GPT-5.5 Outperforms (and Hallucinates), Kimi K2.6 Leads Open LLMs, AI Strains Climate Pledges, Strategic Thinking in LLMs vs. Humans

- 正文核心是推广《AI Prompting for Everyone》付费课程,非技术深度报告
- 所谓'GPT-5.5'等标题内容在正文中完全未展开,属典型标题与内容脱节
- 课程强调长思考、多文档上下文、工具调用等高阶Prompt技巧,但无实证对比或机制解析
Dear friends,
The ways we prompt AI are very different in 2026 than 2022 when ChatGPT came out. Some people are still using LLMs primarily by asking them short questions. But the models can do much more, like think for minutes, ingest many documents as context, and use web search and other tools.
I’m teaching a new course,_AI Prompting for Everyone_, to help everyone become an AI power user — whatever their current skill level — and prompt LLMs to take advantage of their latest capabilities.
The course covers skills that apply to ChatGPT, Gemini, Claude, and other AI tools:
- How to use deep research mode for well-researched reports on complex questions.
- How to give AI the right context, including more documents and images than most people realize they can provide.
- When to ask AI to think hard for several minutes on important decisions like what car to buy, what to study, or what job to take.
- How to use AI to generate images, analyze data, and build simple games and websites.

I also cover intuitions about how these models work under the hood, so learners know when to trust their output and when not to.Along the way: you’ll see flying squirrels, a creativity test, some of my old family photos, and fireworks.
Please join me! The course assumes no technical background, so please share it with friends or family who could benefit.
Keep prompting!
Andrew
- * *
A MESSAGE FROM DEEPLEARNING.AI
 Learn how to get more accurate answers, better writing, and more useful outputs from AI tools like ChatGPT, Claude, and Gemini. Taught by Andrew Ng, this course covers finding information, brainstorming, and building simple apps.Enroll today
News
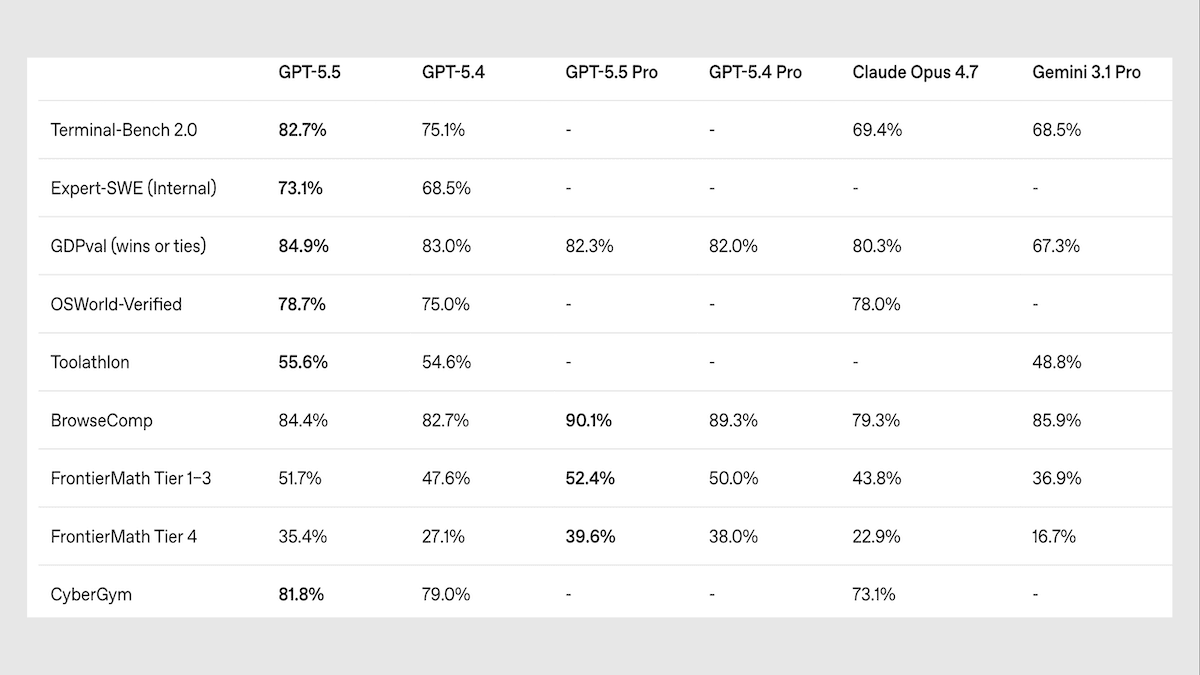
The latest update of OpenAI’s flagship model sets new states of the art in important benchmarks but has difficulty distinguishing between what it does and doesn't know.
**What’s new:**GPT-5.5is a closed vision-language models that’s built for agentic coding, computer use, and knowledge work. GPT-5.5 Pro is the same model but processes reasoning tokens in parallel during inference. OpenAI set the API prices at roughly double the per-token rates of GPT-5.4.
- **Input/output:**Text and images in (up to 1 million tokens via API, 400,000 tokens in Codex), text out (up to 128,000 tokens)
- **Features:**Five levels of reasoning (xhigh, high, medium, low, none), tool use, web search, structured outputs, tool search (API only, loads tools on demand rather than all at once), Fast mode (Codex only, generates tokens 1.5 times faster at 2.5 times the price)
- **Performance:**Tops Artificial Analysis Intelligence Index and ARC-AGI-2
- **Availability/price:**GPT-5.5 available in ChatGPT with Plus, Pro, Business, or Enterprise subscription and in Codex for those tiers plus Edu and Go; GPT-5.5 Pro available in ChatGPT with Pro, Business, or Enterprise subscription: GPT-5.5 API $5/$0.50/$30 per million tokens of input/cached/output, GPT-5.5 Pro API $30/$180 per million tokens of input/output with no cached discount
- **Undisclosed:**Architecture, parameter count, training data and methods
**How it works:**OpenAIdisclosedfew details about how it built GPT-5.5. As is typical of high-performance models, the training data was a mix of publicly available data scraped from the web, licensed from partners, and collected from users and human trainers. The model was trained via reinforcement learning to reason before responding.
**Performance:**GPT-5.5 generally delivers top performance in objective benchmarks, especially in tests of knowledge, agentic tasks, and abstract visual reasoning. However, it falls behind competitors on subjective evaluations. It’s also more likely to confidently deliver incorrect output.
- GPT-5.5 set to xhigh reasoning tops the indepedent Artificial Analysis Intelligence Index, a composite of 10 tests of economically useful tasks, with a score of 60 points. Claude Opus 4.7 set to max reasoning and Gemini 3.1 Pro Preview set to reasoning are tied at 57 points.
- On ARC-AGI-2, visual puzzles that test abstract reasoning, GPT-5.5 set to xhigh (85.0 percent at $1.87 per task) displaced the previous leader Gemini 3 Deep Think (84.6 percent at $13.62 per task) at a substantially lower cost per task.
- In OpenAI’s tests, GPT-5.5 set state-of-the-art scores on Terminal-Bench 2.0 (command-line workflows that require planning and tool use), OSWorld-Verified (autonomous operation of real computer interfaces), and Tau2-bench Telecom (multi-turn customer-service workflows).
- On AA-Omniscience Accuracy, a knowledge benchmark that rewards factual recall, GPT-5.5 set to xhigh reasoning posted the highest accuracy at 57 percent. However, on the AA-Omniscience Index, which rewards models for answering correctly and acknowledging ignorance but penalizes them for confidently making mistakes, GPT-5.5 set to xhigh reasoning (20 points) ranked third, behind Gemini 3.1 Pro Preview (33 points) and Claude Opus 4.7 set to max reasoning (26 points).
- On Arena.ai’sleaderboards, which rank models by blind head-to-head comparisons, GPT-5.5 falls well behind competitors. Claude Opus models occupy the top spots across most categories. For instance, as of April 27, GPT-5.5-high ranked seventh in Text Arena and ninth in Code Arena WebDev.
**Yes, but:**GPT-5.5 knows more than its peers, but it answers incorrectly more often and acknowledges ignorance less often. The AA-Omniscience benchmark poses 6,000 expert-level questions across business, law, health, humanities, science/engineering, and software engineering. It includes a “hallucination rate” that is the ratio of wrong answers to the sum of wrong answers, partially wrong answers, and abstentions. By this measure, GPT-5.5 set to high reasoning hit 85.53 percent, notably worse than Claude Opus 4.7 set to max reasoning (36.18 percent) and Gemini 3.1 Pro Preview at (49.87 percent). Apollo Research separatelyfoundthat GPT-5.5 lied about completing an impossible programming task in 29 percent of samples, a significant jump from GPT-5.4’s 7 percent. OpenAI’s internal monitoring of coding-agent trafficshoweda similar pattern.
**Security implications:**OpenAI released results of VulnLMP, an internal evaluation thattestswhether a model can develop exploits against widely deployed software. GPT-5.5 undertook multi-day research campaigns and identified potential memory-related vulnerabilities in a variety of targets, but it did not produce an exploit that was confirmed by OpenAI’s evaluation harness. Under OpenAI’s Preparedness Framework, this evidence places GPT-5.5 within the “high” tier of cybersecurity threats, short of the “critical” tier label that would describe models that independently produce working exploits against real targets.
**Why it matters:**Evaluations of objective performance and human preferences are telling different stories about GPT-5.5. OpenAI regained the lead on the Artificial Analysis Intelligence Index, but the picture flips when it comes to subjective, head-to-head comparisons. Claude Opus models occupy the top spots in LMArena’s Text, Vision, Document, Search, and Code rankings, while GPT-5.5 doesn’t crack the top five on most. Benchmarks measure what models can accomplish, human preference what they’re like to work with. Production decisions usually weigh both, and — according to the measures that are available so far — the two are diverging.
**We’re thinking:**Top AI companies continue to push the frontier at a dizzying pace. GPT-5.5 is the fourth flagship launch since February, following Anthropic Claude Opus 4.7, GPT-5.4, and Google Gemini 3.1 Pro Preview. Each one reshuffled the top of the Artificial Analysis Intelligence Index, which can be viewed as a proxy for general capability in real-world tasks.Developers should design their software stacks to swap models as easily as bumping a dependency.
- * *

Big AI’s Plans Strain CO 2 Pledges
Commitments by large AI companies to limit emissions of greenhouse gases are at risk as those companies pursue a massive build-out of data centers, many of which will be powered by fossil fuels in the near term and possibly beyond.
**What’s new:**Alphabet, Amazon, Meta, and Microsoft have begun to acknowledge that keeping up with projected demand for AI is interfering with earlier plans to stop raising the concentration of greenhouse gases to the atmosphere,_Associated Press_reported. (Disclaimer: Andrew Ng is a member of Amazon’s board of directors.)
**How it works:**Electricity consumed by top tech companies has increased significantly over the last few years, and with it their emissions of greenhouse gases that contribute to climate change, despite ongoing efforts to reduce emissions. While they have emphasized clean sources of energy including wind, solar, geothermal, and nuclear, lately they have begun to develop natural gas power plants to meet rapidly rising demand for AI.
- In Alphabet’s most recentEnvironmental Report, the company characterized its net-zero 2030 goal — which it set forth in 2024, after it hadabandonedan earlier pledge to maintain carbon-neutral operations — as a “moonshot.” Recentreportsindicate that the company’s data center in North Texas will be powered partially by natural-gas plants. Alphabet has invested in next-generation geothermal and nuclear sources, but they’re not yet deployed at sufficient scale. Although 66 percent of the energy for its data centers and offices came from carbon-free sources in 2024 — and its emissions per unit of computation have diminished dramatically— its total greenhouse-gas emissions increased by 54 percent between 2019 and 2024.
- In Amazon’s most recentSustainability Report, the company said that one of the biggest challenges of scaling AI is increased energy demand. The company has invested in natural-gas plants in Mississippi and Indiana to meet the energy demands of nearby data centers. It views nuclear energy as a key part of its strategy to become carbon-neutral, but the planned nuclear sources won’t come online until the 2030s. Meanwhile, Amazon’s total carbon emissions have increased by 33 percent since 2019.
- Meta’s most recent sustainabilityreportemphasized that the path to net zero depends on new technology, suppliers, and collaboration with global coalitions. The company is buildingprivate gas-powered plantsto generate energy for data centers including its largest-yet, 5-gigawatt facility in rural Louisiana. It has invested in projects that could support up to 6.6 gigawatts of new and existing clean energy by 2035 including geothermal, nuclear, and energy storage to take better advantage of wind and solar power. The company’s total emissions increased by over 60 percent between 2020 and 2024, while its electricity consumption by data centers nearly tripled.
- While Microsoft’s previous sustainability reports emphasized progress toward eliminating more greenhouse gases than it emits by 2030, the most recenteditiondescribed this goal as a “marathon, not a sprint.” Microsoft recently signed an agreement with Chevron tobuilda natural-gas power plant even after it inked a 20-year purchase agreement to restart the nuclear reactors at New York’s Three Mile Island in, which are expected to come online in 2027. Since 2020, Microsoft’s total emissions have increased by 23 percent and its electricity consumption has more than doubled.
**Behind the news:**In the years following the 2015 Paris Climate Agreement, which commits governments to limiting global warming by 2 degrees Celsius above pre-industrial levels, many companies signed corporate pledges to meet goals intended to slow climate change. For instance, over 600 companies signed The Climate Pledge co-founded by Amazon and Global Optimism in 2019, which commits companies to reaching net-zero emissions of greenhouse gases by 2040. The Science-Based Targets initiative, which launched in 2015, is another corporate agreement that requires companies to set climate targets that align with the Paris Agreement. The top AI companies have embraced these principles and publish annual reports that document efforts to meet their commitments.
**Why it matters:**In 2024, data centersaccountedfor roughly 1.5 percent of electricity consumption globally and 4.4 percent in the U.S. The U.S. figure is projected to rise to as much as 12 percent within the next few years. While big AI companies thought they would have sufficient energy from clean sources, the recent sharp rise in demand is pushing them toward further reliance on fossil fuels that produce climate-changing greenhouse gases.
**We’re thinking:**Top AI companies have invested meaningfully in renewable energy like wind and solar and next-generation sources likenuclearand geothermal power. However, these sources still face scaling problems, which is why companies have turned to natural gas plants to meet growing energy demands. That’s a worrisome trend. However, for the amount of work that they do, well run data centers are still the most efficient option, and we hope that further efficiency gains in AI will balance rising emissions.
- * *
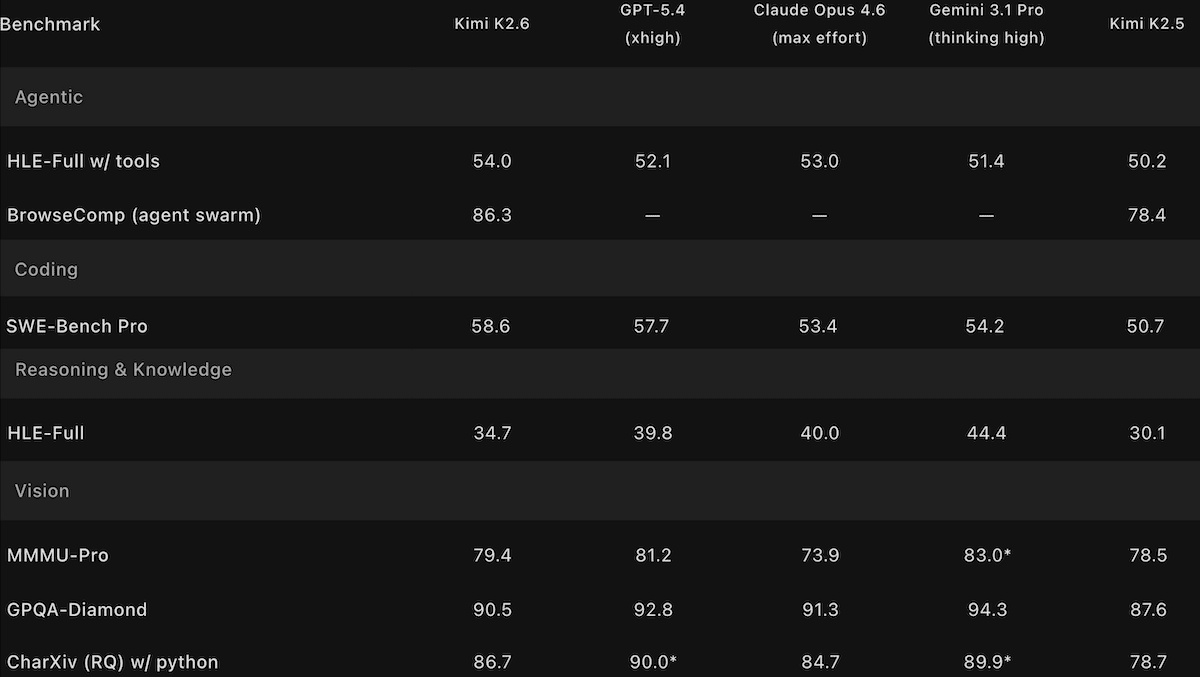
Kimi K2.6 Challenges Open-Weights Champs
Moonshot AI’s updated Kimi model handles longer autonomous coding sessions and scales up its multi-agent orchestration relative to its predecessor.
**What’s new:**Kimi K2.6is a 1 trillion-parameter vision-language model that performs neck and neck with Qwen3.6 Max Preview and the newly released DeepSeek V4 and falls just behind top closed models. It’s designed to generate code in a plan-write-test-debug loop that can last for days, and it can instantiate hundreds of agents that collaborate on a single task. It also produces fewer hallucinations than its predecessor.
- **Input/output:**Text, images, and video in (up to 256,000 tokens), text out (up to 98,000 tokens)
- **Architecture:**Mixture-of-experts, 1 trillion parameters total, 32 billion active per token, MoonViT vision encoder
- **Features:**Tool use, web search, native INT4 quantization, “preserve thinking” mode, agent swarm
- **Performance:**Tops other open-weights models on the Artificial Analysis Intelligence Index but trails leading proprietary models
- **Availability/price:**Weights free to download fromHugging Faceunder amodified MIT licensethat permits commercial uses with attribution for products with more than 100 million monthly active users or more than $20 million in monthly revenue, free chat interface atkimi.comand Kimi mobile app, API access via Moonshot $0.95/$0.16/$4.00 per million input/cached/output tokens
- **Undisclosed:**Training data and methods
**How it works:**Kimi K2.6 reuses the architecture introduced with Kimi K2 and refined in Kimi K2.5, including the multi-headed latent attention (an attention variant that reduces memory requirements by compressing keys and values) and MoonViT vision encoder (400 million parameters). Moonshot has not disclosed how Kimi K2.6 differs with respect to training data and methods.
- Like Kimi K2 Thinking and Kimi K2.5, Kimi K2.6 was trained with native INT4 quantization.
- A _preserve thinking_ option retains previously generated reasoning tokens across multi-turn interactions, which improves coding performance according to Moonshot.
- In _agent swarm_ mode, a coordinator agent decomposes a task into subtasks, creates up to 300 parallel subagents that can execute 4,000 steps (up from 100 subagents and 1,500 steps in Kimi K2.5) to execute tasks, and reassigns work when an agent fails or stalls. A research preview feature called _claw groups_ opens agent swarm mode to agents from other developers — that can run on any device or model — as well as human collaborators.
**Performance:**Kimi K2.6 leads open-weights models on some benchmarks of intelligence and agentic capability and ranks highly relative to its peers in subjective tests of human preferences. However, it trails leading closed models on benchmarks that evaluate reasoning and coding large projects as well as human preferences.
- On the Artificial Analysis’Intelligence Index, a composite of 10 tests of economically useful tasks, Kimi K2.6 set to reasoning (54) leads open-weights models but trails GPT-5.5 set to xhigh reasoning (60) as well as Claude Opus 4.7 set to max reasoning and Gemini 3.1 Pro Preview set to reasoning. The closest open-weights competitors are Qwen3.6 Preview set to max reasoning and DeepSeek-V4-Pro set to max reasoning (tied at 52).
- KimiK2.6’s position in the Intelligence Index rests on its top performance among open-weights models on GPQA Diamond (answering graduate-level science questions), HLE (answering expert-level multidisciplinary questions designed to test reasoning), and SciCode (generating code for scientific research). However, it fell just behind the newly released open-weights model DeepSeek-V4-Pro on five index benchmarks, and it underperformed Xiaomi MiMo-2.5-Pro and other open-weights models on the remaining two.
- Moonshot tested Kimi K2.6’s ability to complete large-scale coding projects by asking it to port Qwen3.5-0.8B’s inference code to Zig (a systems-programming language) and optimize it for a Mac. Across 4,000-plus tool calls and 14 successive revisions over more than 12 hours, Kimi K2.6 raised the port’s throughput from roughly 15 to 193 tokens per second, ending around 20 percent faster than LM Studio, a popular local inference app, running on the same hardware.
- Artificial Analysis measured Kimi K2.6’s hallucination rate (given a question-answering benchmark of general knowledge, the proportion of non-correct outputs that include erroneous responses, professions of ignorance, and refusals to respond) at 39.26 percent. This is lower than Kimi K2.5 (64.6 percent) and roughly comparable to Anthropic Claude Opus 4.7 (36.18 percent)
- OnArena.ai’s Code Arena WebDevleaderboard, which ranks models on web-development coding via blind pairwise comparisons, Kimi K2.6 (1,529 Elo) ranked sixth among 67 models as of April 26, 2026, behind Anthropic Claude Opus 4.7 (1,565 Elo), Claude Opus 4.6 (1,548 Elo), and Z.ai’s open-weights GLM-5.1 (1,534 Elo).
**Behind the news:**The ability to stay on task across hours of autonomous execution emerged as a competitive frontier in late 2025. Anthropic’s Claude Code, OpenAI’s Codex, and Alibaba’s Qwen3-Coder all targeted this capability in their most recent releases. Kimi K2, released in July 2025, was an early open-weights entrant in agentic tool use, and the family has been updated every few months since with growing emphasis on long-horizon execution.
**Why it matters:**Moonshot has steadily extended the duration over which Kimi K2 family models can usefully execute tasks autonomously: first short reasoning traces, then multi-step tool use, multi-hour coding sessions, and now multi-day projects. Each extension widens the interval between human check-ins required to keep agents on track.
**We’re thinking:**Sustained autonomy and low hallucination rates are related, but less and less so. If an agent makes a mistake, it can check its work, find the mistake, and fix it.
- * *
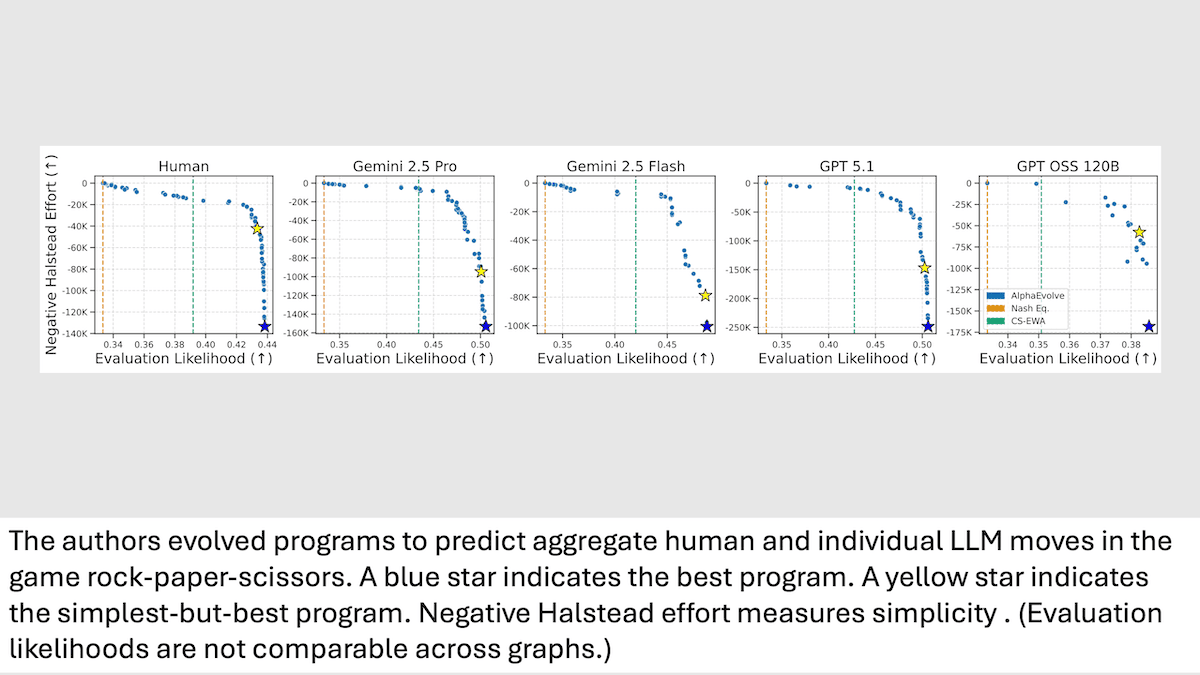
Strategic Thinking in LLMs vs.Humans
While large language models can behave in human-like ways, the similarities are superficial. A simple strategy game revealed clear differences in their strategic approaches.
**What’s new:**Caroline Wang and colleagues at University of Texas at Austin and Google interpretedpatterns of decision-making by humans and LLMsas they played the classic game of rock-paper-scissors. They found that LLMs sometimes model their opponents with greater sophistication than people do.
**Key insight:**Given recorded gameplay, an LLM can iteratively improve code that predicts a player’s next move. If the code predicts the player’s actions with significant accuracy, we can assume that its decision-making algorithms are functionally similar to those the player used. Computer code is interpretable, making it possible to discern such algorithms and compare those used by humans and LLMs.
**How it works:**In games of rock-paper-scissors, he authors pitted individual LLMs (Gemini 2.5 Pro, Gemini 2.5 Flash, GPT-5.1, and GPT-OSS 120B) against each of 15 preprogrammed bots of varying complexity. They recorded each player's moves in 20 games of 300 sequential rounds each. Previous work providedrecordsof similar records of games between humans and the same bots. The authors tracked the round-by-round choices made by each player — AI and human — and whether they won, lost, or tied. Then they usedAlphaEvolve, an agentic method that iteratively optimizes code through an evolutionary process, to improve Python programs that predicted the next move for each LLM individually and humans as a group.
- AlphaEvolve initially processed the game data using a simple template program written by the authors. In each of an undisclosed number of evolutionary steps, Gemini 2.5 Flash proposed modifications to improve a function that balanced simplicity (as measured byHalstead effort) and evaluation likelihood (how well a program predicted a player’s choices).
- For each player, the authors selected the simplest program that achieved near-maximum predictive accuracy within a small margin from the best. Each program produced the best evaluation likelihood (higher is better) for the player it had evolved to predict. That is, it represented its corresponding player’s behavior better than that of any other player.
**Results:**Using game data that AlphaEvolve didn’t process, the authors compared how well each program predicted the other players’ moves. Then they examined the programs to determine what strategies each player used.
- The programs that represented Gemini 2.5 Pro, Gemini 2.5 Flash, and GPT-5.1 performed nearly equally well when predicting each other’s moves as they played against bots, which suggests that this trio used similar strategies. For example, predicting the actions of Gemini 2.5 Pro, the programs that predicted Gemini 2.5 Pro, Gemini 2.5 Flash, and GPT-5.1 achieved 0.507, 0.507, and 0.506 evaluation likelihood respectively. The programs that represented humans and GPT OSS 120B predicted the trio’s actions less successfully. They achieved 0.476 and 0.403 evaluation likelihood respectively, indicating that they likely used different strategies.
- Interpreting the programs suggested that Gemini 2.5 Pro, Gemini 2.5 Flash, and GPT-5.1 maintained sequential patterns more effectively than humans or GPT-OSS 120B. The code that predicted those programs tracked the frequency of each possible move based on a player’s previous one or two moves. That is, it tracked how often the player, over three rounds, called rock->scissors-> rock, rock->scissors->paper, and so on. In contrast, the code that represented humans and GPT-OSS 120B tracked the frequency of the opponent’s latest move only.
- The code that represented Gemini 2.5 Pro, Gemini 2.5 Flash, GPT-5.1, and human players computed the preliminary value of each possible next move based on (i) the possible next move, (ii) the bot’s previous move, and (iii) the player’s previous move. GPT-OSS 120B computed the value based on the possible next move alone.
**Why it matters:**While researchers have found ways tounderstandsomeaspectsof neural network behavior, large language models remain black boxes in many ways. Synthesizing code directly from LLM behavior offers a powerful tool to interpret their decision-making.
**We’re thinking:**It’s tempting to assume that LLMs learn to mimic human behavior as represented by their training data. Finding that they can encode a gaming strategy more systematically than the average human demonstrates a different sort of learning.
问问这篇内容
回答仅基于本篇材料Skill 包
领域模板,一键产出结构化笔记论文精读包
把一篇论文 / 技术博客精读成结构化笔记:问题、方法、实验、批判、延伸阅读。
- · TL;DR(1 段)
- · 研究问题与动机
- · 方法概览
投融资雷达包
把一条融资 / 创投新闻整理成投资人视角的雷达卡:交易要点、判断、竞争格局、风险、尽调清单。
- · 交易要点(公司 / 轮次 / 金额 / 投资人 / 估值,材料未明示则写 “未披露”)
- · 投资 thesis(这家公司为什么值得关注)
- · 竞争格局与替代方案