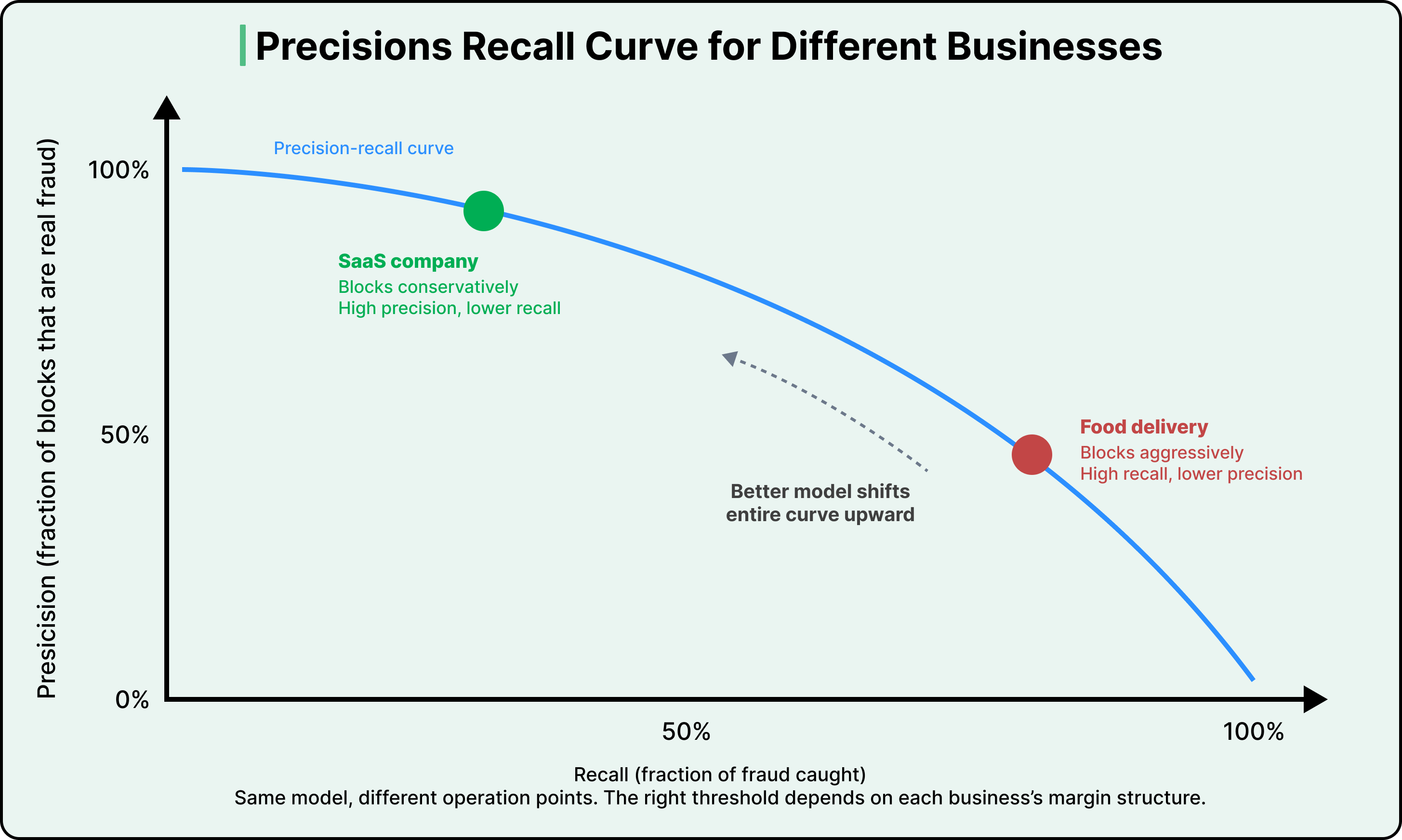
For example, consider two businesses.
A food delivery company with thin margins might earn $2 in profit per order. Once you account for product cost and chargeback fees, a single fraudulent transaction can wipe out the profit from nearly 19 legitimate ones. For this business, aggressive blocking makes sense because the cost of missed fraud is devastating. On the other hand, a SaaS company with high margins faces the opposite calculation. The lifetime revenue lost by blocking a legitimate subscriber who would have paid $200 per month for years far outweighs the cost of an occasional fraudulent charge.
This is why Stripe built Radar to be configurable.
Merchants can adjust their risk threshold, and Radar for Fraud Teams lets them compose custom rules and set up manual review queues.
Stripe evaluates custom rules with the same precision-recall framework it uses for the model itself. When a merchant creates a rule, Stripe shows historical statistics on matching transactions that were actually disputed, refunded, or accepted, so the merchant can evaluate the impact before the rule goes live. Stripe also uses additional evaluation tools like ROC curves and AUC (area under the curve) scores to assess overall model quality, but the precision-recall framing captures the core tension most directly.
Manual review adds yet another lever.
Sending borderline transactions to human reviewers instead of blocking them outright improves precision with minimal impact on recall. Also, sending borderline transactions to review instead of allowing them through improves recall with minimal impact on precision. The cost is human effort, but it gives merchants a way to reshape their own precision-recall curve using business knowledge the model cannot access on its own.
All machine learning models are opaque to some degree, and deep neural networks are especially more opaque. Stripe accepted this when they chose DNNs over simpler, more interpretable techniques. The predictions are better, but explaining why a specific transaction received a given score is harder.
Stripe’s response was to build layers of interpretability around the model.
In 2020, they launched risk insights, a feature that shows merchants which factors contributed to a transaction being declined. The interface displays the top fraud signals, like an address being associated with a previous early fraud warning or an unusually high number of names linked to a card. It includes a location map showing distances between the billing address, shipping address, and IP address. It shows customer metadata like email, cardholder name, and the authorization rate for transactions associated with that email.
See the diagram below:
Stripe also uses Elasticsearch, a search engine optimized for fast lookups across large datasets, to surface related transactions and help merchants put a specific decline in a broader context.
Internally, the team built a table view displaying the exact features contributing most to a transaction’s fraud score, which engineers use to debug support cases. Stripe is working on sharing more of these internal tools with merchants, closing the gap between what engineers can see and what users can see.
Explainability serves a practical purpose beyond building trust. When merchants understand why Radar scored a transaction the way it did, they can improve the data they send to Stripe for more accurate decisions. They can create custom rules that incorporate knowledge only they have about their own business. The explanation layer transforms Radar from a black box into something merchants can actively collaborate with.
Building a better model is half the challenge. Deploying it safely at Stripe’s scale is the other half, and it involves two hard engineering problems.
The first is real-time feature computation. Every feature the model uses during training must also be computable in production, because Radar needs to score every incoming payment as part of the Stripe API flow. For a feature like “the two most frequent IP addresses previously used with this card,” Stripe maintains an up-to-date state on every card ever seen on the network, and fetching or updating that state has to be fast. Stripe’s ML infrastructure team built systems that let engineers define features declaratively, with current values made available automatically in production at low latency.
The second is ensuring that model improvements hold across the entire user base, all the way down to individual merchants. A model that performs better on aggregate metrics might still cause a spike in block rate for smaller businesses, which would be disruptive for those merchants and their customers. Before releasing any model, Stripe measures the change it would cause to the false positive rate, block rate, and authorization rate on both an aggregate and per-merchant basis. If a model would cause undesirable shifts for certain users, they adjust it for those segments before release. They also compare score distributions between old and new models, aiming to keep the proportion of transactions above each merchant’s blocking threshold stable.
Fraud patterns shift constantly, which means even a well-performing model degrades over time, a phenomenon called model drift. Stripe found that retraining the same model on more recent data, with identical features and architecture, improves recall by up to half a percentage point per month. That is a big gain from simply keeping the data fresh. By investing in automated training, tuning, and evaluation tooling, Stripe tripled their model release cadence. They continuously update performance dashboards after training but before release, so engineers can spot stale model candidates and proactively retrain them.
The fraud landscape itself keeps evolving. Patterns have shifted from primarily stolen credit card fraud to a growing mix of traditional card fraud and high-velocity card testing attacks, where automated scripts try large numbers of stolen card numbers against a merchant’s checkout flow. Stripe’s deployment infrastructure is built to support this kind of rapid adaptation.
Stripe also faces a subtle measurement challenge in production. Transactions that the model blocks have unknown true outcomes because the payment was never completed. Computing a full production precision-recall curve requires counterfactual analysis, meaning statistical methods that estimate what would have happened to payments Radar blocked. Stripe has developed proprietary techniques for this over the years.
Radar is a very different product from what it was at launch.
The models, the data pipelines, the explainability tools, and the way Stripe communicates fraud decisions to merchants have all been rebuilt. Fraud patterns have changed considerably in that time as well.
However, the core goal of the Radar team remains the same.
They are still working to create an environment where businesses and customers can transact with confidence, still optimizing that brief moment customers barely register, the instant between clicking “purchase” and seeing the transaction confirmed. Every architectural choice, every feature, every deployment safeguard exists to make that 100-millisecond window as accurate, fair, and trustworthy as possible.
References: